 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Knowledge Distillation Using Fine-tuned Function Vectors
Jan 13, 2026Representing relations between concepts is a core prerequisite for intelligent systems to make sense of the world. Recent work using causal mediation analysis has shown that a small set of attention heads encodes task representation in in-context learning, captured in a compact representation known as the function vector. We show that fine-tuning function vectors with only a small set of examples (about 20 word pairs) yields better performance on relation-based word-completion tasks than using the original vectors derived from causal mediation analysis. These improvements hold for both small and large language models. Moreover, the fine-tuned function vectors yield improved decoding performance for relation words and show stronger alignment with human similarity judgments of semantic relations. Next, we introduce the composite function vector - a weighted combination of fine-tuned function vectors - to extract relational knowledge and support analogical reasoning. At inference time, inserting this composite vector into LLM activations markedly enhances performance on challenging analogy problems drawn from cognitive science and SAT benchmarks. Our results highlight the potential of activation patching as a controllable mechanism for encoding and manipulating relational knowledge, advancing both the interpretability and reasoning capabilities of large language models.
Few-Shot Learning of Visual Compositional Concepts through Probabilistic Schema Induction
May 14, 2025



The ability to learn new visual concepts from limited examples is a hallmark of human cognition. While traditional category learning models represent each example as an unstructured feature vector, compositional concept learning is thought to depend on (1) structured representations of examples (e.g., directed graphs consisting of objects and their relations) and (2) the identification of shared relational structure across examples through analogical mapping. Here, we introduce Probabilistic Schema Induction (PSI), a prototype model that employs deep learning to perform analogical mapping over structured representations of only a handful of examples, forming a compositional concept called a schema. In doing so, PSI relies on a novel conception of similarity that weighs object-level similarity and relational similarity, as well as a mechanism for amplifying relations relevant to classification, analogous to selective attention parameters in traditional models. We show that PSI produces human-like learning performance and outperforms two controls: a prototype model that uses unstructured feature vectors extracted from a deep learning model, and a variant of PSI with weaker structured representations. Notably, we find that PSI's human-like performance is driven by an adaptive strategy that increases relational similarity over object-level similarity and upweights the contribution of relations that distinguish classes. These findings suggest that structured representations and analogical mapping are critical to modeling rapid human-like learning of compositional visual concepts, and demonstrate how deep learning can be leveraged to create psychological models.
Evaluating Compositional Scene Understanding in Multimodal Generative Models
Mar 29, 2025



The visual world is fundamentally compositional. Visual scenes are defined by the composition of objects and their relations. Hence, it is essential for computer vision systems to reflect and exploit this compositionality to achieve robust and generalizable scene understanding. While major strides have been made toward the development of general-purpose, multimodal generative models, including both text-to-image models and multimodal vision-language models, it remains unclear whether these systems are capable of accurately generating and interpreting scenes involving the composition of multiple objects and relations. In this work, we present an evaluation of the compositional visual processing capabilities in the current generation of text-to-image (DALL-E 3) and multimodal vision-language models (GPT-4V, GPT-4o, Claude Sonnet 3.5, QWEN2-VL-72B, and InternVL2.5-38B), and compare the performance of these systems to human participants. The results suggest that these systems display some ability to solve compositional and relational tasks, showing notable improvements over the previous generation of multimodal models, but with performance nevertheless well below the level of human participants, particularly for more complex scenes involving many ($>5$) objects and multiple relations. These results highlight the need for further progress toward compositional understanding of visual scenes.
Evidence from counterfactual tasks supports emergent analogical reasoning in large language models
Apr 29, 2024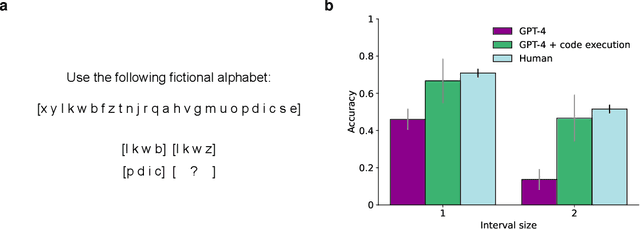
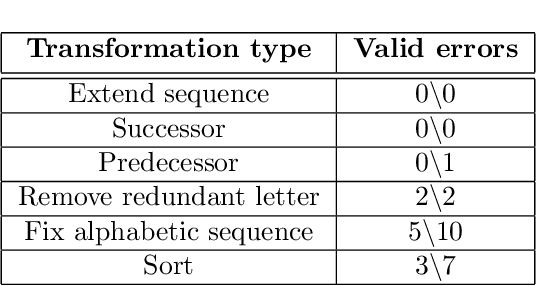
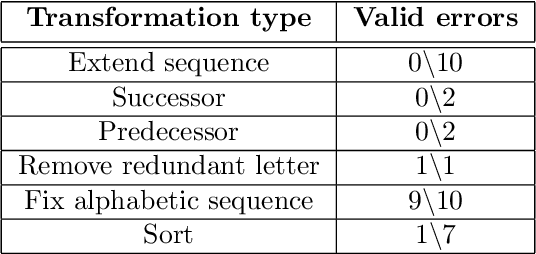
We recently reported evidence that large language models are capable of solving a wide range of text-based analogy problems in a zero-shot manner, indicating the presence of an emergent capacity for analogical reasoning. Two recent commentaries have challenged these results, citing evidence from so-called `counterfactual' tasks in which the standard sequence of the alphabet is arbitrarily permuted so as to decrease similarity with materials that may have been present in the language model's training data. Here, we reply to these critiques, clarifying some misunderstandings about the test materials used in our original work, and presenting evidence that language models are also capable of generalizing to these new counterfactual task variants.
Emergent Analogical Reasoning in Large Language Models
Dec 19, 2022The recent advent of large language models - large neural networks trained on a simple predictive objective over a massive corpus of natural language - has reinvigorated debate over whether human cognitive capacities might emerge in such generic models given sufficient training data. Of particular interest is the ability of these models to reason about novel problems zero-shot, without any direct training on those problems. In human cognition, this capacity is closely tied to an ability to reason by analogy. Here, we performed a direct comparison between human reasoners and a large language model (GPT-3) on a range of analogical tasks, including a novel text-based matrix reasoning task closely modeled on Raven's Progressive Matrices. We found that GPT-3 displayed a surprisingly strong capacity for abstract pattern induction, matching or even surpassing human capabilities in most settings. Our results indicate that large language models such as GPT-3 have acquired an emergent ability to find zero-shot solutions to a broad range of analogy problems.
Zero-shot visual reasoning through probabilistic analogical mapping
Sep 29, 2022
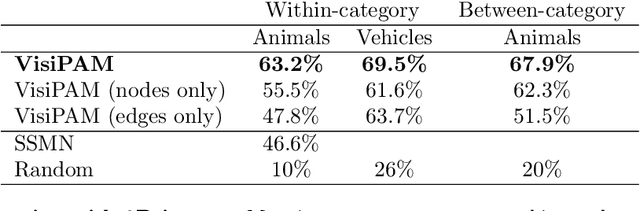


Human reasoning is grounded in an ability to identify highly abstract commonalities governing superficially dissimilar visual inputs. Recent efforts to develop algorithms with this capacity have largely focused on approaches that require extensive direct training on visual reasoning tasks, and yield limited generalization to problems with novel content. In contrast, a long tradition of research in cognitive science has focused on elucidating the computational principles underlying human analogical reasoning; however, this work has generally relied on manually constructed representations. Here we present visiPAM (visual Probabilistic Analogical Mapping), a model of visual reasoning that synthesizes these two approaches. VisiPAM employs learned representations derived directly from naturalistic visual inputs, coupled with a similarity-based mapping operation derived from cognitive theories of human reasoning. We show that without any direct training, visiPAM outperforms a state-of-the-art deep learning model on an analogical mapping task. In addition, visiPAM closely matches the pattern of human performance on a novel task involving mapping of 3D objects across disparate categories.
CX-ToM: Counterfactual Explanations with Theory-of-Mind for Enhancing Human Trust in Image Recognition Models
Sep 06, 2021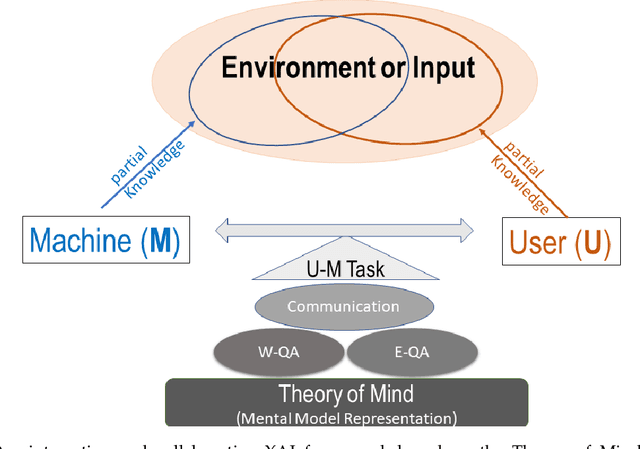
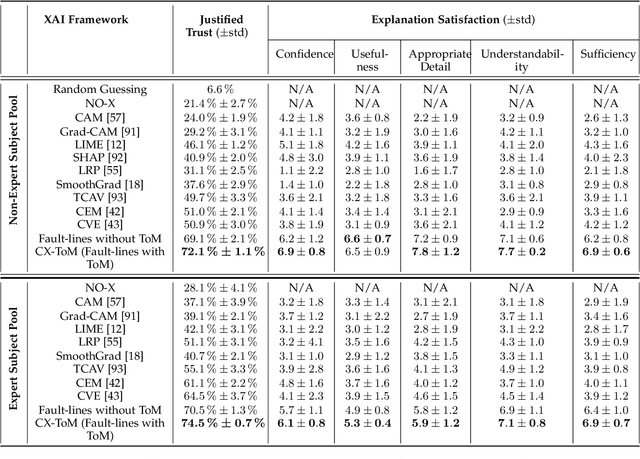
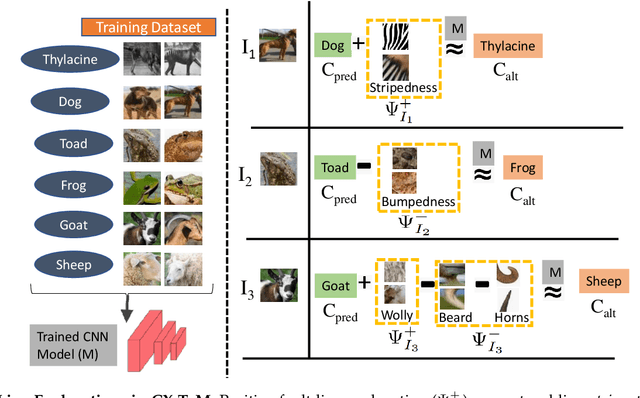
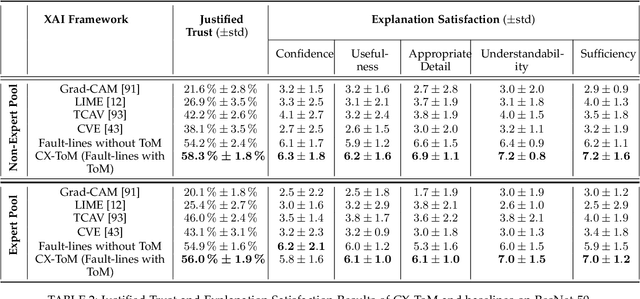
We propose CX-ToM, short for counterfactual explanations with theory-of mind, a new explainable AI (XAI) framework for explaining decisions made by a deep convolutional neural network (CNN). In contrast to the current methods in XAI that generate explanations as a single shot response, we pose explanation as an iterative communication process, i.e. dialog, between the machine and human user. More concretely, our CX-ToM framework generates sequence of explanations in a dialog by mediating the differences between the minds of machine and human user. To do this, we use Theory of Mind (ToM) which helps us in explicitly modeling human's intention, machine's mind as inferred by the human as well as human's mind as inferred by the machine. Moreover, most state-of-the-art XAI frameworks provide attention (or heat map) based explanations. In our work, we show that these attention based explanations are not sufficient for increasing human trust in the underlying CNN model. In CX-ToM, we instead use counterfactual explanations called fault-lines which we define as follows: given an input image I for which a CNN classification model M predicts class c_pred, a fault-line identifies the minimal semantic-level features (e.g., stripes on zebra, pointed ears of dog), referred to as explainable concepts, that need to be added to or deleted from I in order to alter the classification category of I by M to another specified class c_alt. We argue that, due to the iterative, conceptual and counterfactual nature of CX-ToM explanations, our framework is practical and more natural for both expert and non-expert users to understand the internal workings of complex deep learning models. Extensive quantitative and qualitative experiments verify our hypotheses, demonstrating that our CX-ToM significantly outperforms the state-of-the-art explainable AI models.
Visual analogy: Deep learning versus compositional models
May 14, 2021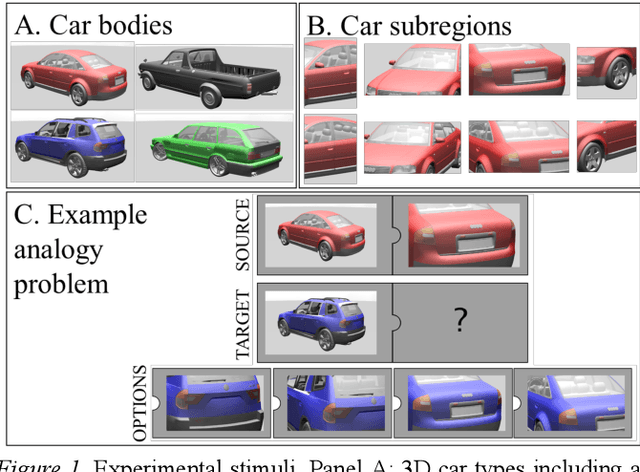
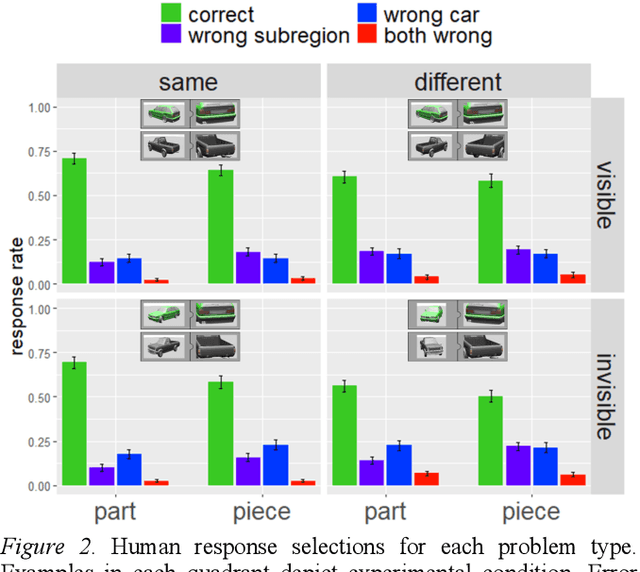
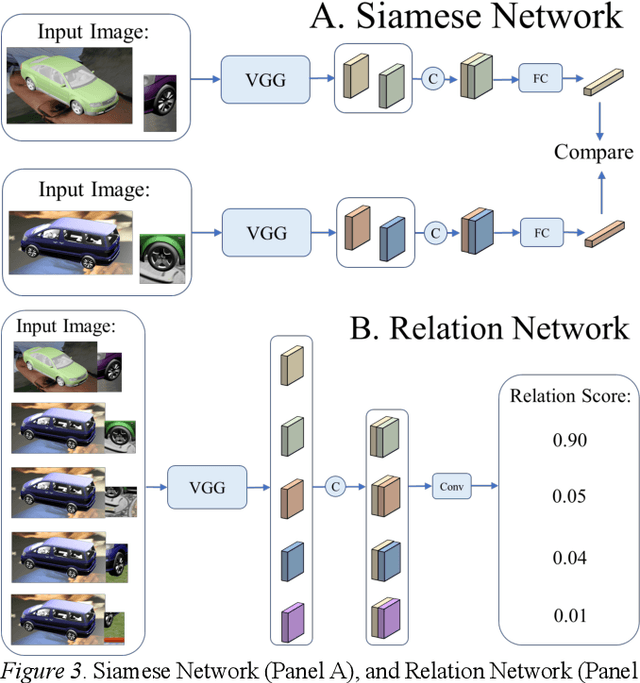
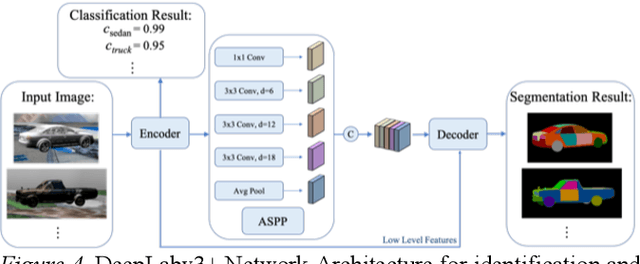
Is analogical reasoning a task that must be learned to solve from scratch by applying deep learning models to massive numbers of reasoning problems? Or are analogies solved by computing similarities between structured representations of analogs? We address this question by comparing human performance on visual analogies created using images of familiar three-dimensional objects (cars and their subregions) with the performance of alternative computational models. Human reasoners achieved above-chance accuracy for all problem types, but made more errors in several conditions (e.g., when relevant subregions were occluded). We compared human performance to that of two recent deep learning models (Siamese Network and Relation Network) directly trained to solve these analogy problems, as well as to that of a compositional model that assesses relational similarity between part-based representations. The compositional model based on part representations, but not the deep learning models, generated qualitative performance similar to that of human reasoners.
Probabilistic Analogical Mapping with Semantic Relation Networks
Mar 30, 2021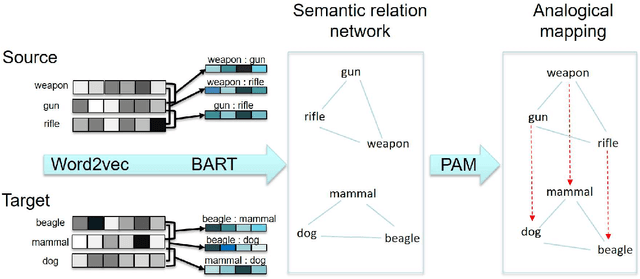
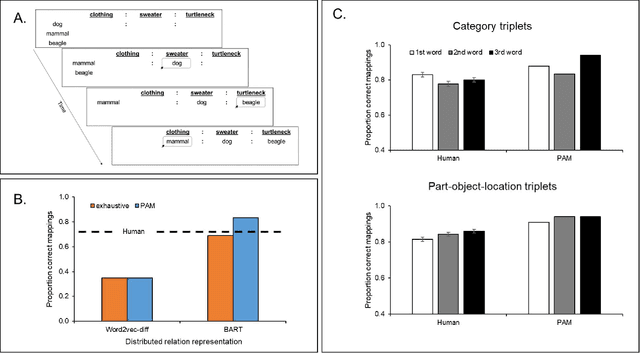

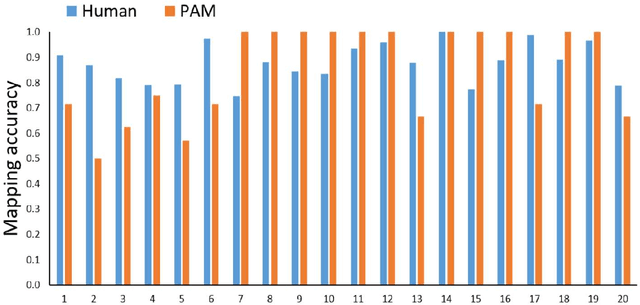
The human ability to flexibly reason with cross-domain analogies depends on mechanisms for identifying relations between concepts and for mapping concepts and their relations across analogs. We present a new computational model of analogical mapping, based on semantic relation networks constructed from distributed representations of individual concepts and of relations between concepts. Through comparisons with human performance in a new analogy experiment with 1,329 participants, as well as in four classic studies, we demonstrate that the model accounts for a broad range of phenomena involving analogical mapping by both adults and children. The key insight is that rich semantic representations of individual concepts and relations, coupled with a generic prior favoring isomorphic mappings, yield human-like analogical mapping.
Show Me What You Can Do: Capability Calibration on Reachable Workspace for Human-Robot Collaboration
Mar 06, 2021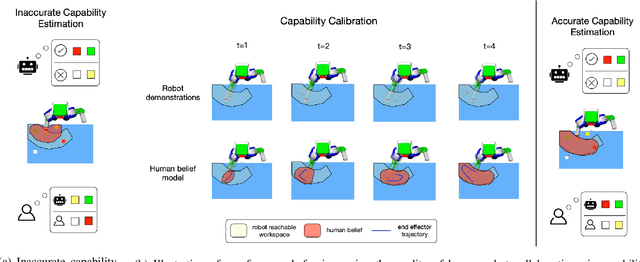
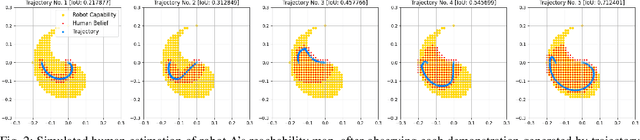
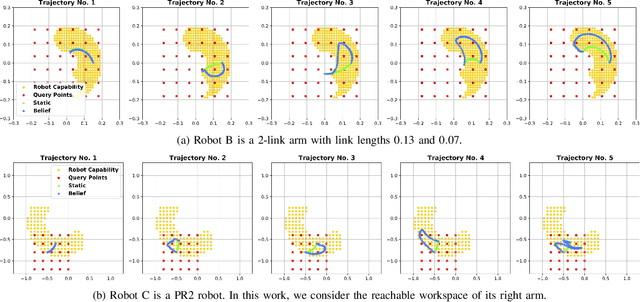

Aligning humans' assessment of what a robot can do with its true capability is crucial for establishing a common ground between human and robot partners when they collaborate on a joint task. In this work, we propose an approach to calibrate humans' estimate of a robot's reachable workspace through a small number of demonstrations before collaboration. We develop a novel motion planning method, REMP (Reachability-Expressive Motion Planning), which jointly optimizes the physical cost and the expressiveness of robot motion to reveal the robot's motion capability to a human observer. Our experiments with human participants demonstrate that a short calibration using REMP can effectively bridge the gap between what a non-expert user thinks a robot can reach and the ground-truth. We show that this calibration procedure not only results in better user perception, but also promotes more efficient human-robot collaborations in a subsequent joint task.