 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS2Edge: Towards Energy-Efficient and Crisp Edge Detection with Multi-Scale Residual Learning in SNNs
Nov 05, 2025Edge detection with Artificial Neural Networks (ANNs) has achieved remarkable prog\-ress but faces two major challenges. First, it requires pre-training on large-scale extra data and complex designs for prior knowledge, leading to high energy consumption. Second, the predicted edges perform poorly in crispness and heavily rely on post-processing. Spiking Neural Networks (SNNs), as third generation neural networks, feature quantization and spike-driven computation mechanisms. They inherently provide a strong prior for edge detection in an energy-efficient manner, while its quantization mechanism helps suppress texture artifact interference around true edges, improving prediction crispness. However, the resulting quantization error inevitably introduces sparse edge discontinuities, compromising further enhancement of crispness. To address these challenges, we propose MS2Edge, the first SNN-based model for edge detection. At its core, we build a novel spiking backbone named MS2ResNet that integrates multi-scale residual learning to recover missing boundary lines and generate crisp edges, while combining I-LIF neurons with Membrane-based Deformed Shortcut (MDS) to mitigate quantization errors. The model is complemented by a Spiking Multi-Scale Upsample Block (SMSUB) for detail reconstruction during upsampling and a Membrane Average Decoding (MAD) method for effective integration of edge maps across multiple time steps. Experimental results demonstrate that MS2Edge outperforms ANN-based methods and achieves state-of-the-art performance on the BSDS500, NYUDv2, BIPED, PLDU, and PLDM datasets without pre-trained backbones, while maintaining ultralow energy consumption and generating crisp edge maps without post-processing.
Zero-shot Context Biasing with Trie-based Decoding using Synthetic Multi-Pronunciation
Aug 25, 2025Contextual automatic speech recognition (ASR) systems allow for recognizing out-of-vocabulary (OOV) words, such as named entities or rare words. However, it remains challenging due to limited training data and ambiguous or inconsistent pronunciations. In this paper, we propose a synthesis-driven multi-pronunciation contextual biasing method that performs zero-shot contextual ASR on a pretrained Whisper model. Specifically, we leverage text-to-speech (TTS) systems to synthesize diverse speech samples containing each target rare word, and then use the pretrained Whisper model to extract multiple predicted pronunciation variants. These variant token sequences are compiled into a prefix-trie, which assigns rewards to beam hypotheses in a shallow-fusion manner during beam-search decoding. After which, any recognized variant is mapped back to the original rare word in the final transcription. The evaluation results on the Librispeech dataset show that our method reduces biased word error rate (WER) by 42% on test-clean and 43% on test-other while maintaining unbiased WER essentially unchanged.
Cycle Pixel Difference Network for Crisp Edge Detection
Sep 06, 2024
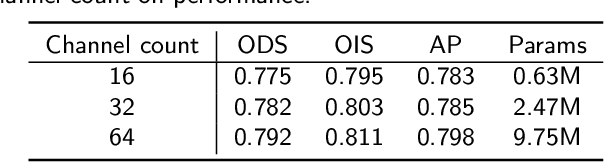


Edge detection, as a fundamental task in computer vision, has garnered increasing attention. The advent of deep learning has significantly advanced this field. However, recent deep learning-based methods which rely on large-scale pre-trained weights cannot be trained from scratch, with very limited research addressing this issue. This paper proposes a novel cycle pixel difference convolution (CPDC), which effectively integrates image gradient information with modern convolution operations. Based on the CPDC, we develop a U-shape encoder-decoder model named CPD-Net, which is a purely end-to-end network. Additionally, to address the issue of edge thickness produced by most existing methods, we construct a multi-scale information enhancement module (MSEM) to enhance the discriminative ability of the model, thereby generating crisp and clean contour maps. Comprehensive experiments conducted on three standard benchmarks demonstrate that our method achieves competitive performance on the BSDS500 dataset (ODS=0.813), NYUD-V2 (ODS=0.760), and BIPED dataset (ODS=0.898). Our approach provides a novel perspective for addressing these challenges in edge detection.
Learning to utilize gradient information for crisp edge detection
Jun 09, 2024Edge detection is a fundamental task in computer vision and it has made great progress under the development of deep convolutional neural networks (DCNNs), some of them have achieved a beyond human-level performance. However, recent top-performing edge detection methods tend to generate thick and blurred edge lines. In this work, we propose an effective method to solve this problem. Our approach consists of a lightweight pre-trained backbone, multi-scale contextual enhancement module aggregating gradient information (MCGI), boundary correction module (BCM), and boundary refinement module (BRM). In addition to this, we construct a novel hybrid loss function based on the Tversky index for solving the issue of imbalanced pixel distribution. We test our method on three standard benchmarks and the experiment results illustrate that our method improves the visual effect of edge maps and achieves a top performance among several state-of-the-art methods on the BSDS500 dataset (ODS F-score in standard evaluation is 0.829, in crispness evaluation is 0.720), NYUD-V2 dataset (ODS F-score in standard evaluation is 0.768, in crispness evaluation is \textbf{0.546}), and BIPED dataset (ODS F-score in standard evaluation is 0.903).
SFOD: Spiking Fusion Object Detector
Mar 22, 2024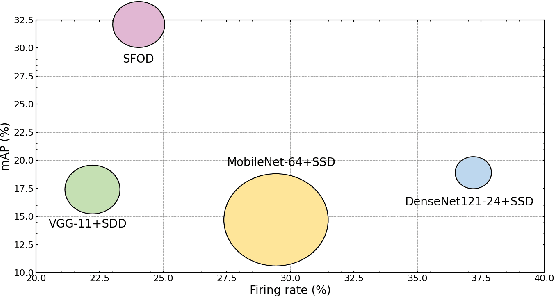
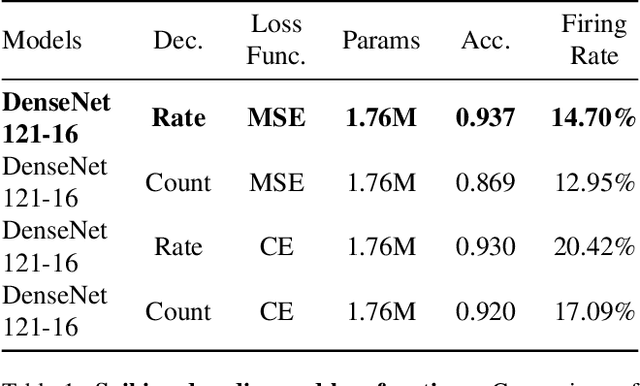
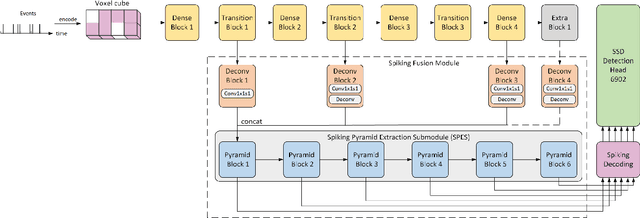
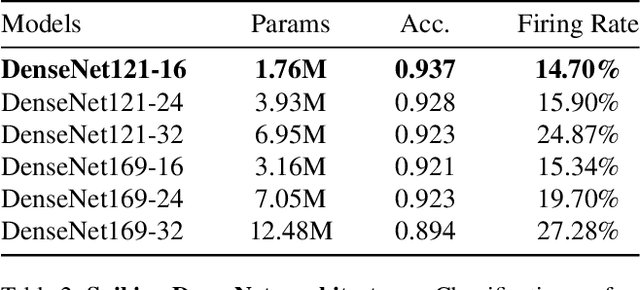
Event cameras, characterized by high temporal resolution, high dynamic range, low power consumption, and high pixel bandwidth, offer unique capabilities for object detection in specialized contexts. Despite these advantages, the inherent sparsity and asynchrony of event data pose challenges to existing object detection algorithms. Spiking Neural Networks (SNNs), inspired by the way the human brain codes and processes information, offer a potential solution to these difficulties. However, their performance in object detection using event cameras is limited in current implementations. In this paper, we propose the Spiking Fusion Object Detector (SFOD), a simple and efficient approach to SNN-based object detection. Specifically, we design a Spiking Fusion Module, achieving the first-time fusion of feature maps from different scales in SNNs applied to event cameras. Additionally, through integrating our analysis and experiments conducted during the pretraining of the backbone network on the NCAR dataset, we delve deeply into the impact of spiking decoding strategies and loss functions on model performance. Thereby, we establish state-of-the-art classification results based on SNNs, achieving 93.7\% accuracy on the NCAR dataset. Experimental results on the GEN1 detection dataset demonstrate that the SFOD achieves a state-of-the-art mAP of 32.1\%, outperforming existing SNN-based approaches. Our research not only underscores the potential of SNNs in object detection with event cameras but also propels the advancement of SNNs. Code is available at https://github.com/yimeng-fan/SFOD.
CX-ToM: Counterfactual Explanations with Theory-of-Mind for Enhancing Human Trust in Image Recognition Models
Sep 06, 2021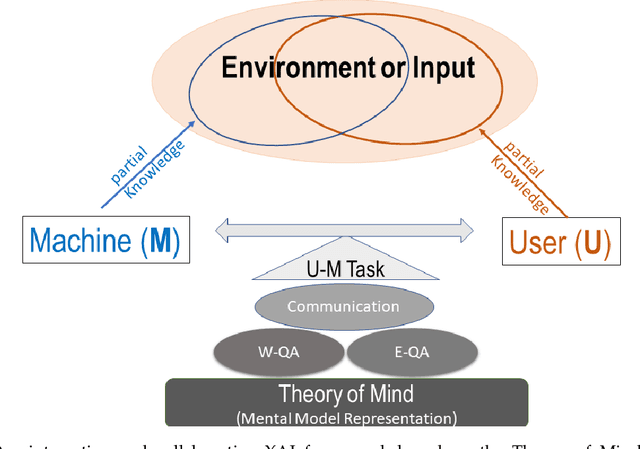
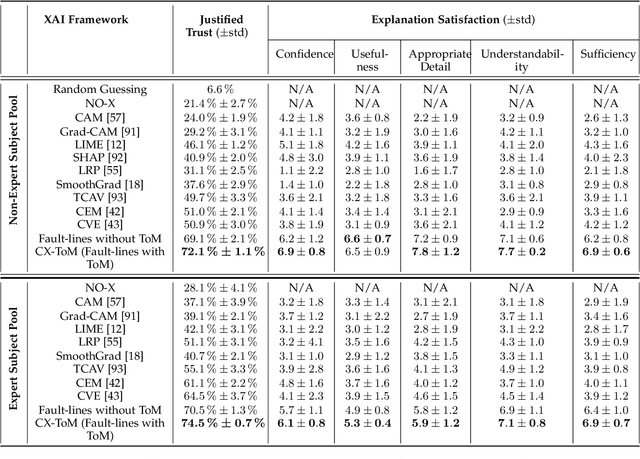
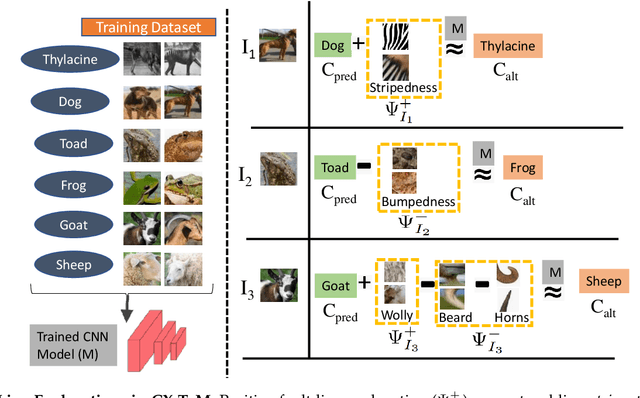
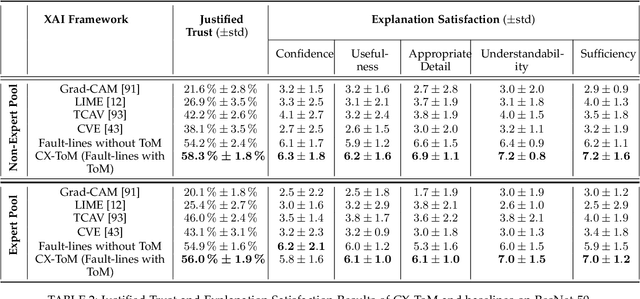
We propose CX-ToM, short for counterfactual explanations with theory-of mind, a new explainable AI (XAI) framework for explaining decisions made by a deep convolutional neural network (CNN). In contrast to the current methods in XAI that generate explanations as a single shot response, we pose explanation as an iterative communication process, i.e. dialog, between the machine and human user. More concretely, our CX-ToM framework generates sequence of explanations in a dialog by mediating the differences between the minds of machine and human user. To do this, we use Theory of Mind (ToM) which helps us in explicitly modeling human's intention, machine's mind as inferred by the human as well as human's mind as inferred by the machine. Moreover, most state-of-the-art XAI frameworks provide attention (or heat map) based explanations. In our work, we show that these attention based explanations are not sufficient for increasing human trust in the underlying CNN model. In CX-ToM, we instead use counterfactual explanations called fault-lines which we define as follows: given an input image I for which a CNN classification model M predicts class c_pred, a fault-line identifies the minimal semantic-level features (e.g., stripes on zebra, pointed ears of dog), referred to as explainable concepts, that need to be added to or deleted from I in order to alter the classification category of I by M to another specified class c_alt. We argue that, due to the iterative, conceptual and counterfactual nature of CX-ToM explanations, our framework is practical and more natural for both expert and non-expert users to understand the internal workings of complex deep learning models. Extensive quantitative and qualitative experiments verify our hypotheses, demonstrating that our CX-ToM significantly outperforms the state-of-the-art explainable AI models.
X-ToM: Explaining with Theory-of-Mind for Gaining Justified Human Trust
Sep 15, 2019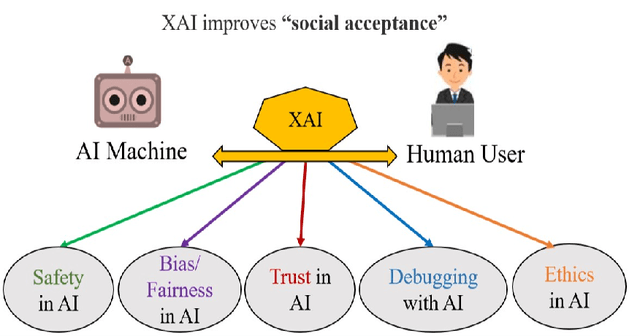

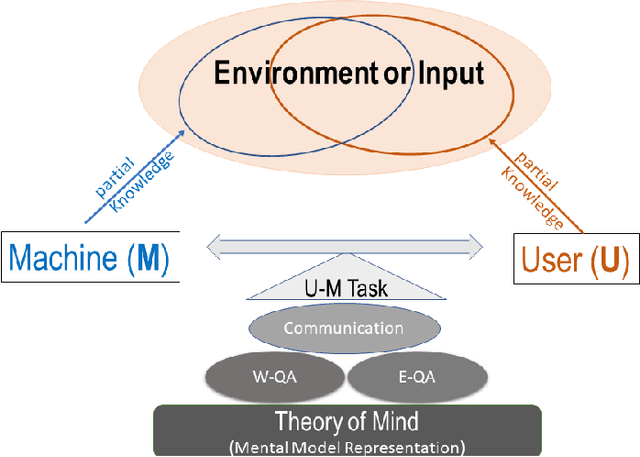
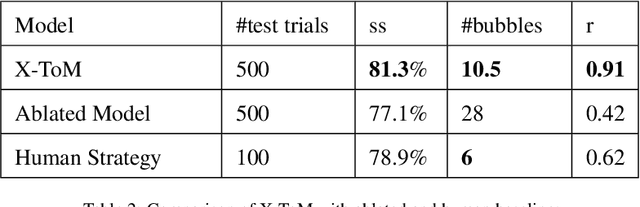
We present a new explainable AI (XAI) framework aimed at increasing justified human trust and reliance in the AI machine through explanations. We pose explanation as an iterative communication process, i.e. dialog, between the machine and human user. More concretely, the machine generates sequence of explanations in a dialog which takes into account three important aspects at each dialog turn: (a) human's intention (or curiosity); (b) human's understanding of the machine; and (c) machine's understanding of the human user. To do this, we use Theory of Mind (ToM) which helps us in explicitly modeling human's intention, machine's mind as inferred by the human as well as human's mind as inferred by the machine. In other words, these explicit mental representations in ToM are incorporated to learn an optimal explanation policy that takes into account human's perception and beliefs. Furthermore, we also show that ToM facilitates in quantitatively measuring justified human trust in the machine by comparing all the three mental representations. We applied our framework to three visual recognition tasks, namely, image classification, action recognition, and human body pose estimation. We argue that our ToM based explanations are practical and more natural for both expert and non-expert users to understand the internal workings of complex machine learning models. To the best of our knowledge, this is the first work to derive explanations using ToM. Extensive human study experiments verify our hypotheses, showing that the proposed explanations significantly outperform the state-of-the-art XAI methods in terms of all the standard quantitative and qualitative XAI evaluation metrics including human trust, reliance, and explanation satisfaction.
Occlusion Robust Face Recognition Based on Mask Learning with PairwiseDifferential Siamese Network
Aug 17, 2019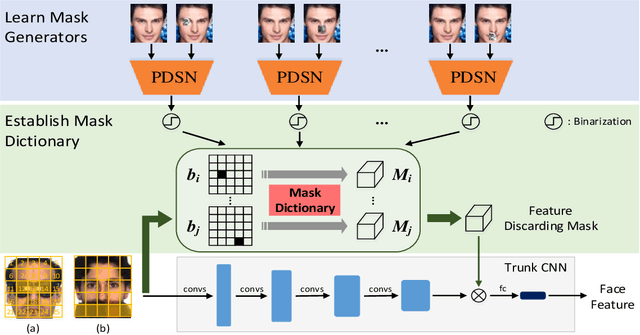

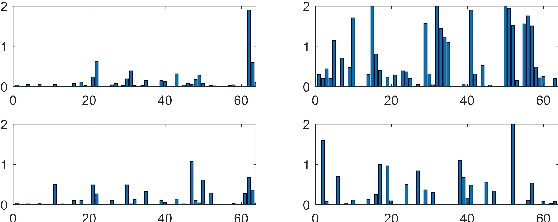
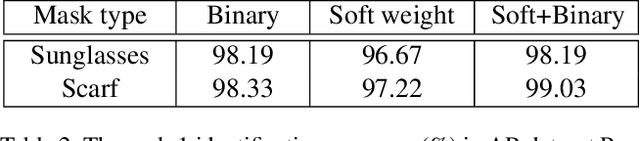
Deep Convolutional Neural Networks (CNNs) have been pushing the frontier of the face recognition research in the past years. However, existing general CNN face models generalize poorly to the scenario of occlusions on variable facial areas. Inspired by the fact that a human visual system explicitly ignores occlusions and only focuses on non-occluded facial areas, we propose a mask learning strategy to find and discard the corrupted feature elements for face recognition. A mask dictionary is firstly established by exploiting the differences between the top convoluted features of occluded and occlusion-free face pairs using an innovatively designed Pairwise Differential Siamese Network (PDSN). Each item of this dictionary captures the correspondence between occluded facial areas and corrupted feature elements, which is named Feature Discarding Mask (FDM). When dealing with a face image with random partial occlusions, we generate its FDM by combining relevant dictionary items and then multiply it with the original features to eliminate those corrupted feature elements. Comprehensive experiments on both synthesized and realistic occluded face datasets show that the proposed approach significantly outperforms the state-of-the-arts.
Learning with Rethinking: Recurrently Improving Convolutional Neural Networks through Feedback
Aug 15, 2017

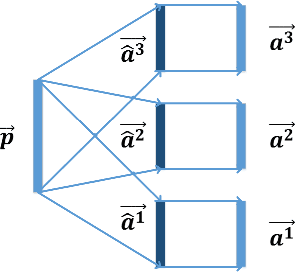

Recent years have witnessed the great success of convolutional neural network (CNN) based models in the field of computer vision. CNN is able to learn hierarchically abstracted features from images in an end-to-end training manner. However, most of the existing CNN models only learn features through a feedforward structure and no feedback information from top to bottom layers is exploited to enable the networks to refine themselves. In this paper, we propose a "Learning with Rethinking" algorithm. By adding a feedback layer and producing the emphasis vector, the model is able to recurrently boost the performance based on previous prediction. Particularly, it can be employed to boost any pre-trained models. This algorithm is tested on four object classification benchmark datasets: CIFAR-100, CIFAR-10, MNIST-background-image and ILSVRC-2012 dataset. These results have demonstrated the advantage of training CNN models with the proposed feedback mechanism.
Prune the Convolutional Neural Networks with Sparse Shrink
Aug 08, 2017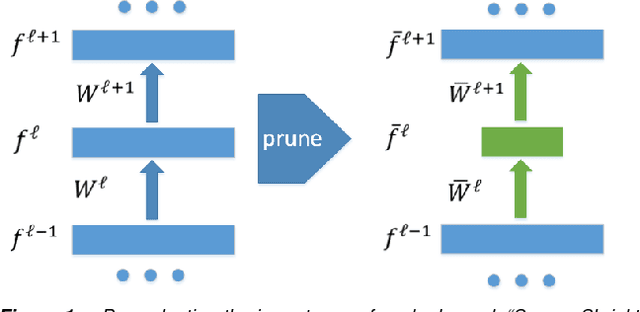

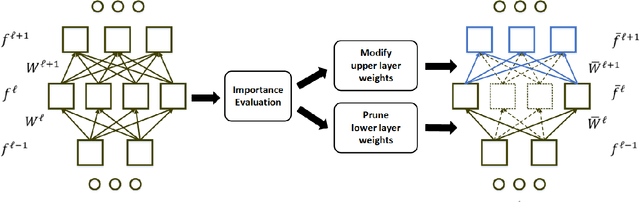

Nowadays, it is still difficult to adapt Convolutional Neural Network (CNN) based models for deployment on embedded devices. The heavy computation and large memory footprint of CNN models become the main burden in real application. In this paper, we propose a "Sparse Shrink" algorithm to prune an existing CNN model. By analyzing the importance of each channel via sparse reconstruction, the algorithm is able to prune redundant feature maps accordingly. The resulting pruned model thus directly saves computational resource. We have evaluated our algorithm on CIFAR-100. As shown in our experiments, we can reduce 56.77% parameters and 73.84% multiplication in total with only minor decrease in accuracy. These results have demonstrated the effectiveness of our "Sparse Shrink" algorithm.