 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Instructions for Intuitive Human Interaction with Robotic Assistants in Field Construction Work
Jul 11, 2023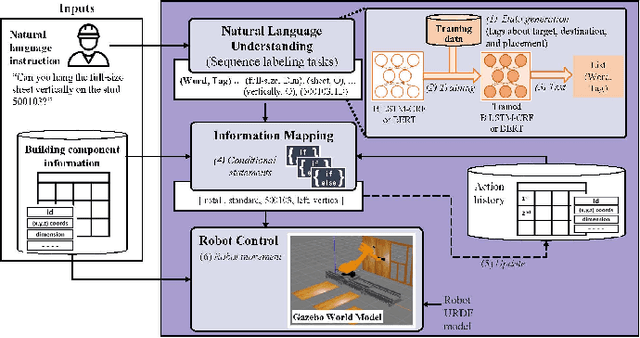
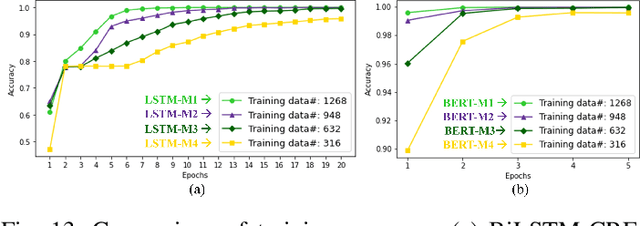

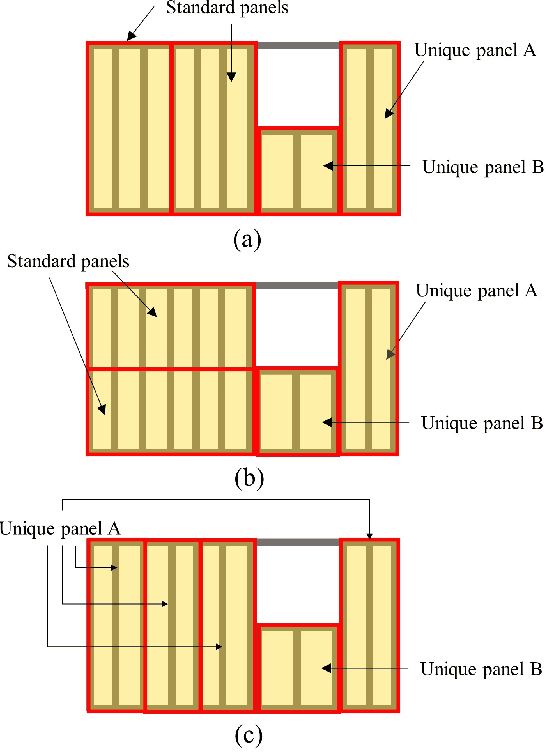
The introduction of robots is widely considered to have significant potential of alleviating the issues of worker shortage and stagnant productivity that afflict the construction industry. However, it is challenging to use fully automated robots in complex and unstructured construction sites. Human-Robot Collaboration (HRC) has shown promise of combining human workers' flexibility and robot assistants' physical abilities to jointly address the uncertainties inherent in construction work. When introducing HRC in construction, it is critical to recognize the importance of teamwork and supervision in field construction and establish a natural and intuitive communication system for the human workers and robotic assistants. Natural language-based interaction can enable intuitive and familiar communication with robots for human workers who are non-experts in robot programming. However, limited research has been conducted on this topic in construction. This paper proposes a framework to allow human workers to interact with construction robots based on natural language instructions. The proposed method consists of three stages: Natural Language Understanding (NLU), Information Mapping (IM), and Robot Control (RC). Natural language instructions are input to a language model to predict a tag for each word in the NLU module. The IM module uses the result of the NLU module and building component information to generate the final instructional output essential for a robot to acknowledge and perform the construction task. A case study for drywall installation is conducted to evaluate the proposed approach. The obtained results highlight the potential of using natural language-based interaction to replicate the communication that occurs between human workers within the context of human-robot teams.
Zero-Shot Compositional Concept Learning
Jul 12, 2021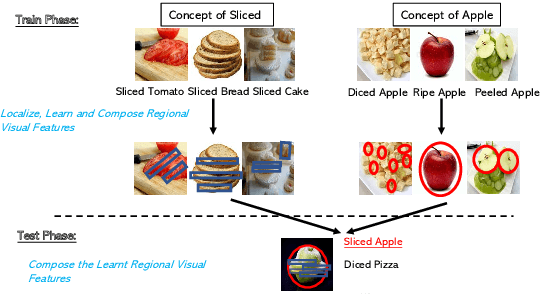
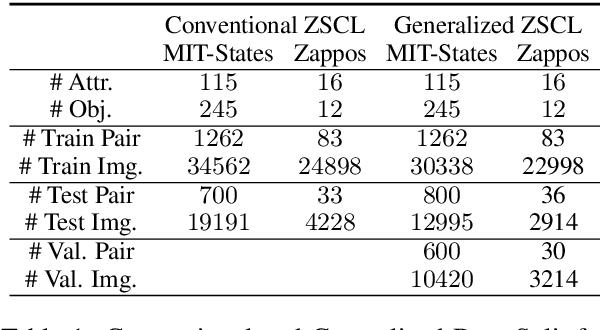

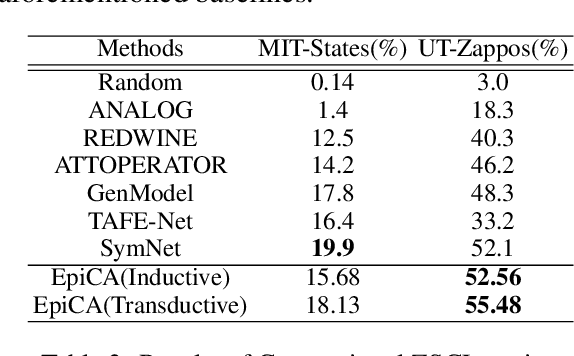
In this paper, we study the problem of recognizing compositional attribute-object concepts within the zero-shot learning (ZSL) framework. We propose an episode-based cross-attention (EpiCA) network which combines merits of cross-attention mechanism and episode-based training strategy to recognize novel compositional concepts. Firstly, EpiCA bases on cross-attention to correlate concept-visual information and utilizes the gated pooling layer to build contextualized representations for both images and concepts. The updated representations are used for a more in-depth multi-modal relevance calculation for concept recognition. Secondly, a two-phase episode training strategy, especially the transductive phase, is adopted to utilize unlabeled test examples to alleviate the low-resource learning problem. Experiments on two widely-used zero-shot compositional learning (ZSCL) benchmarks have demonstrated the effectiveness of the model compared with recent approaches on both conventional and generalized ZSCL settings.
X-ToM: Explaining with Theory-of-Mind for Gaining Justified Human Trust
Sep 15, 2019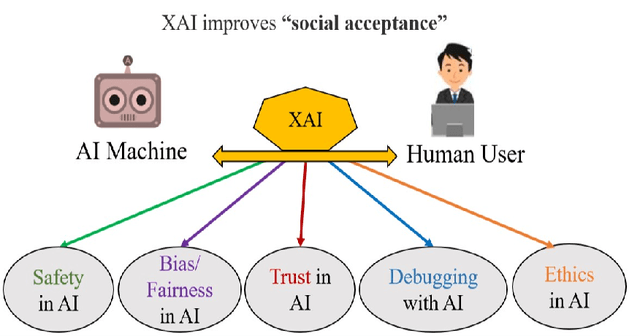

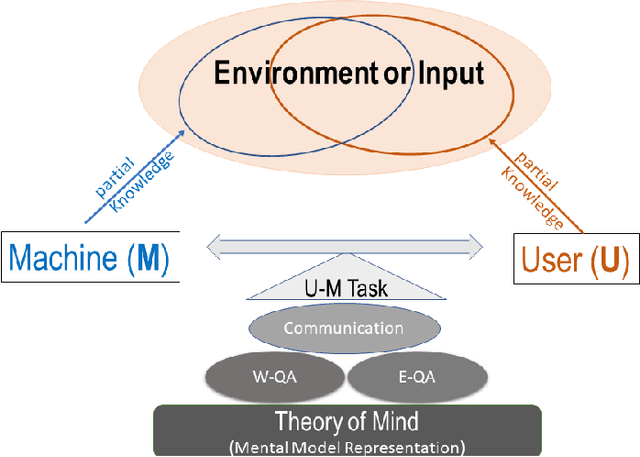
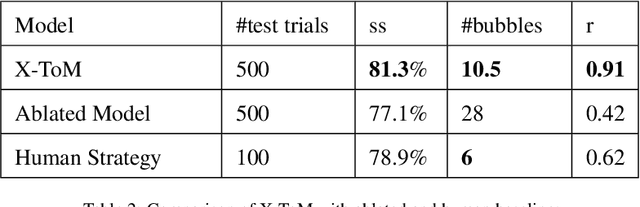
We present a new explainable AI (XAI) framework aimed at increasing justified human trust and reliance in the AI machine through explanations. We pose explanation as an iterative communication process, i.e. dialog, between the machine and human user. More concretely, the machine generates sequence of explanations in a dialog which takes into account three important aspects at each dialog turn: (a) human's intention (or curiosity); (b) human's understanding of the machine; and (c) machine's understanding of the human user. To do this, we use Theory of Mind (ToM) which helps us in explicitly modeling human's intention, machine's mind as inferred by the human as well as human's mind as inferred by the machine. In other words, these explicit mental representations in ToM are incorporated to learn an optimal explanation policy that takes into account human's perception and beliefs. Furthermore, we also show that ToM facilitates in quantitatively measuring justified human trust in the machine by comparing all the three mental representations. We applied our framework to three visual recognition tasks, namely, image classification, action recognition, and human body pose estimation. We argue that our ToM based explanations are practical and more natural for both expert and non-expert users to understand the internal workings of complex machine learning models. To the best of our knowledge, this is the first work to derive explanations using ToM. Extensive human study experiments verify our hypotheses, showing that the proposed explanations significantly outperform the state-of-the-art XAI methods in terms of all the standard quantitative and qualitative XAI evaluation metrics including human trust, reliance, and explanation satisfaction.
Commonsense Reasoning for Natural Language Understanding: A Survey of Benchmarks, Resources, and Approaches
Apr 02, 2019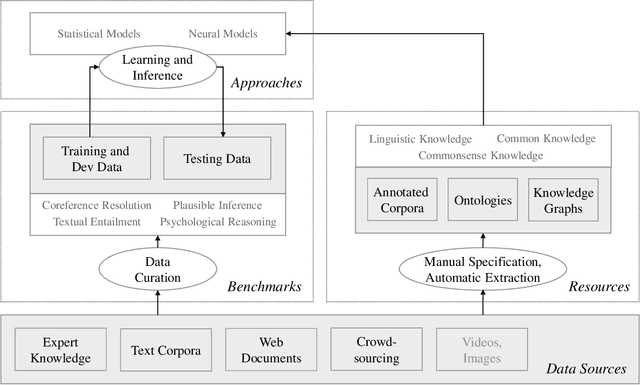
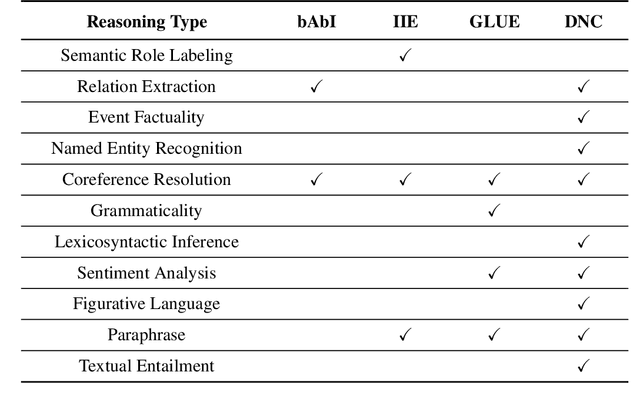
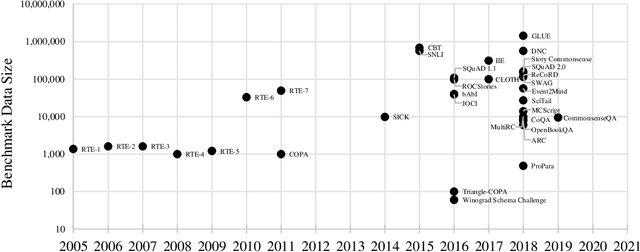
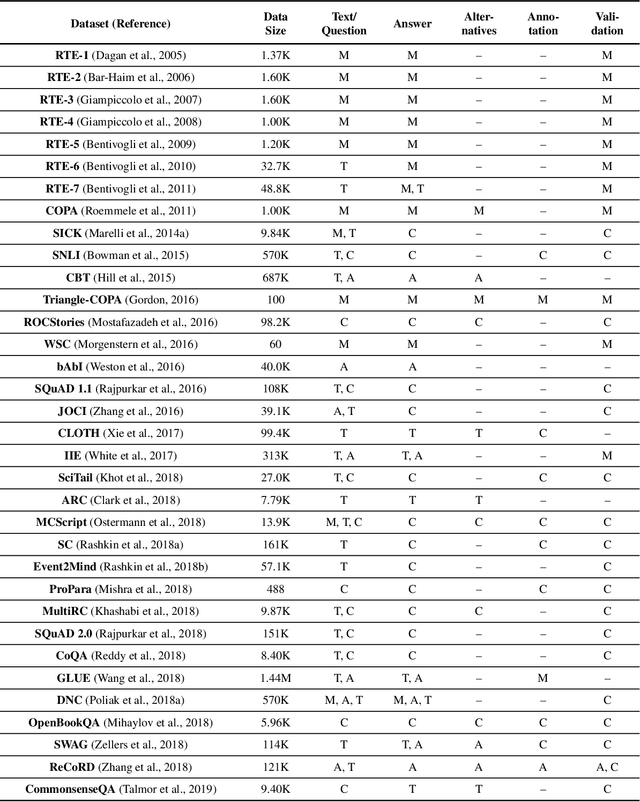
Commonsense knowledge and commonsense reasoning are some of the main bottlenecks in machine intelligence. In the NLP community, many benchmark datasets and tasks have been created to address commonsense reasoning for language understanding. These tasks are designed to assess machines' ability to acquire and learn commonsense knowledge in order to reason and understand natural language text. As these tasks become instrumental and a driving force for commonsense research, this paper aims to provide an overview of existing tasks and benchmarks, knowledge resources, and learning and inference approaches toward commonsense reasoning for natural language understanding. Through this, our goal is to support a better understanding of the state of the art, its limitations, and future challenges.
Interactive Learning of State Representation through Natural Language Instruction and Explanation
Oct 07, 2017
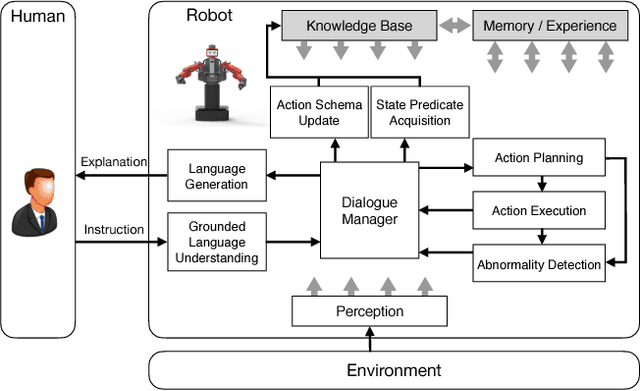

One significant simplification in most previous work on robot learning is the closed-world assumption where the robot is assumed to know ahead of time a complete set of predicates describing the state of the physical world. However, robots are not likely to have a complete model of the world especially when learning a new task. To address this problem, this extended abstract gives a brief introduction to our on-going work that aims to enable the robot to acquire new state representations through language communication with humans.
Context-based Word Acquisition for Situated Dialogue in a Virtual World
Jan 16, 2014
To tackle the vocabulary problem in conversational systems, previous work has applied unsupervised learning approaches on co-occurring speech and eye gaze during interaction to automatically acquire new words. Although these approaches have shown promise, several issues related to human language behavior and human-machine conversation have not been addressed. First, psycholinguistic studies have shown certain temporal regularities between human eye movement and language production. While these regularities can potentially guide the acquisition process, they have not been incorporated in the previous unsupervised approaches. Second, conversational systems generally have an existing knowledge base about the domain and vocabulary. While the existing knowledge can potentially help bootstrap and constrain the acquired new words, it has not been incorporated in the previous models. Third, eye gaze could serve different functions in human-machine conversation. Some gaze streams may not be closely coupled with speech stream, and thus are potentially detrimental to word acquisition. Automated recognition of closely-coupled speech-gaze streams based on conversation context is important. To address these issues, we developed new approaches that incorporate user language behavior, domain knowledge, and conversation context in word acquisition. We evaluated these approaches in the context of situated dialogue in a virtual world. Our experimental results have shown that incorporating the above three types of contextual information significantly improves word acquisition performance.