 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnpaired Image-to-Image Translation for Segmentation and Signal Unmixing
May 27, 2025This work introduces Ui2i, a novel model for unpaired image-to-image translation, trained on content-wise unpaired datasets to enable style transfer across domains while preserving content. Building on CycleGAN, Ui2i incorporates key modifications to better disentangle content and style features, and preserve content integrity. Specifically, Ui2i employs U-Net-based generators with skip connections to propagate localized shallow features deep into the generator. Ui2i removes feature-based normalization layers from all modules and replaces them with approximate bidirectional spectral normalization -- a parameter-based alternative that enhances training stability. To further support content preservation, channel and spatial attention mechanisms are integrated into the generators. Training is facilitated through image scale augmentation. Evaluation on two biomedical tasks -- domain adaptation for nuclear segmentation in immunohistochemistry (IHC) images and unmixing of biological structures superimposed in single-channel immunofluorescence (IF) images -- demonstrates Ui2i's ability to preserve content fidelity in settings that demand more accurate structural preservation than typical translation tasks. To the best of our knowledge, Ui2i is the first approach capable of separating superimposed signals in IF images using real, unpaired training data.
End-to-End Action Segmentation Transformer
Mar 11, 2025Existing approaches to action segmentation use pre-computed frame features extracted by methods which have been trained on tasks that are different from action segmentation. Also, recent approaches typically use deep framewise representations that lack explicit modeling of action segments. To address these shortcomings, we introduce the first end-to-end solution to action segmentation -- End-to-End Action Segmentation Transformer (EAST). Our key contributions include: (1) a simple and efficient adapter design for effective backbone fine-tuning; (2) a segmentation-by-detection framework for leveraging action proposals initially predicted over a coarsely downsampled video toward labeling of all frames; and (3) a new action-proposal based data augmentation for robust training. EAST achieves state-of-the-art performance on standard benchmarks, including GTEA, 50Salads, Breakfast, and Assembly-101. The model and corresponding code will be released.
iFS-RCNN: An Incremental Few-shot Instance Segmenter
May 31, 2022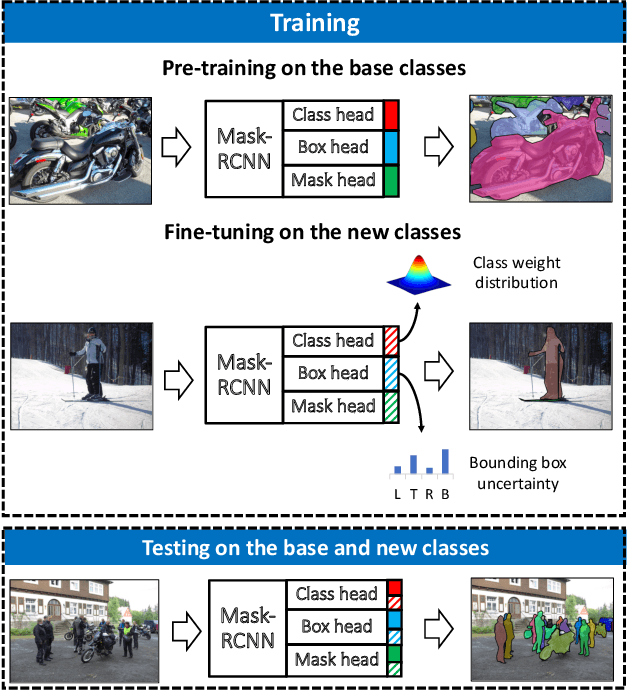
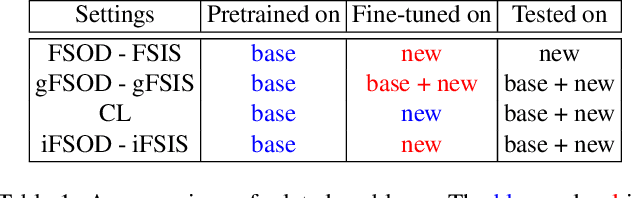
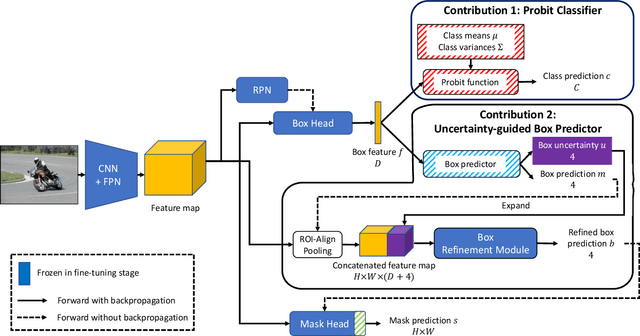
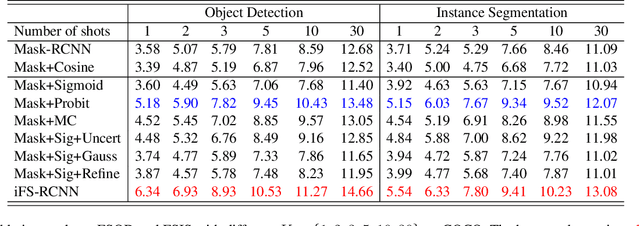
This paper addresses incremental few-shot instance segmentation, where a few examples of new object classes arrive when access to training examples of old classes is not available anymore, and the goal is to perform well on both old and new classes. We make two contributions by extending the common Mask-RCNN framework in its second stage -- namely, we specify a new object class classifier based on the probit function and a new uncertainty-guided bounding-box predictor. The former leverages Bayesian learning to address a paucity of training examples of new classes. The latter learns not only to predict object bounding boxes but also to estimate the uncertainty of the prediction as guidance for bounding box refinement. We also specify two new loss functions in terms of the estimated object-class distribution and bounding-box uncertainty. Our contributions produce significant performance gains on the COCO dataset over the state of the art -- specifically, the gain of +6 on the new classes and +16 on the old classes in the AP instance segmentation metric. Furthermore, we are the first to evaluate the incremental few-shot setting on the more challenging LVIS dataset.
CX-ToM: Counterfactual Explanations with Theory-of-Mind for Enhancing Human Trust in Image Recognition Models
Sep 06, 2021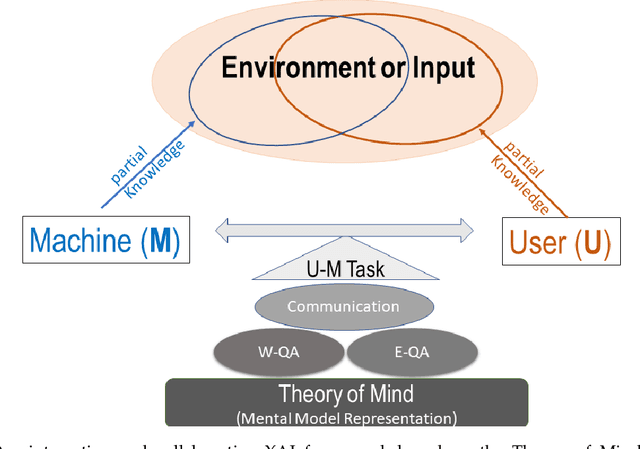
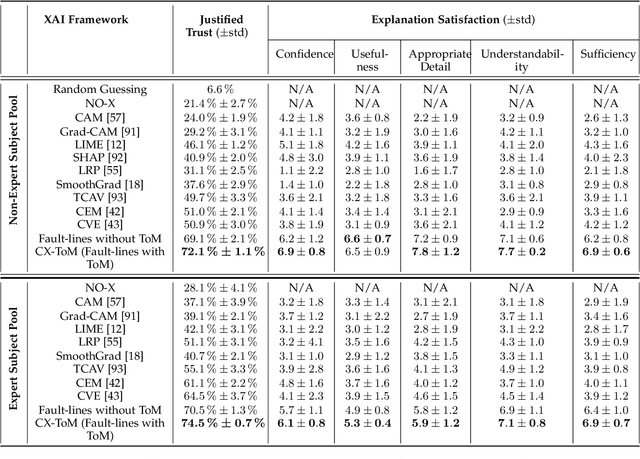
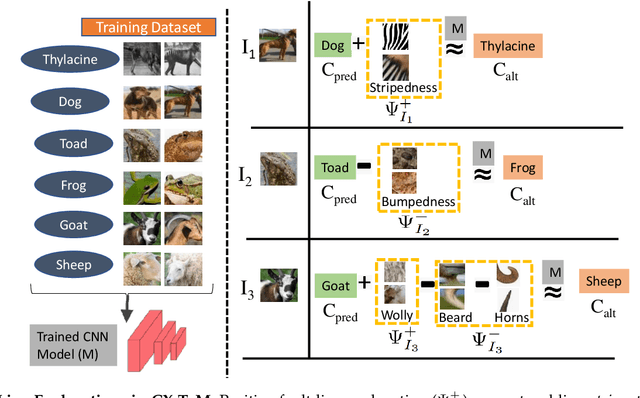
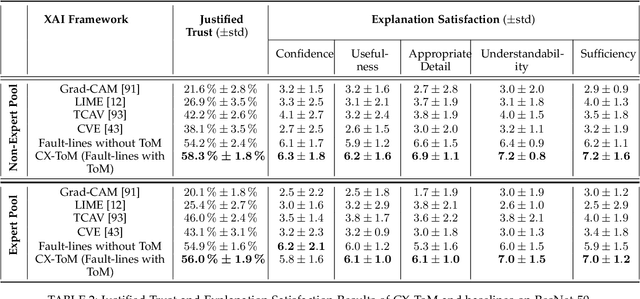
We propose CX-ToM, short for counterfactual explanations with theory-of mind, a new explainable AI (XAI) framework for explaining decisions made by a deep convolutional neural network (CNN). In contrast to the current methods in XAI that generate explanations as a single shot response, we pose explanation as an iterative communication process, i.e. dialog, between the machine and human user. More concretely, our CX-ToM framework generates sequence of explanations in a dialog by mediating the differences between the minds of machine and human user. To do this, we use Theory of Mind (ToM) which helps us in explicitly modeling human's intention, machine's mind as inferred by the human as well as human's mind as inferred by the machine. Moreover, most state-of-the-art XAI frameworks provide attention (or heat map) based explanations. In our work, we show that these attention based explanations are not sufficient for increasing human trust in the underlying CNN model. In CX-ToM, we instead use counterfactual explanations called fault-lines which we define as follows: given an input image I for which a CNN classification model M predicts class c_pred, a fault-line identifies the minimal semantic-level features (e.g., stripes on zebra, pointed ears of dog), referred to as explainable concepts, that need to be added to or deleted from I in order to alter the classification category of I by M to another specified class c_alt. We argue that, due to the iterative, conceptual and counterfactual nature of CX-ToM explanations, our framework is practical and more natural for both expert and non-expert users to understand the internal workings of complex deep learning models. Extensive quantitative and qualitative experiments verify our hypotheses, demonstrating that our CX-ToM significantly outperforms the state-of-the-art explainable AI models.
A Weakly Supervised Amodal Segmenter with Boundary Uncertainty Estimation
Aug 30, 2021
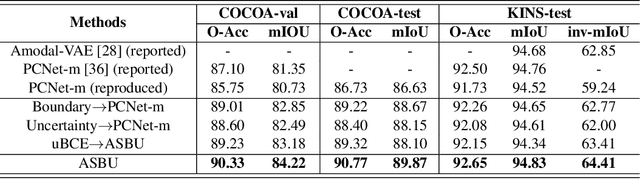

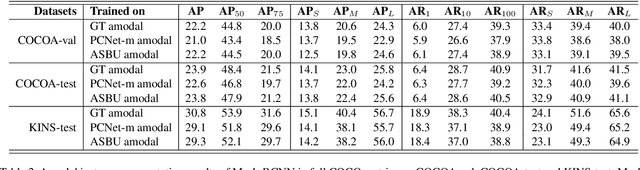
This paper addresses weakly supervised amodal instance segmentation, where the goal is to segment both visible and occluded (amodal) object parts, while training provides only ground-truth visible (modal) segmentations. Following prior work, we use data manipulation to generate occlusions in training images and thus train a segmenter to predict amodal segmentations of the manipulated data. The resulting predictions on training images are taken as the pseudo-ground truth for the standard training of Mask-RCNN, which we use for amodal instance segmentation of test images. For generating the pseudo-ground truth, we specify a new Amodal Segmenter based on Boundary Uncertainty estimation (ASBU) and make two contributions. First, while prior work uses the occluder's mask, our ASBU uses the occlusion boundary as input. Second, ASBU estimates an uncertainty map of the prediction. The estimated uncertainty regularizes learning such that lower segmentation loss is incurred on regions with high uncertainty. ASBU achieves significant performance improvement relative to the state of the art on the COCOA and KINS datasets in three tasks: amodal instance segmentation, amodal completion, and ordering recovery.
Action Shuffle Alternating Learning for Unsupervised Action Segmentation
Apr 05, 2021
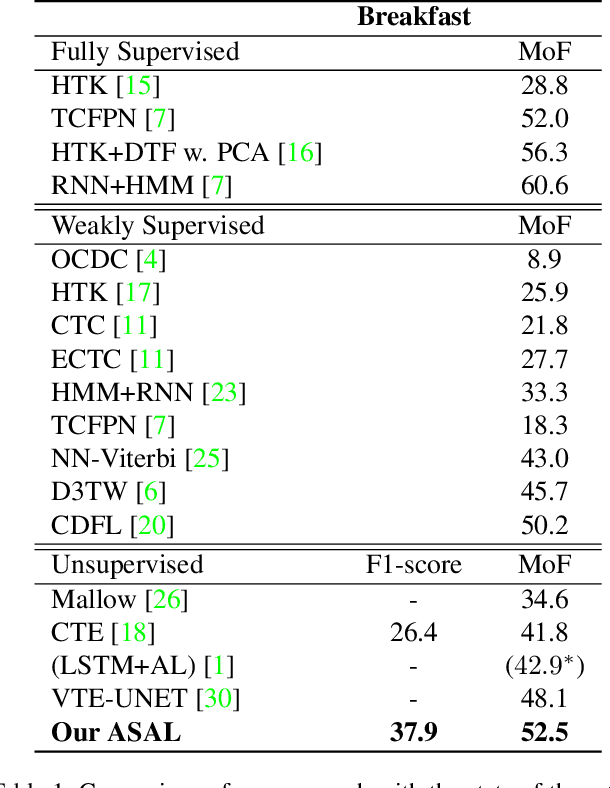
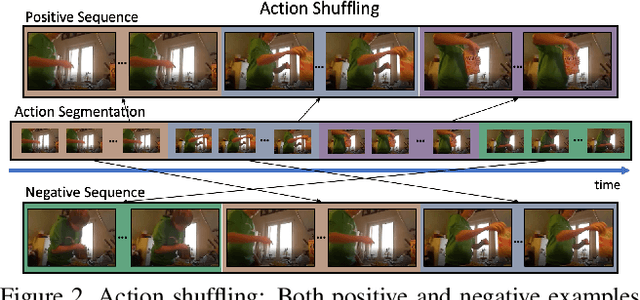

This paper addresses unsupervised action segmentation. Prior work captures the frame-level temporal structure of videos by a feature embedding that encodes time locations of frames in the video. We advance prior work with a new self-supervised learning (SSL) of a feature embedding that accounts for both frame- and action-level structure of videos. Our SSL trains an RNN to recognize positive and negative action sequences, and the RNN's hidden layer is taken as our new action-level feature embedding. The positive and negative sequences consist of action segments sampled from videos, where in the former the sampled action segments respect their time ordering in the video, and in the latter they are shuffled. As supervision of actions is not available and our SSL requires access to action segments, we specify an HMM that explicitly models action lengths, and infer a MAP action segmentation with the Viterbi algorithm. The resulting action segmentation is used as pseudo-ground truth for estimating our action-level feature embedding and updating the HMM. We alternate the above steps within the Generalized EM framework, which ensures convergence. Our evaluation on the Breakfast, YouTube Instructions, and 50Salads datasets gives superior results to those of the state of the art.
Anchor-Constrained Viterbi for Set-Supervised Action Segmentation
Apr 05, 2021

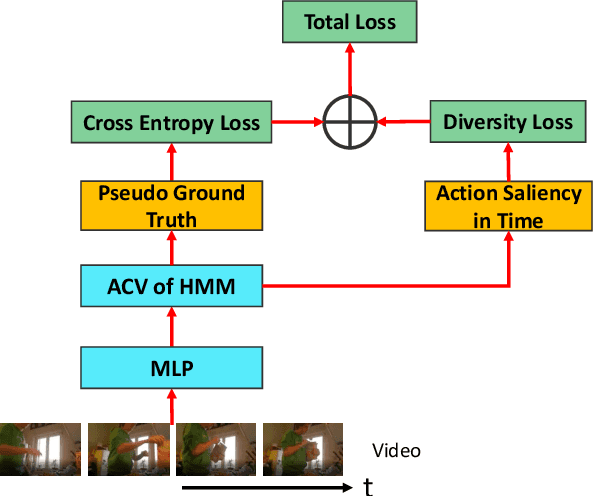

This paper is about action segmentation under weak supervision in training, where the ground truth provides only a set of actions present, but neither their temporal ordering nor when they occur in a training video. We use a Hidden Markov Model (HMM) grounded on a multilayer perceptron (MLP) to label video frames, and thus generate a pseudo-ground truth for the subsequent pseudo-supervised training. In testing, a Monte Carlo sampling of action sets seen in training is used to generate candidate temporal sequences of actions, and select the maximum posterior sequence. Our key contribution is a new anchor-constrained Viterbi algorithm (ACV) for generating the pseudo-ground truth, where anchors are salient action parts estimated for each action from a given ground-truth set. Our evaluation on the tasks of action segmentation and alignment on the benchmark Breakfast, MPII Cooking2, Hollywood Extended datasets demonstrates our superior performance relative to that of prior work.
FAPIS: A Few-shot Anchor-free Part-based Instance Segmenter
Mar 31, 2021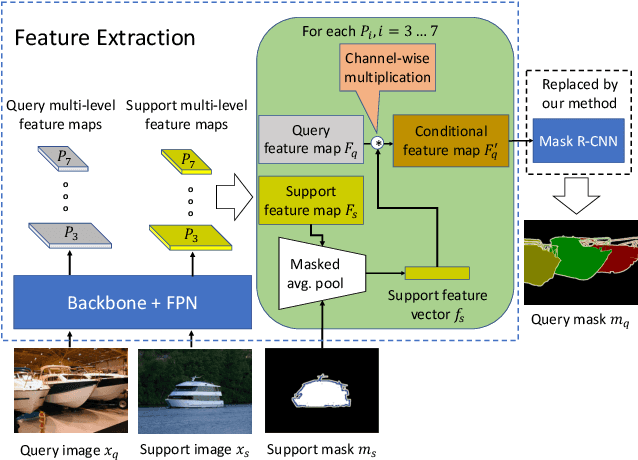



This paper is about few-shot instance segmentation, where training and test image sets do not share the same object classes. We specify and evaluate a new few-shot anchor-free part-based instance segmenter FAPIS. Our key novelty is in explicit modeling of latent object parts shared across training object classes, which is expected to facilitate our few-shot learning on new classes in testing. We specify a new anchor-free object detector aimed at scoring and regressing locations of foreground bounding boxes, as well as estimating relative importance of latent parts within each box. Also, we specify a new network for delineating and weighting latent parts for the final instance segmentation within every detected bounding box. Our evaluation on the benchmark COCO-20i dataset demonstrates that we significantly outperform the state of the art.
A Self-supervised GAN for Unsupervised Few-shot Object Recognition
Aug 16, 2020

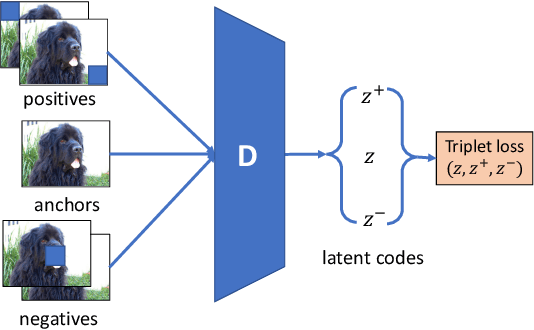

This paper addresses unsupervised few-shot object recognition, where all training images are unlabeled, and test images are divided into queries and a few labeled support images per object class of interest. The training and test images do not share object classes. We extend the vanilla GAN with two loss functions, both aimed at self-supervised learning. The first is a reconstruction loss that enforces the discriminator to reconstruct the probabilistically sampled latent code which has been used for generating the ``fake'' image. The second is a triplet loss that enforces the discriminator to output image encodings that are closer for more similar images. Evaluation, comparisons, and detailed ablation studies are done in the context of few-shot classification. Our approach significantly outperforms the state of the art on the Mini-Imagenet and Tiered-Imagenet datasets.
Set-Constrained Viterbi for Set-Supervised Action Segmentation
Feb 27, 2020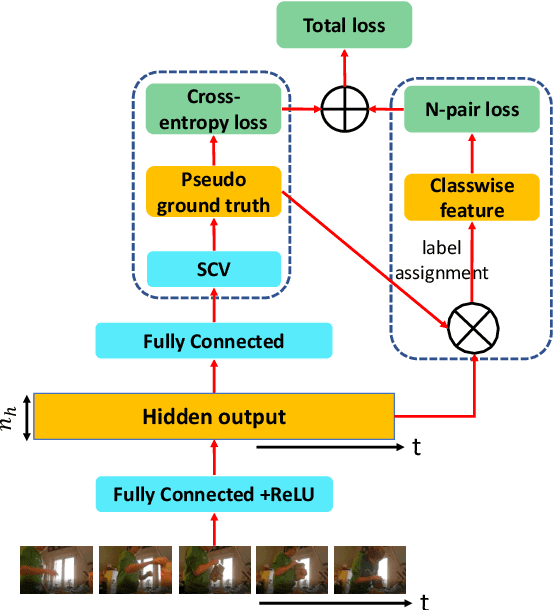



This paper is about weakly supervised action segmentation, where ground truth specifies only a set of actions present in a training video. This problem is more challenging than the standard weakly supervised setting where the temporal ordering of actions is provided. Prior work typically uses a classifier that independently labels video frames for generating the pseudo ground truth, and multiple instance learning for training the classifier. We extend this framework by specifying an HMM, which accounts for co-occurrences of action classes and their temporal lengths, and by explicitly training the HMM on a Viterbi-based loss. Our first contribution is the formulation of a new set-constrained Viterbi algorithm (SCV). Given a video, the SCV generates the MAP action segmentation that satisfies the ground truth. This prediction is used as a framewise pseudo ground truth in our HMM training. Our second contribution is a new regularization of learning by a n-pair loss that regularizes the feature affinity of training videos sharing the same action classes. Evaluation on action segmentation and alignment on the Breakfast, MPII Cooking2, Hollywood Extended datasets demonstrates our significant performance improvement for the two tasks over prior work.