 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSet-Constrained Viterbi for Set-Supervised Action Segmentation
Paper and Code
Feb 27, 2020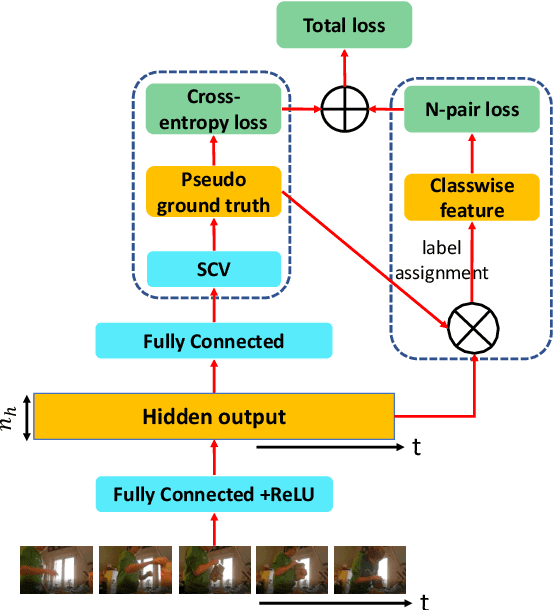



This paper is about weakly supervised action segmentation, where ground truth specifies only a set of actions present in a training video. This problem is more challenging than the standard weakly supervised setting where the temporal ordering of actions is provided. Prior work typically uses a classifier that independently labels video frames for generating the pseudo ground truth, and multiple instance learning for training the classifier. We extend this framework by specifying an HMM, which accounts for co-occurrences of action classes and their temporal lengths, and by explicitly training the HMM on a Viterbi-based loss. Our first contribution is the formulation of a new set-constrained Viterbi algorithm (SCV). Given a video, the SCV generates the MAP action segmentation that satisfies the ground truth. This prediction is used as a framewise pseudo ground truth in our HMM training. Our second contribution is a new regularization of learning by a n-pair loss that regularizes the feature affinity of training videos sharing the same action classes. Evaluation on action segmentation and alignment on the Breakfast, MPII Cooking2, Hollywood Extended datasets demonstrates our significant performance improvement for the two tasks over prior work.