 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIPCOL: Graph-Injected Soft Prompting for Compositional Zero-Shot Learning
Nov 09, 2023



Pre-trained vision-language models (VLMs) have achieved promising success in many fields, especially with prompt learning paradigm. In this work, we propose GIP-COL (Graph-Injected Soft Prompting for COmpositional Learning) to better explore the compositional zero-shot learning (CZSL) ability of VLMs within the prompt-based learning framework. The soft prompt in GIPCOL is structured and consists of the prefix learnable vectors, attribute label and object label. In addition, the attribute and object labels in the soft prompt are designated as nodes in a compositional graph. The compositional graph is constructed based on the compositional structure of the objects and attributes extracted from the training data and consequently feeds the updated concept representation into the soft prompt to capture this compositional structure for a better prompting for CZSL. With the new prompting strategy, GIPCOL achieves state-of-the-art AUC results on all three CZSL benchmarks, including MIT-States, UT-Zappos, and C-GQA datasets in both closed and open settings compared to previous non-CLIP as well as CLIP-based methods. We analyze when and why GIPCOL operates well given the CLIP backbone and its training data limitations, and our findings shed light on designing more effective prompts for CZSL
MetaReVision: Meta-Learning with Retrieval for Visually Grounded Compositional Concept Acquisition
Nov 02, 2023


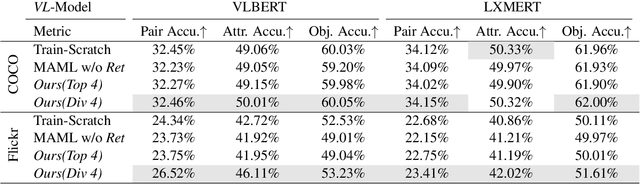
Humans have the ability to learn novel compositional concepts by recalling and generalizing primitive concepts acquired from past experiences. Inspired by this observation, in this paper, we propose MetaReVision, a retrieval-enhanced meta-learning model to address the visually grounded compositional concept learning problem. The proposed MetaReVision consists of a retrieval module and a meta-learning module which are designed to incorporate retrieved primitive concepts as a supporting set to meta-train vision-anguage models for grounded compositional concept recognition. Through meta-learning from episodes constructed by the retriever, MetaReVision learns a generic compositional representation that can be fast updated to recognize novel compositional concepts. We create CompCOCO and CompFlickr to benchmark the grounded compositional concept learning. Our experimental results show that MetaReVision outperforms other competitive baselines and the retrieval module plays an important role in this compositional learning process.
Prompting Large Pre-trained Vision-Language Models For Compositional Concept Learning
Nov 09, 2022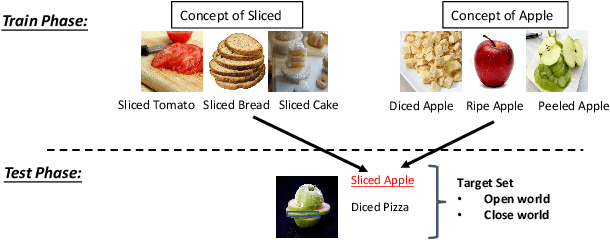

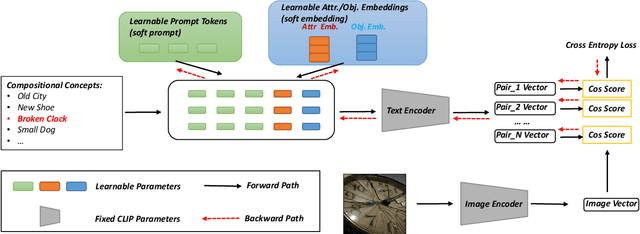
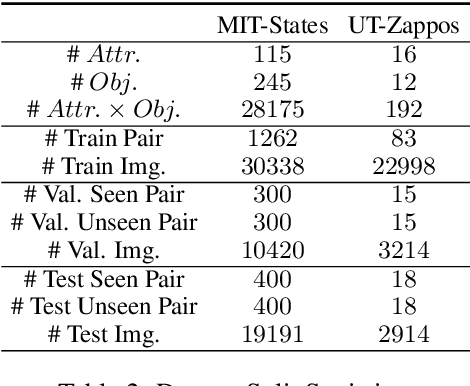
This work explores the zero-shot compositional learning ability of large pre-trained vision-language models(VLMs) within the prompt-based learning framework and propose a model (\textit{PromptCompVL}) to solve the compositonal zero-shot learning (CZSL) problem. \textit{PromptCompVL} makes two design choices: first, it uses a soft-prompting instead of hard-prompting to inject learnable parameters to reprogram VLMs for compositional learning. Second, to address the compositional challenge, it uses the soft-embedding layer to learn primitive concepts in different combinations. By combining both soft-embedding and soft-prompting, \textit{PromptCompVL} achieves state-of-the-art performance on the MIT-States dataset. Furthermore, our proposed model achieves consistent improvement compared to other CLIP-based methods which shows the effectiveness of the proposed prompting strategies for CZSL.
Zero-Shot Compositional Concept Learning
Jul 12, 2021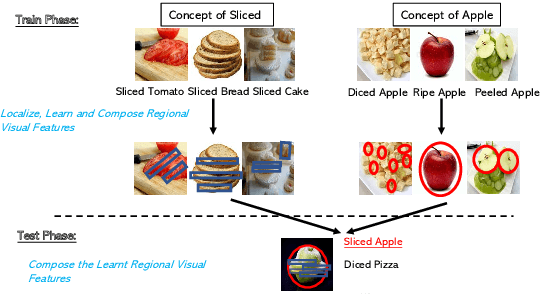
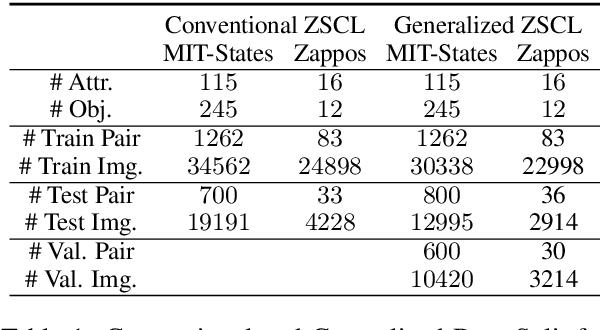

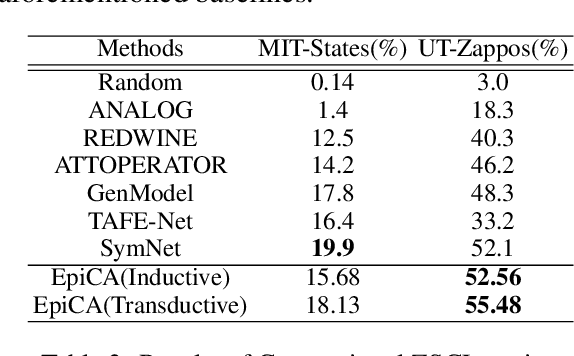
In this paper, we study the problem of recognizing compositional attribute-object concepts within the zero-shot learning (ZSL) framework. We propose an episode-based cross-attention (EpiCA) network which combines merits of cross-attention mechanism and episode-based training strategy to recognize novel compositional concepts. Firstly, EpiCA bases on cross-attention to correlate concept-visual information and utilizes the gated pooling layer to build contextualized representations for both images and concepts. The updated representations are used for a more in-depth multi-modal relevance calculation for concept recognition. Secondly, a two-phase episode training strategy, especially the transductive phase, is adopted to utilize unlabeled test examples to alleviate the low-resource learning problem. Experiments on two widely-used zero-shot compositional learning (ZSCL) benchmarks have demonstrated the effectiveness of the model compared with recent approaches on both conventional and generalized ZSCL settings.