 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting Large Pre-trained Vision-Language Models For Compositional Concept Learning
Paper and Code
Nov 09, 2022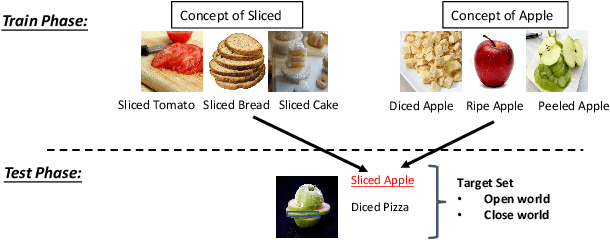

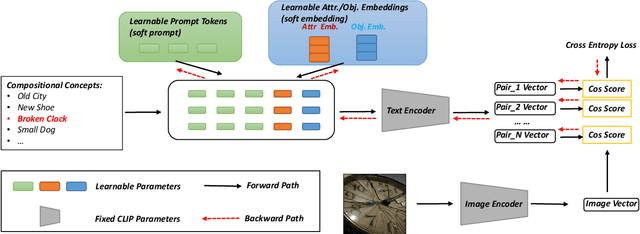
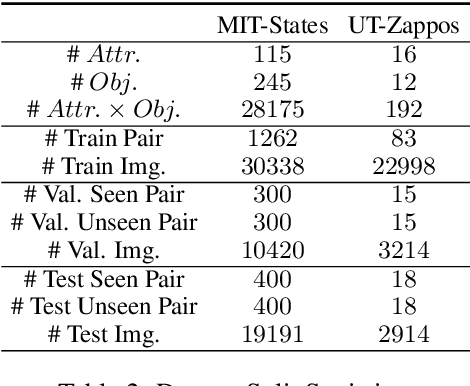
This work explores the zero-shot compositional learning ability of large pre-trained vision-language models(VLMs) within the prompt-based learning framework and propose a model (\textit{PromptCompVL}) to solve the compositonal zero-shot learning (CZSL) problem. \textit{PromptCompVL} makes two design choices: first, it uses a soft-prompting instead of hard-prompting to inject learnable parameters to reprogram VLMs for compositional learning. Second, to address the compositional challenge, it uses the soft-embedding layer to learn primitive concepts in different combinations. By combining both soft-embedding and soft-prompting, \textit{PromptCompVL} achieves state-of-the-art performance on the MIT-States dataset. Furthermore, our proposed model achieves consistent improvement compared to other CLIP-based methods which shows the effectiveness of the proposed prompting strategies for CZSL.