 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Procedural Mistake Detection
Dec 16, 2024Automated task guidance has recently attracted attention from the AI research community. Procedural mistake detection (PMD) is a challenging sub-problem of classifying whether a human user (observed through egocentric video) has successfully executed the task at hand (specified by a procedural text). Despite significant efforts in building resources and models for PMD, machine performance remains nonviable, and the reasoning processes underlying this performance are opaque. As such, we recast PMD to an explanatory self-dialog of questions and answers, which serve as evidence for a decision. As this reformulation enables an unprecedented transparency, we leverage a fine-tuned natural language inference (NLI) model to formulate two automated coherence metrics for generated explanations. Our results show that while open-source VLMs struggle with this task off-the-shelf, their accuracy, coherence, and dialog efficiency can be vastly improved by incorporating these coherence metrics into common inference and fine-tuning methods. Furthermore, our multi-faceted metrics can visualize common outcomes at a glance, highlighting areas for improvement.
Can Foundation Models Watch, Talk and Guide You Step by Step to Make a Cake?
Nov 01, 2023Despite tremendous advances in AI, it remains a significant challenge to develop interactive task guidance systems that can offer situated, personalized guidance and assist humans in various tasks. These systems need to have a sophisticated understanding of the user as well as the environment, and make timely accurate decisions on when and what to say. To address this issue, we created a new multimodal benchmark dataset, Watch, Talk and Guide (WTaG) based on natural interaction between a human user and a human instructor. We further proposed two tasks: User and Environment Understanding, and Instructor Decision Making. We leveraged several foundation models to study to what extent these models can be quickly adapted to perceptually enabled task guidance. Our quantitative, qualitative, and human evaluation results show that these models can demonstrate fair performances in some cases with no task-specific training, but a fast and reliable adaptation remains a significant challenge. Our benchmark and baselines will provide a stepping stone for future work on situated task guidance.
From Heuristic to Analytic: Cognitively Motivated Strategies for Coherent Physical Commonsense Reasoning
Oct 24, 2023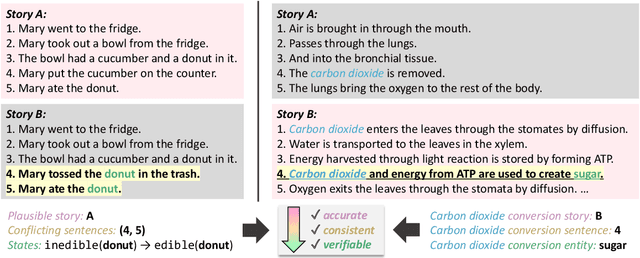
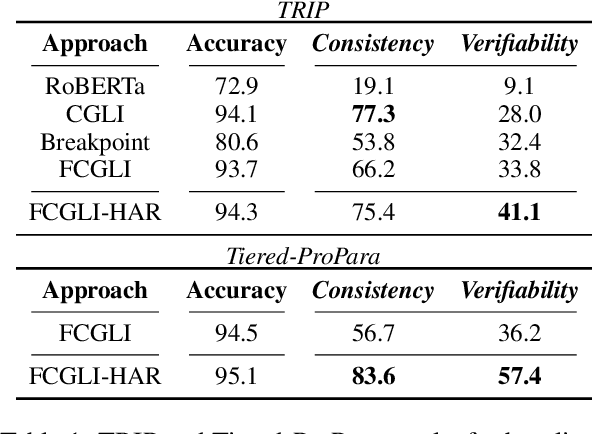
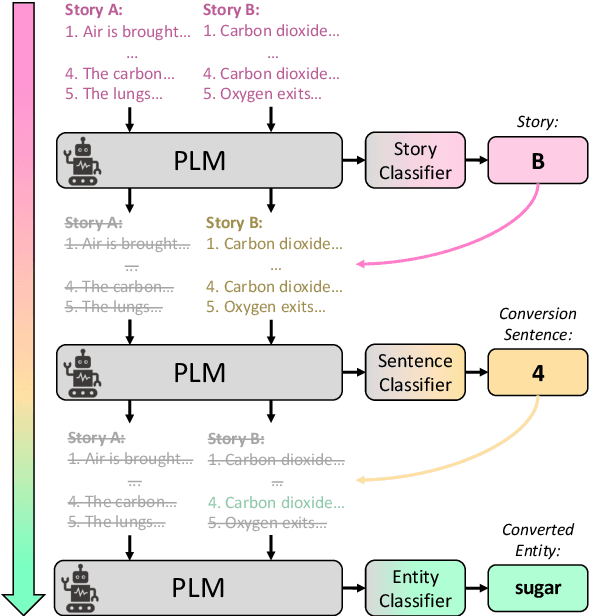
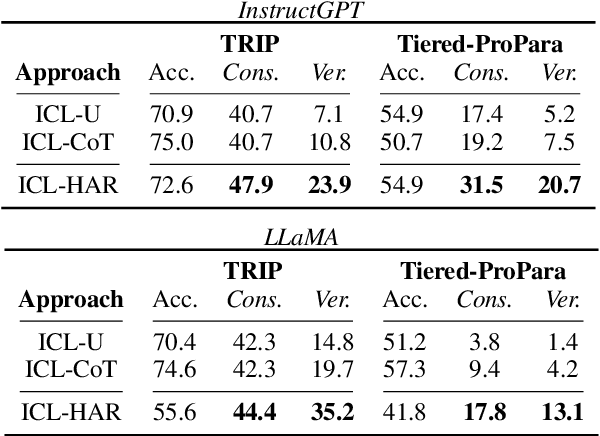
Pre-trained language models (PLMs) have shown impressive performance in various language tasks. However, they are prone to spurious correlations, and often generate illusory information. In real-world applications, PLMs should justify decisions with formalized, coherent reasoning chains, but this challenge remains under-explored. Cognitive psychology theorizes that humans are capable of utilizing fast and intuitive heuristic thinking to make decisions based on past experience, then rationalizing the decisions through slower and deliberative analytic reasoning. We incorporate these interlinked dual processes in fine-tuning and in-context learning with PLMs, applying them to two language understanding tasks that require coherent physical commonsense reasoning. We show that our proposed Heuristic-Analytic Reasoning (HAR) strategies drastically improve the coherence of rationalizations for model decisions, yielding state-of-the-art results on Tiered Reasoning for Intuitive Physics (TRIP). We also find that this improved coherence is a direct result of more faithful attention to relevant language context in each step of reasoning. Our findings suggest that human-like reasoning strategies can effectively improve the coherence and reliability of PLM reasoning.
In-Context Analogical Reasoning with Pre-Trained Language Models
Jun 05, 2023
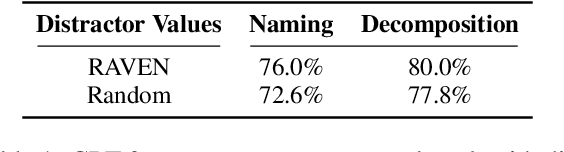

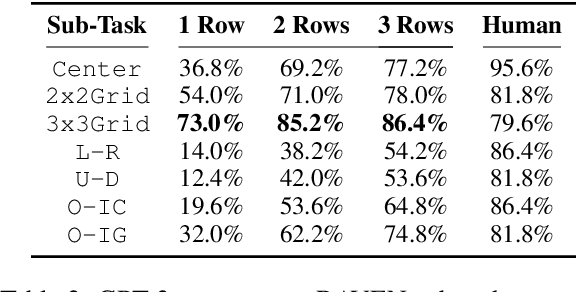
Analogical reasoning is a fundamental capacity of human cognition that allows us to reason abstractly about novel situations by relating them to past experiences. While it is thought to be essential for robust reasoning in AI systems, conventional approaches require significant training and/or hard-coding of domain knowledge to be applied to benchmark tasks. Inspired by cognitive science research that has found connections between human language and analogy-making, we explore the use of intuitive language-based abstractions to support analogy in AI systems. Specifically, we apply large pre-trained language models (PLMs) to visual Raven's Progressive Matrices (RPM), a common relational reasoning test. By simply encoding the perceptual features of the problem into language form, we find that PLMs exhibit a striking capacity for zero-shot relational reasoning, exceeding human performance and nearing supervised vision-based methods. We explore different encodings that vary the level of abstraction over task features, finding that higher-level abstractions further strengthen PLMs' analogical reasoning. Our detailed analysis reveals insights on the role of model complexity, in-context learning, and prior knowledge in solving RPM tasks.
NLP Reproducibility For All: Understanding Experiences of Beginners
Jun 03, 2023



As natural language processing (NLP) has recently seen an unprecedented level of excitement, and more people are eager to enter the field, it is unclear whether current research reproducibility efforts are sufficient for this group of beginners to apply the latest developments. To understand their needs, we conducted a study with 93 students in an introductory NLP course, where students reproduced the results of recent NLP papers. Surprisingly, we find that their programming skill and comprehension of research papers have a limited impact on their effort spent completing the exercise. Instead, we find accessibility efforts by research authors to be the key to success, including complete documentation, better coding practice, and easier access to data files. Going forward, we recommend that NLP researchers pay close attention to these simple aspects of open-sourcing their work, and use insights from beginners' feedback to provide actionable ideas on how to better support them.
DANLI: Deliberative Agent for Following Natural Language Instructions
Oct 22, 2022



Recent years have seen an increasing amount of work on embodied AI agents that can perform tasks by following human language instructions. However, most of these agents are reactive, meaning that they simply learn and imitate behaviors encountered in the training data. These reactive agents are insufficient for long-horizon complex tasks. To address this limitation, we propose a neuro-symbolic deliberative agent that, while following language instructions, proactively applies reasoning and planning based on its neural and symbolic representations acquired from past experience (e.g., natural language and egocentric vision). We show that our deliberative agent achieves greater than 70% improvement over reactive baselines on the challenging TEACh benchmark. Moreover, the underlying reasoning and planning processes, together with our modular framework, offer impressive transparency and explainability to the behaviors of the agent. This enables an in-depth understanding of the agent's capabilities, which shed light on challenges and opportunities for future embodied agents for instruction following. The code is available at https://github.com/sled-group/DANLI.
Reproducibility Beyond the Research Community: Experience from NLP Beginners
May 05, 2022



As NLP research attracts public attention and excitement, it becomes increasingly important for it to be accessible to a broad audience. As the research community works to democratize NLP, it remains unclear whether beginners to the field can easily apply the latest developments. To understand their needs, we conducted a study with 93 students in an introductory NLP course, where students reproduced results of recent NLP papers. Surprisingly, our results suggest that their technical skill (i.e., programming experience) has limited impact on their effort spent completing the exercise. Instead, we find accessibility efforts by research authors to be key to a successful experience, including thorough documentation and easy access to required models and datasets.
Best of Both Worlds: A Hybrid Approach for Multi-Hop Explanation with Declarative Facts
Dec 17, 2021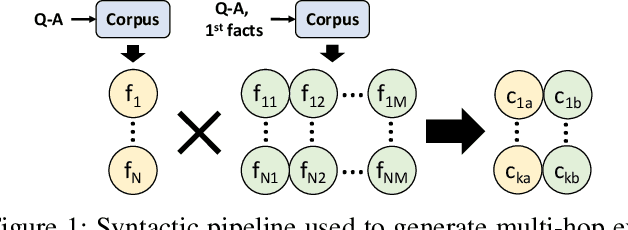
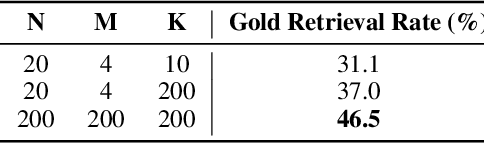
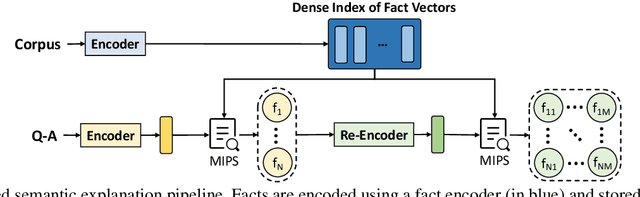
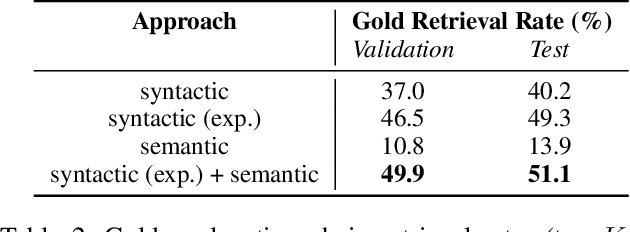
Language-enabled AI systems can answer complex, multi-hop questions to high accuracy, but supporting answers with evidence is a more challenging task which is important for the transparency and trustworthiness to users. Prior work in this area typically makes a trade-off between efficiency and accuracy; state-of-the-art deep neural network systems are too cumbersome to be useful in large-scale applications, while the fastest systems lack reliability. In this work, we integrate fast syntactic methods with powerful semantic methods for multi-hop explanation generation based on declarative facts. Our best system, which learns a lightweight operation to simulate multi-hop reasoning over pieces of evidence and fine-tunes language models to re-rank generated explanation chains, outperforms a purely syntactic baseline from prior work by up to 7% in gold explanation retrieval rate.
Tiered Reasoning for Intuitive Physics: Toward Verifiable Commonsense Language Understanding
Sep 10, 2021
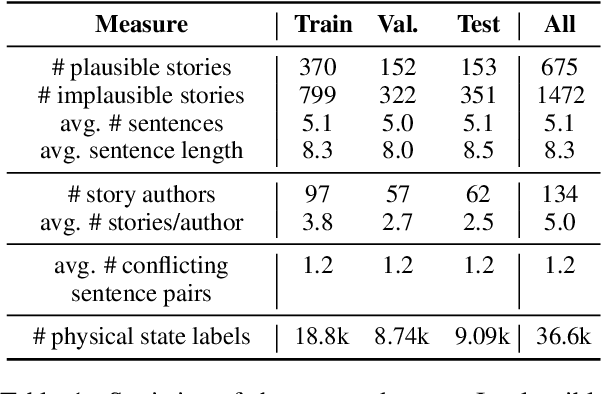

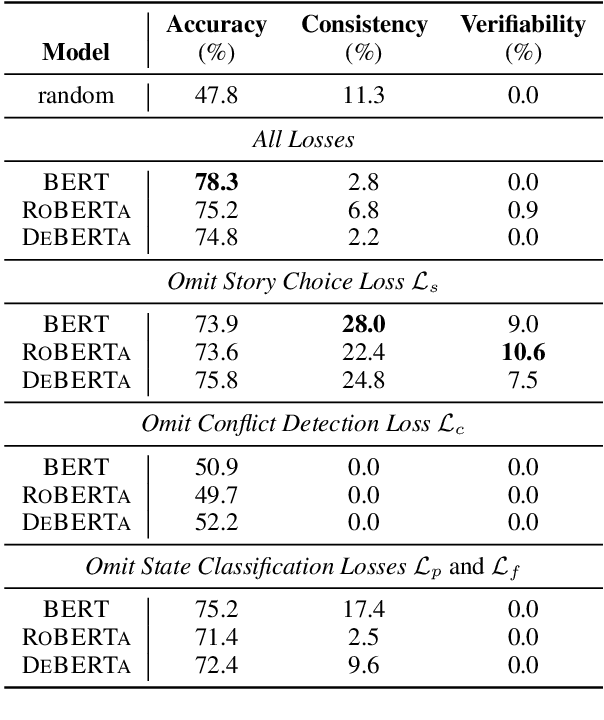
Large-scale, pre-trained language models (LMs) have achieved human-level performance on a breadth of language understanding tasks. However, evaluations only based on end task performance shed little light on machines' true ability in language understanding and reasoning. In this paper, we highlight the importance of evaluating the underlying reasoning process in addition to end performance. Toward this goal, we introduce Tiered Reasoning for Intuitive Physics (TRIP), a novel commonsense reasoning dataset with dense annotations that enable multi-tiered evaluation of machines' reasoning process. Our empirical results show that while large LMs can achieve high end performance, they struggle to support their predictions with valid supporting evidence. The TRIP dataset and our baseline results will motivate verifiable evaluation of commonsense reasoning and facilitate future research toward developing better language understanding and reasoning models.
Beyond the Tip of the Iceberg: Assessing Coherence of Text Classifiers
Sep 10, 2021


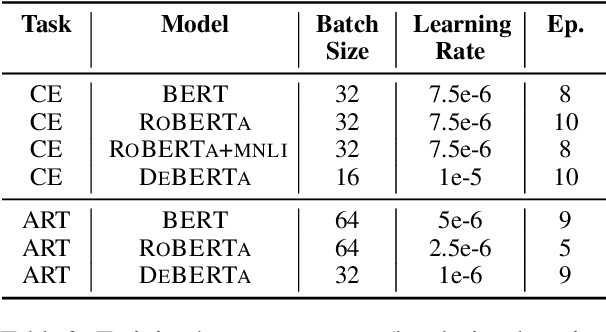
As large-scale, pre-trained language models achieve human-level and superhuman accuracy on existing language understanding tasks, statistical bias in benchmark data and probing studies have recently called into question their true capabilities. For a more informative evaluation than accuracy on text classification tasks can offer, we propose evaluating systems through a novel measure of prediction coherence. We apply our framework to two existing language understanding benchmarks with different properties to demonstrate its versatility. Our experimental results show that this evaluation framework, although simple in ideas and implementation, is a quick, effective, and versatile measure to provide insight into the coherence of machines' predictions.