 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied4C: Measuring What Matters for Embodied Vision-Language Navigation
Dec 19, 2025Vision-language navigation requires agents to reason and act under constraints of embodiment. While vision-language models (VLMs) demonstrate strong generalization, current benchmarks provide limited understanding of how embodiment -- i.e., the choice of physical platform, sensor configuration, and modality alignment -- influences perception, reasoning, and control. We introduce Embodied4C, a closed-loop benchmark designed as a Turing test for embodied reasoning. The benchmark evaluates the core embodied capabilities of VLMs across three heterogeneous embodiments -- autonomous vehicles, aerial drones, and robotic manipulators -- through approximately 1.1K one-shot reasoning questions and 58 goal-directed navigation tasks. These tasks jointly assess four foundational dimensions: semantic, spatial, temporal, and physical reasoning. Each embodiment presents dynamic sensor configurations and environment variations to probe generalization beyond platform-specific adaptation. To prevent embodiment overfitting, Embodied4C integrates domain-far queries targeting abstract and cross-context reasoning. Comprehensive evaluation across ten state-of-the-art VLMs and four embodied control baselines shows that cross-modal alignment and instruction tuning matter more than scale, while spatial and temporal reasoning remains the primary bottleneck for reliable embodied competence.
SNOW: Spatio-Temporal Scene Understanding with World Knowledge for Open-World Embodied Reasoning
Dec 18, 2025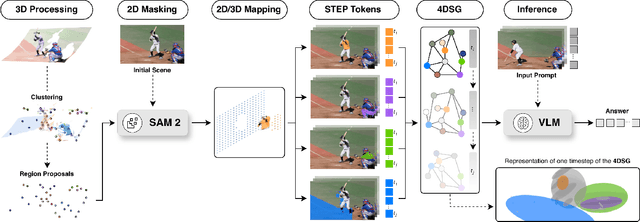
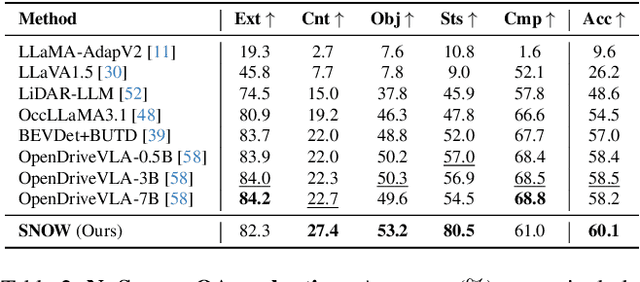
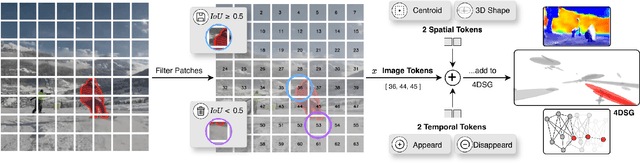
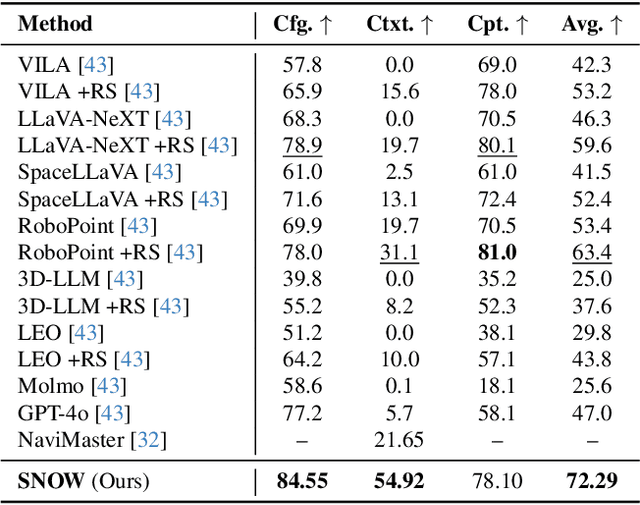
Autonomous robotic systems require spatio-temporal understanding of dynamic environments to ensure reliable navigation and interaction. While Vision-Language Models (VLMs) provide open-world semantic priors, they lack grounding in 3D geometry and temporal dynamics. Conversely, geometric perception captures structure and motion but remains semantically sparse. We propose SNOW (Scene Understanding with Open-World Knowledge), a training-free and backbone-agnostic framework for unified 4D scene understanding that integrates VLM-derived semantics with point cloud geometry and temporal consistency. SNOW processes synchronized RGB images and 3D point clouds, using HDBSCAN clustering to generate object-level proposals that guide SAM2-based segmentation. Each segmented region is encoded through our proposed Spatio-Temporal Tokenized Patch Encoding (STEP), producing multimodal tokens that capture localized semantic, geometric, and temporal attributes. These tokens are incrementally integrated into a 4D Scene Graph (4DSG), which serves as 4D prior for downstream reasoning. A lightweight SLAM backend anchors all STEP tokens spatially in the environment, providing the global reference alignment, and ensuring unambiguous spatial grounding across time. The resulting 4DSG forms a queryable, unified world model through which VLMs can directly interpret spatial scene structure and temporal dynamics. Experiments on a diverse set of benchmarks demonstrate that SNOW enables precise 4D scene understanding and spatially grounded inference, thereby setting new state-of-the-art performance in several settings, highlighting the importance of structured 4D priors for embodied reasoning and autonomous robotics.
R4: Retrieval-Augmented Reasoning for Vision-Language Models in 4D Spatio-Temporal Space
Dec 17, 2025Humans perceive and reason about their surroundings in four dimensions by building persistent, structured internal representations that encode semantic meaning, spatial layout, and temporal dynamics. These multimodal memories enable them to recall past events, infer unobserved states, and integrate new information into context-dependent reasoning. Inspired by this capability, we introduce R4, a training-free framework for retrieval-augmented reasoning in 4D spatio-temporal space that equips vision-language models (VLMs) with structured, lifelong memory. R4 continuously constructs a 4D knowledge database by anchoring object-level semantic descriptions in metric space and time, yielding a persistent world model that can be shared across agents. At inference, natural language queries are decomposed into semantic, spatial, and temporal keys to retrieve relevant observations, which are integrated into the VLM's reasoning. Unlike classical retrieval-augmented generation methods, retrieval in R4 operates directly in 4D space, enabling episodic and collaborative reasoning without training. Experiments on embodied question answering and navigation benchmarks demonstrate that R4 substantially improves retrieval and reasoning over spatio-temporal information compared to baselines, advancing a new paradigm for embodied 4D reasoning in dynamic environments.
When to Think and When to Look: Uncertainty-Guided Lookback
Nov 19, 2025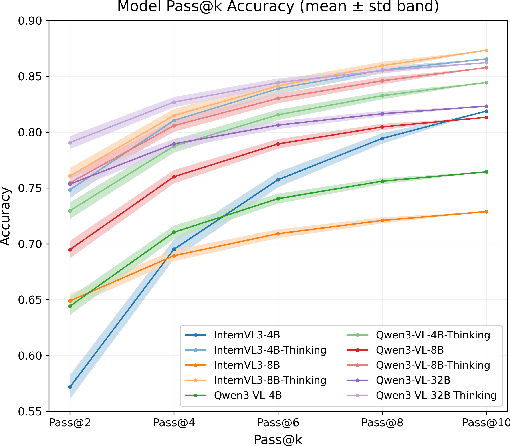

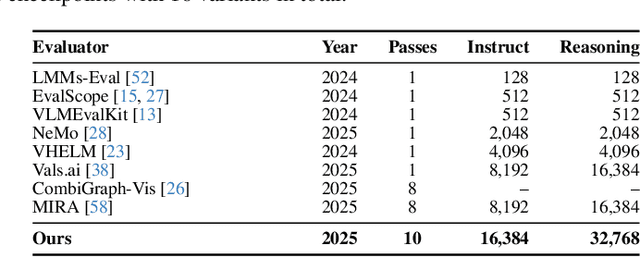
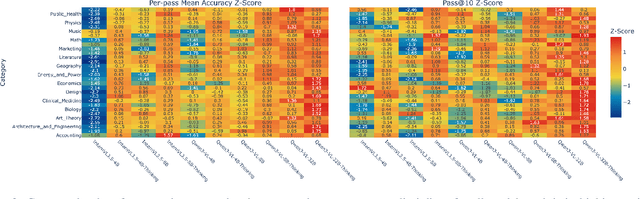
Test-time thinking (that is, generating explicit intermediate reasoning chains) is known to boost performance in large language models and has recently shown strong gains for large vision language models (LVLMs). However, despite these promising results, there is still no systematic analysis of how thinking actually affects visual reasoning. We provide the first such analysis with a large scale, controlled comparison of thinking for LVLMs, evaluating ten variants from the InternVL3.5 and Qwen3-VL families on MMMU-val under generous token budgets and multi pass decoding. We show that more thinking is not always better; long chains often yield long wrong trajectories that ignore the image and underperform the same models run in standard instruct mode. A deeper analysis reveals that certain short lookback phrases, which explicitly refer back to the image, are strongly enriched in successful trajectories and correlate with better visual grounding. Building on this insight, we propose uncertainty guided lookback, a training free decoding strategy that combines an uncertainty signal with adaptive lookback prompts and breadth search. Our method improves overall MMMU performance, delivers the largest gains in categories where standard thinking is weak, and outperforms several strong decoding baselines, setting a new state of the art under fixed model families and token budgets. We further show that this decoding strategy generalizes, yielding consistent improvements on five additional benchmarks, including two broad multimodal suites and math focused visual reasoning datasets.
A Framework for a Capability-driven Evaluation of Scenario Understanding for Multimodal Large Language Models in Autonomous Driving
Mar 14, 2025Multimodal large language models (MLLMs) hold the potential to enhance autonomous driving by combining domain-independent world knowledge with context-specific language guidance. Their integration into autonomous driving systems shows promising results in isolated proof-of-concept applications, while their performance is evaluated on selective singular aspects of perception, reasoning, or planning. To leverage their full potential a systematic framework for evaluating MLLMs in the context of autonomous driving is required. This paper proposes a holistic framework for a capability-driven evaluation of MLLMs in autonomous driving. The framework structures scenario understanding along the four core capability dimensions semantic, spatial, temporal, and physical. They are derived from the general requirements of autonomous driving systems, human driver cognition, and language-based reasoning. It further organises the domain into context layers, processing modalities, and downstream tasks such as language-based interaction and decision-making. To illustrate the framework's applicability, two exemplary traffic scenarios are analysed, grounding the proposed dimensions in realistic driving situations. The framework provides a foundation for the structured evaluation of MLLMs' potential for scenario understanding in autonomous driving.
Measuring Physical Plausibility of 3D Human Poses Using Physics Simulation
Feb 06, 2025



Modeling humans in physical scenes is vital for understanding human-environment interactions for applications involving augmented reality or assessment of human actions from video (e.g. sports or physical rehabilitation). State-of-the-art literature begins with a 3D human pose, from monocular or multiple views, and uses this representation to ground the person within a 3D world space. While standard metrics for accuracy capture joint position errors, they do not consider physical plausibility of the 3D pose. This limitation has motivated researchers to propose other metrics evaluating jitter, floor penetration, and unbalanced postures. Yet, these approaches measure independent instances of errors and are not representative of balance or stability during motion. In this work, we propose measuring physical plausibility from within physics simulation. We introduce two metrics to capture the physical plausibility and stability of predicted 3D poses from any 3D Human Pose Estimation model. Using physics simulation, we discover correlations with existing plausibility metrics and measuring stability during motion. We evaluate and compare the performances of two state-of-the-art methods, a multi-view triangulated baseline, and ground truth 3D markers from the Human3.6m dataset.
VITRO: Vocabulary Inversion for Time-series Representation Optimization
Dec 23, 2024Although LLMs have demonstrated remarkable capabilities in processing and generating textual data, their pre-trained vocabularies are ill-suited for capturing the nuanced temporal dynamics and patterns inherent in time series. The discrete, symbolic nature of natural language tokens, which these vocabularies are designed to represent, does not align well with the continuous, numerical nature of time series data. To address this fundamental limitation, we propose VITRO. Our method adapts textual inversion optimization from the vision-language domain in order to learn a new time series per-dataset vocabulary that bridges the gap between the discrete, semantic nature of natural language and the continuous, numerical nature of time series data. We show that learnable time series-specific pseudo-word embeddings represent time series data better than existing general language model vocabularies, with VITRO-enhanced methods achieving state-of-the-art performance in long-term forecasting across most datasets.
Explainable Procedural Mistake Detection
Dec 16, 2024Automated task guidance has recently attracted attention from the AI research community. Procedural mistake detection (PMD) is a challenging sub-problem of classifying whether a human user (observed through egocentric video) has successfully executed the task at hand (specified by a procedural text). Despite significant efforts in building resources and models for PMD, machine performance remains nonviable, and the reasoning processes underlying this performance are opaque. As such, we recast PMD to an explanatory self-dialog of questions and answers, which serve as evidence for a decision. As this reformulation enables an unprecedented transparency, we leverage a fine-tuned natural language inference (NLI) model to formulate two automated coherence metrics for generated explanations. Our results show that while open-source VLMs struggle with this task off-the-shelf, their accuracy, coherence, and dialog efficiency can be vastly improved by incorporating these coherence metrics into common inference and fine-tuning methods. Furthermore, our multi-faceted metrics can visualize common outcomes at a glance, highlighting areas for improvement.
Instructional Video Generation
Dec 05, 2024



Despite the recent strides in video generation, state-of-the-art methods still struggle with elements of visual detail. One particularly challenging case is the class of egocentric instructional videos in which the intricate motion of the hand coupled with a mostly stable and non-distracting environment is necessary to convey the appropriate visual action instruction. To address these challenges, we introduce a new method for instructional video generation. Our diffusion-based method incorporates two distinct innovations. First, we propose an automatic method to generate the expected region of motion, guided by both the visual context and the action text. Second, we introduce a critical hand structure loss to guide the diffusion model to focus on smooth and consistent hand poses. We evaluate our method on augmented instructional datasets based on EpicKitchens and Ego4D, demonstrating significant improvements over state-of-the-art methods in terms of instructional clarity, especially of the hand motion in the target region, across diverse environments and actions.Video results can be found on the project webpage: https://excitedbutter.github.io/Instructional-Video-Generation/
Class-wise Autoencoders Measure Classification Difficulty And Detect Label Mistakes
Dec 03, 2024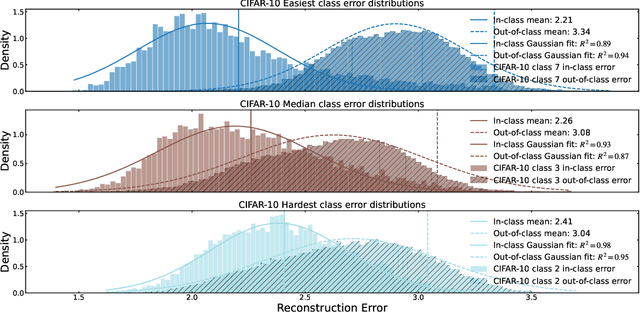
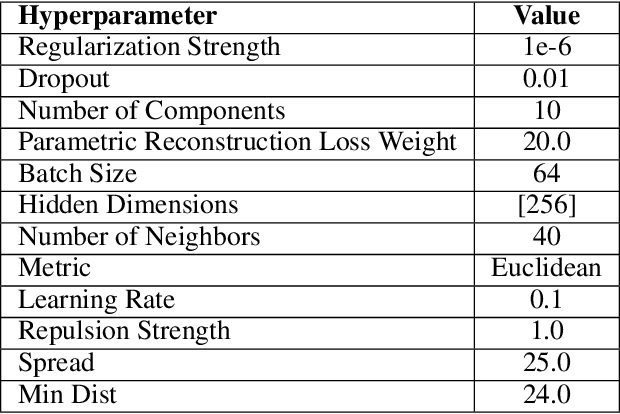

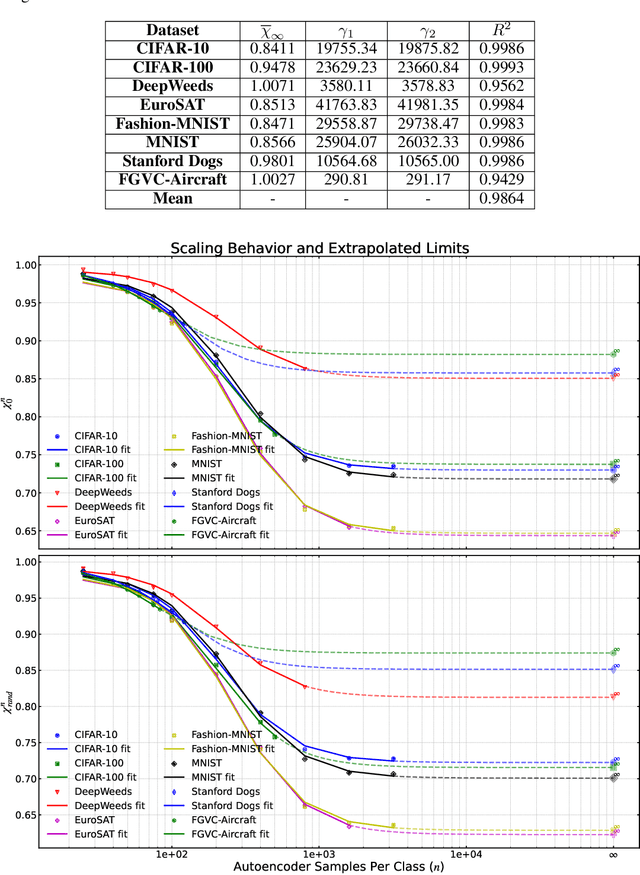
We introduce a new framework for analyzing classification datasets based on the ratios of reconstruction errors between autoencoders trained on individual classes. This analysis framework enables efficient characterization of datasets on the sample, class, and entire dataset levels. We define reconstruction error ratios (RERs) that probe classification difficulty and allow its decomposition into (1) finite sample size and (2) Bayes error and decision-boundary complexity. Through systematic study across 19 popular visual datasets, we find that our RER-based dataset difficulty probe strongly correlates with error rate for state-of-the-art (SOTA) classification models. By interpreting sample-level classification difficulty as a label mistakenness score, we further find that RERs achieve SOTA performance on mislabel detection tasks on hard datasets under symmetric and asymmetric label noise. Our code is publicly available at https://github.com/voxel51/reconstruction-error-ratios.