 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Tokenization Strategies for Event Sequence Modeling with Large Language Models
Dec 16, 2025Representing continuous time is a critical and under-explored challenge in modeling temporal event sequences with large language models (LLMs). Various strategies like byte-level representations or calendar tokens have been proposed. However, the optimal approach remains unclear, especially given the diverse statistical distributions of real-world event data, which range from smooth log-normal to discrete, spiky patterns. This paper presents the first empirical study of temporal tokenization for event sequences, comparing distinct encoding strategies: naive numeric strings, high-precision byte-level representations, human-semantic calendar tokens, classic uniform binning, and adaptive residual scalar quantization. We evaluate these strategies by fine-tuning LLMs on real-world datasets that exemplify these diverse distributions. Our analysis reveals that no single strategy is universally superior; instead, prediction performance depends heavily on aligning the tokenizer with the data's statistical properties, with log-based strategies excelling on skewed distributions and human-centric formats proving robust for mixed modalities.
VITRO: Vocabulary Inversion for Time-series Representation Optimization
Dec 23, 2024Although LLMs have demonstrated remarkable capabilities in processing and generating textual data, their pre-trained vocabularies are ill-suited for capturing the nuanced temporal dynamics and patterns inherent in time series. The discrete, symbolic nature of natural language tokens, which these vocabularies are designed to represent, does not align well with the continuous, numerical nature of time series data. To address this fundamental limitation, we propose VITRO. Our method adapts textual inversion optimization from the vision-language domain in order to learn a new time series per-dataset vocabulary that bridges the gap between the discrete, semantic nature of natural language and the continuous, numerical nature of time series data. We show that learnable time series-specific pseudo-word embeddings represent time series data better than existing general language model vocabularies, with VITRO-enhanced methods achieving state-of-the-art performance in long-term forecasting across most datasets.
Scaling-laws for Large Time-series Models
May 22, 2024Scaling laws for large language models (LLMs) have provided useful guidance on how to train ever larger models for predictable performance gains. Time series forecasting shares a similar sequential structure to language, and is amenable to large-scale transformer architectures. Here we show that foundational decoder-only time series transformer models exhibit analogous scaling-behavior to LLMs, while architectural details (aspect ratio and number of heads) have a minimal effect over broad ranges. We assemble a large corpus of heterogenous time series data on which to train, and establish, for the first time, power-law scaling relations with respect to parameter count, dataset size, and training compute, spanning five orders of magnitude.
Tiny Time Mixers : Fast Pre-trained Models for Enhanced Zero/Few-Shot Forecasting of Multivariate Time Series
Jan 17, 2024Large pre-trained models for zero/few-shot learning excel in language and vision domains but encounter challenges in multivariate time series (TS) due to the diverse nature and scarcity of publicly available pre-training data. Consequently, there has been a recent surge in utilizing pre-trained large language models (LLMs) with token adaptations for TS forecasting. These approaches employ cross-domain transfer learning and surprisingly yield impressive results. However, these models are typically very slow and large (~billion parameters) and do not consider cross-channel correlations. To address this, we present Tiny Time Mixers (TTM), a significantly small model based on the lightweight TSMixer architecture. TTM marks the first success in developing fast and tiny general pre-trained models (<1M parameters), exclusively trained on public TS datasets, with effective transfer learning capabilities for forecasting. To tackle the complexity of pre-training on multiple datasets with varied temporal resolutions, we introduce several novel enhancements such as adaptive patching, dataset augmentation via downsampling, and resolution prefix tuning. Moreover, we employ a multi-level modeling strategy to effectively model channel correlations and infuse exogenous signals during fine-tuning, a crucial capability lacking in existing benchmarks. TTM shows significant accuracy gains (12-38\%) over popular benchmarks in few/zero-shot forecasting. It also drastically reduces the compute needs as compared to LLM-TS methods, with a 14X cut in learnable parameters, 106X less total parameters, and substantial reductions in fine-tuning (65X) and inference time (54X). In fact, TTM's zero-shot often surpasses the few-shot results in many popular benchmarks, highlighting the efficacy of our approach. Code and pre-trained models will be open-sourced.
AutoMixer for Improved Multivariate Time-Series Forecasting on Business and IT Observability Data
Nov 02, 2023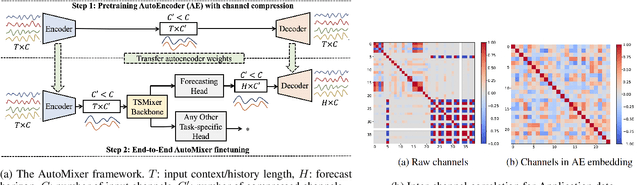
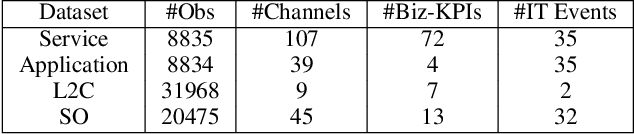
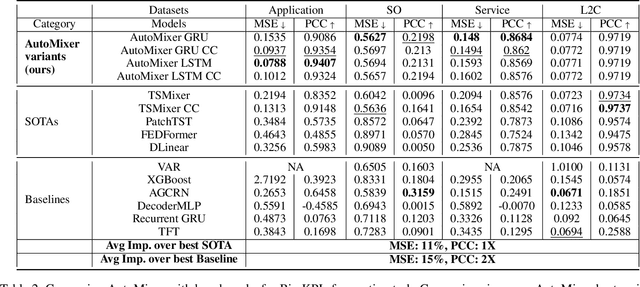
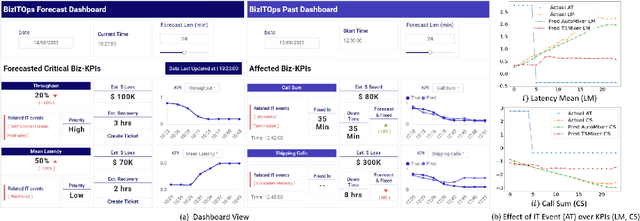
The efficiency of business processes relies on business key performance indicators (Biz-KPIs), that can be negatively impacted by IT failures. Business and IT Observability (BizITObs) data fuses both Biz-KPIs and IT event channels together as multivariate time series data. Forecasting Biz-KPIs in advance can enhance efficiency and revenue through proactive corrective measures. However, BizITObs data generally exhibit both useful and noisy inter-channel interactions between Biz-KPIs and IT events that need to be effectively decoupled. This leads to suboptimal forecasting performance when existing multivariate forecasting models are employed. To address this, we introduce AutoMixer, a time-series Foundation Model (FM) approach, grounded on the novel technique of channel-compressed pretrain and finetune workflows. AutoMixer leverages an AutoEncoder for channel-compressed pretraining and integrates it with the advanced TSMixer model for multivariate time series forecasting. This fusion greatly enhances the potency of TSMixer for accurate forecasts and also generalizes well across several downstream tasks. Through detailed experiments and dashboard analytics, we show AutoMixer's capability to consistently improve the Biz-KPI's forecasting accuracy (by 11-15\%) which directly translates to actionable business insights.
ST-MLP: A Cascaded Spatio-Temporal Linear Framework with Channel-Independence Strategy for Traffic Forecasting
Aug 14, 2023The criticality of prompt and precise traffic forecasting in optimizing traffic flow management in Intelligent Transportation Systems (ITS) has drawn substantial scholarly focus. Spatio-Temporal Graph Neural Networks (STGNNs) have been lauded for their adaptability to road graph structures. Yet, current research on STGNNs architectures often prioritizes complex designs, leading to elevated computational burdens with only minor enhancements in accuracy. To address this issue, we propose ST-MLP, a concise spatio-temporal model solely based on cascaded Multi-Layer Perceptron (MLP) modules and linear layers. Specifically, we incorporate temporal information, spatial information and predefined graph structure with a successful implementation of the channel-independence strategy - an effective technique in time series forecasting. Empirical results demonstrate that ST-MLP outperforms state-of-the-art STGNNs and other models in terms of accuracy and computational efficiency. Our finding encourages further exploration of more concise and effective neural network architectures in the field of traffic forecasting.
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Nov 27, 2022We propose an efficient design of Transformer-based models for multivariate time series forecasting and self-supervised representation learning. It is based on two key components: (i) segmentation of time series into subseries-level patches which are served as input tokens to Transformer; (ii) channel-independence where each channel contains a single univariate time series that shares the same embedding and Transformer weights across all the series. Patching design naturally has three-fold benefit: local semantic information is retained in the embedding; computation and memory usage of the attention maps are quadratically reduced given the same look-back window; and the model can attend longer history. Our channel-independent patch time series Transformer (PatchTST) can improve the long-term forecasting accuracy significantly when compared with that of SOTA Transformer-based models. We also apply our model to self-supervised pre-training tasks and attain excellent fine-tuning performance, which outperforms supervised training on large datasets. Transferring of masked pre-trained representation on one dataset to others also produces SOTA forecasting accuracy. Code is available at: https://github.com/yuqinie98/PatchTST.
A Strong Baseline for Vehicle Re-Identification
Apr 22, 2021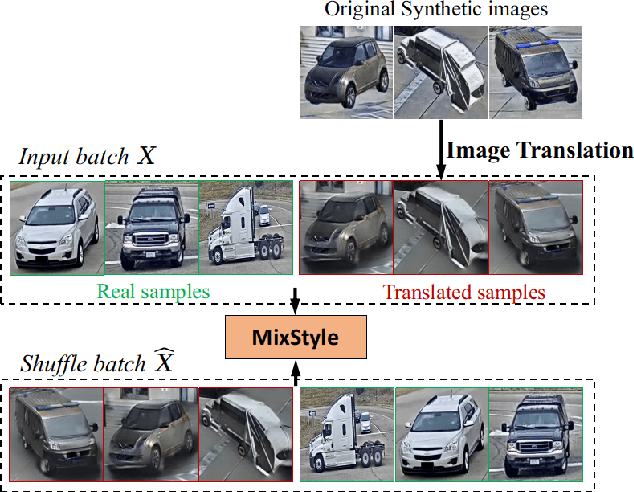

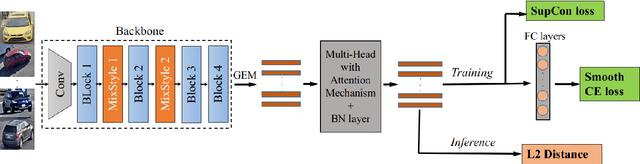
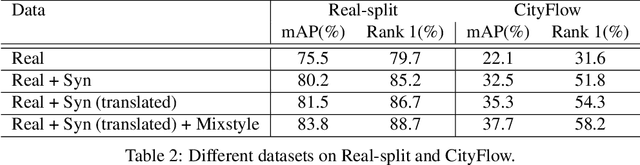
Vehicle Re-Identification (Re-ID) aims to identify the same vehicle across different cameras, hence plays an important role in modern traffic management systems. The technical challenges require the algorithms must be robust in different views, resolution, occlusion and illumination conditions. In this paper, we first analyze the main factors hindering the Vehicle Re-ID performance. We then present our solutions, specifically targeting the dataset Track 2 of the 5th AI City Challenge, including (1) reducing the domain gap between real and synthetic data, (2) network modification by stacking multi heads with attention mechanism, (3) adaptive loss weight adjustment. Our method achieves 61.34% mAP on the private CityFlow testset without using external dataset or pseudo labeling, and outperforms all previous works at 87.1% mAP on the Veri benchmark. The code is available at https://github.com/cybercore-co-ltd/track2_aicity_2021.
Experimental evaluation of quantum Bayesian networks on IBM QX hardware
May 26, 2020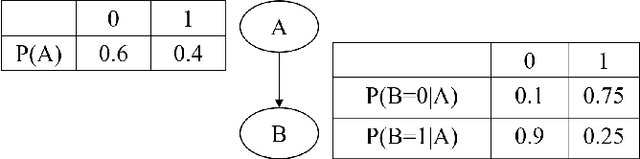
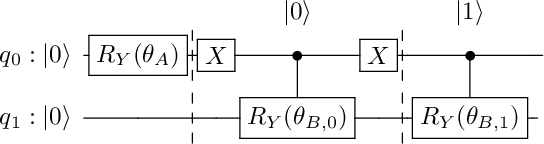
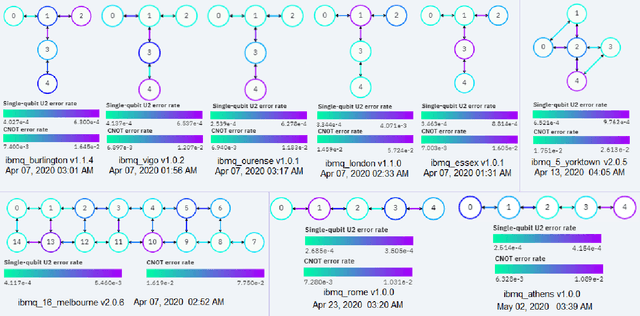
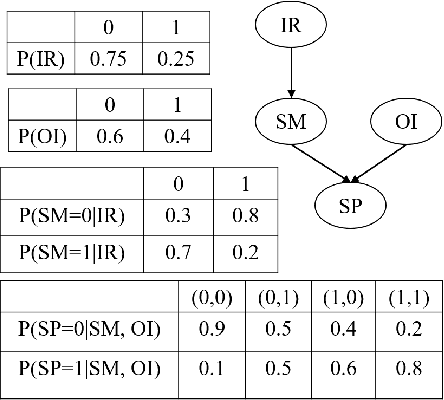
Bayesian Networks (BN) are probabilistic graphical models that are widely used for uncertainty modeling, stochastic prediction and probabilistic inference. A Quantum Bayesian Network (QBN) is a quantum version of the Bayesian network that utilizes the principles of quantum mechanical systems to improve the computational performance of various analyses. In this paper, we experimentally evaluate the performance of QBN on various IBM QX hardware against Qiskit simulator and classical analysis. We consider a 4-node BN for stock prediction for our experimental evaluation. We construct a quantum circuit to represent the 4-node BN using Qiskit, and run the circuit on nine IBM quantum devices: Yorktown, Vigo, Ourense, Essex, Burlington, London, Rome, Athens and Melbourne. We will also compare the performance of each device across the four levels of optimization performed by the IBM Transpiler when mapping a given quantum circuit to a given device. We use the root mean square percentage error as the metric for performance comparison of various hardware.
A Scale Invariant Flatness Measure for Deep Network Minima
Feb 06, 2019



It has been empirically observed that the flatness of minima obtained from training deep networks seems to correlate with better generalization. However, for deep networks with positively homogeneous activations, most measures of sharpness/flatness are not invariant to rescaling of the network parameters, corresponding to the same function. This means that the measure of flatness/sharpness can be made as small or as large as possible through rescaling, rendering the quantitative measures meaningless. In this paper we show that for deep networks with positively homogenous activations, these rescalings constitute equivalence relations, and that these equivalence relations induce a quotient manifold structure in the parameter space. Using this manifold structure and an appropriate metric, we propose a Hessian-based measure for flatness that is invariant to rescaling. We use this new measure to confirm the proposition that Large-Batch SGD minima are indeed sharper than Small-Batch SGD minima.