 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable and Efficient Large-Scale Log Analysis with LLMs: An IT Software Support Case Study
Nov 17, 2025IT environments typically have logging mechanisms to monitor system health and detect issues. However, the huge volume of generated logs makes manual inspection impractical, highlighting the importance of automated log analysis in IT Software Support. In this paper, we propose a log analytics tool that leverages Large Language Models (LLMs) for log data processing and issue diagnosis, enabling the generation of automated insights and summaries. We further present a novel approach for efficiently running LLMs on CPUs to process massive log volumes in minimal time without compromising output quality. We share the insights and lessons learned from deployment of the tool - in production since March 2024 - scaled across 70 software products, processing over 2000 tickets for issue diagnosis, achieving a time savings of 300+ man hours and an estimated $15,444 per month in manpower costs compared to the traditional log analysis practices.
ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
Feb 07, 2025



Realizing the vision of using AI agents to automate critical IT tasks depends on the ability to measure and understand effectiveness of proposed solutions. We introduce ITBench, a framework that offers a systematic methodology for benchmarking AI agents to address real-world IT automation tasks. Our initial release targets three key areas: Site Reliability Engineering (SRE), Compliance and Security Operations (CISO), and Financial Operations (FinOps). The design enables AI researchers to understand the challenges and opportunities of AI agents for IT automation with push-button workflows and interpretable metrics. ITBench includes an initial set of 94 real-world scenarios, which can be easily extended by community contributions. Our results show that agents powered by state-of-the-art models resolve only 13.8% of SRE scenarios, 25.2% of CISO scenarios, and 0% of FinOps scenarios. We expect ITBench to be a key enabler of AI-driven IT automation that is correct, safe, and fast.
CodeSift: An LLM-Based Reference-Less Framework for Automatic Code Validation
Aug 28, 2024



The advent of large language models (LLMs) has greatly facilitated code generation, but ensuring the functional correctness of generated code remains a challenge. Traditional validation methods are often time-consuming, error-prone, and impractical for large volumes of code. We introduce CodeSift, a novel framework that leverages LLMs as the first-line filter of code validation without the need for execution, reference code, or human feedback, thereby reducing the validation effort. We assess the effectiveness of our method across three diverse datasets encompassing two programming languages. Our results indicate that CodeSift outperforms state-of-the-art code evaluation methods. Internal testing conducted with subject matter experts reveals that the output generated by CodeSift is in line with human preference, reinforcing its effectiveness as a dependable automated code validation tool.
AutoMixer for Improved Multivariate Time-Series Forecasting on Business and IT Observability Data
Nov 02, 2023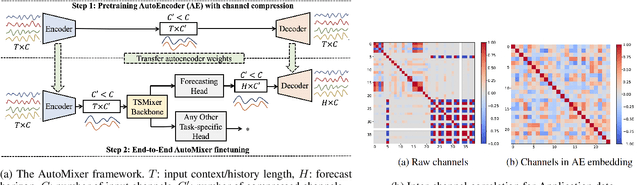
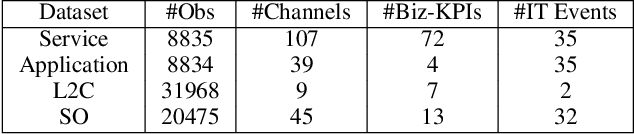
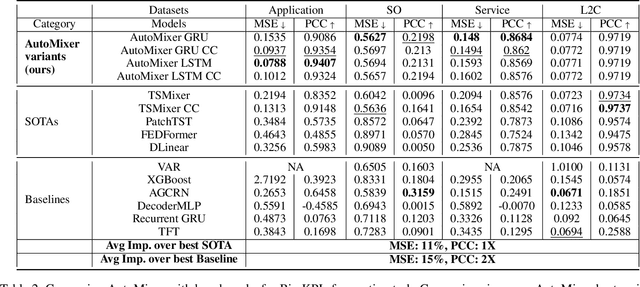
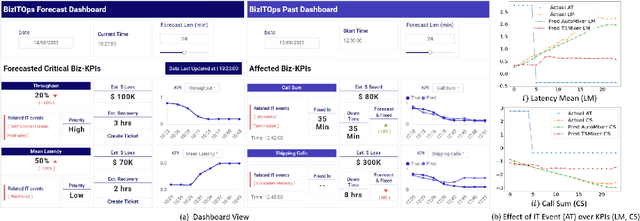
The efficiency of business processes relies on business key performance indicators (Biz-KPIs), that can be negatively impacted by IT failures. Business and IT Observability (BizITObs) data fuses both Biz-KPIs and IT event channels together as multivariate time series data. Forecasting Biz-KPIs in advance can enhance efficiency and revenue through proactive corrective measures. However, BizITObs data generally exhibit both useful and noisy inter-channel interactions between Biz-KPIs and IT events that need to be effectively decoupled. This leads to suboptimal forecasting performance when existing multivariate forecasting models are employed. To address this, we introduce AutoMixer, a time-series Foundation Model (FM) approach, grounded on the novel technique of channel-compressed pretrain and finetune workflows. AutoMixer leverages an AutoEncoder for channel-compressed pretraining and integrates it with the advanced TSMixer model for multivariate time series forecasting. This fusion greatly enhances the potency of TSMixer for accurate forecasts and also generalizes well across several downstream tasks. Through detailed experiments and dashboard analytics, we show AutoMixer's capability to consistently improve the Biz-KPI's forecasting accuracy (by 11-15\%) which directly translates to actionable business insights.
Learning Representations on Logs for AIOps
Aug 18, 2023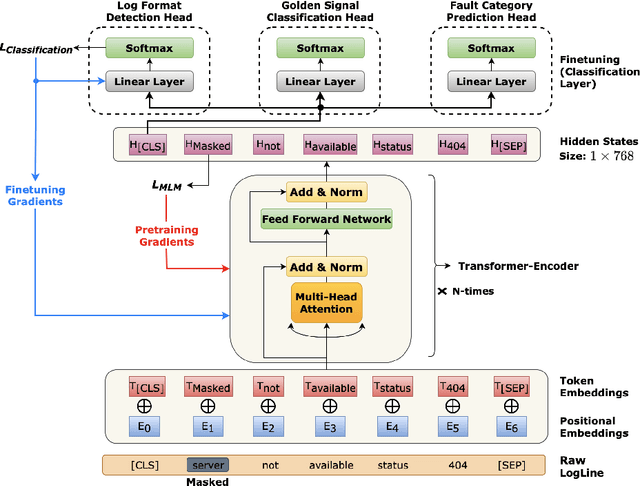



AI for IT Operations (AIOps) is a powerful platform that Site Reliability Engineers (SREs) use to automate and streamline operational workflows with minimal human intervention. Automated log analysis is a critical task in AIOps as it provides key insights for SREs to identify and address ongoing faults. Tasks such as log format detection, log classification, and log parsing are key components of automated log analysis. Most of these tasks require supervised learning; however, there are multiple challenges due to limited labelled log data and the diverse nature of log data. Large Language Models (LLMs) such as BERT and GPT3 are trained using self-supervision on a vast amount of unlabeled data. These models provide generalized representations that can be effectively used for various downstream tasks with limited labelled data. Motivated by the success of LLMs in specific domains like science and biology, this paper introduces a LLM for log data which is trained on public and proprietary log data. The results of our experiments demonstrate that the proposed LLM outperforms existing models on multiple downstream tasks. In summary, AIOps powered by LLMs offers an efficient and effective solution for automating log analysis tasks and enabling SREs to focus on higher-level tasks. Our proposed LLM, trained on public and proprietary log data, offers superior performance on multiple downstream tasks, making it a valuable addition to the AIOps platform.
Picking Pearl From Seabed: Extracting Artefacts from Noisy Issue Triaging Collaborative Conversations for Hybrid Cloud Services
May 31, 2021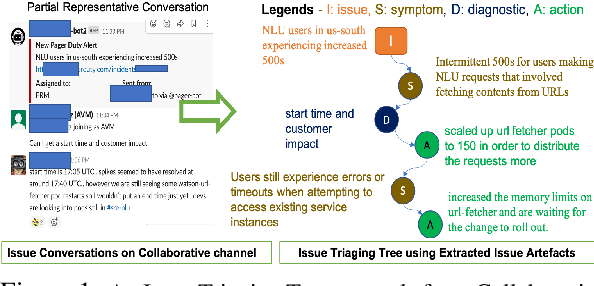
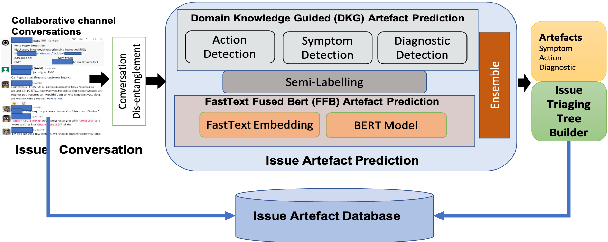
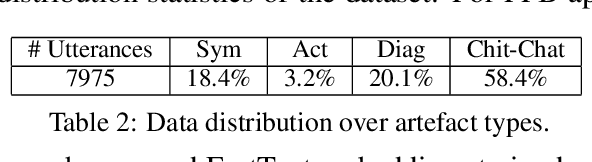

Site Reliability Engineers (SREs) play a key role in issue identification and resolution. After an issue is reported, SREs come together in a virtual room (collaboration platform) to triage the issue. While doing so, they leave behind a wealth of information which can be used later for triaging similar issues. However, usability of the conversations offer challenges due to them being i) noisy and ii) unlabelled. This paper presents a novel approach for issue artefact extraction from the noisy conversations with minimal labelled data. We propose a combination of unsupervised and supervised model with minimum human intervention that leverages domain knowledge to predict artefacts for a small amount of conversation data and use that for fine-tuning an already pretrained language model for artefact prediction on a large amount of conversation data. Experimental results on our dataset show that the proposed ensemble of unsupervised and supervised model is better than using either one of them individually.
Carbon to Diamond: An Incident Remediation Assistant System From Site Reliability Engineers' Conversations in Hybrid Cloud Operations
Oct 12, 2020



Conversational channels are changing the landscape of hybrid cloud service management. These channels are becoming important avenues for Site Reliability Engineers (SREs) %Subject Matter Experts (SME) to collaboratively work together to resolve an incident or issue. Identifying segmented conversations and extracting key insights or artefacts from them can help engineers to improve the efficiency of the incident remediation process by using information retrieval mechanisms for similar incidents. However, it has been empirically observed that due to the semi-formal behavior of such conversations (human language) they are very unique in nature and also contain lot of domain-specific terms. This makes it difficult to use the standard natural language processing frameworks directly, which are popularly used in standard NLP tasks. %It is important to identify the correct keywords and artefacts like symptoms, issue etc., present in the conversation chats. In this paper, we build a framework that taps into the conversational channels and uses various learning methods to (a) understand and extract key artefacts from conversations like diagnostic steps and resolution actions taken, and (b) present an approach to identify past conversations about similar issues. Experimental results on our dataset show the efficacy of our proposed method.
Using Semantic Role Knowledge for Relevance Ranking of Key Phrases inDocuments: An Unsupervised Approach
Aug 09, 2019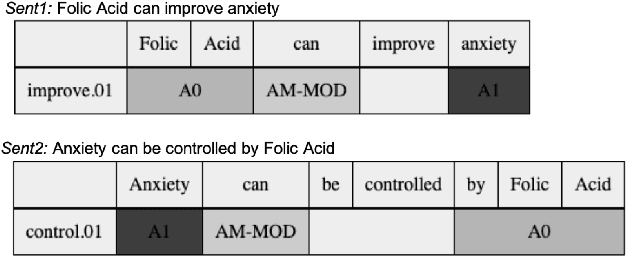

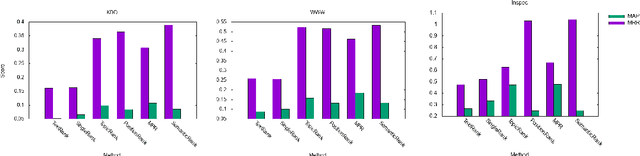
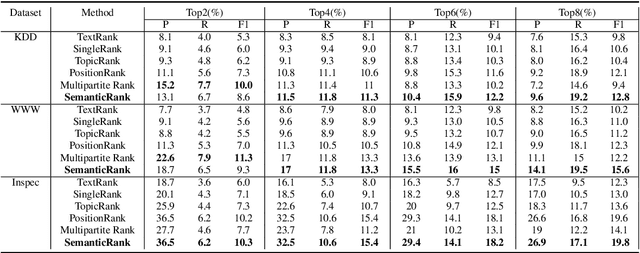
In this paper, we investigate the integration of sentence position and semantic role of words in a PageRank system to build a key phrase ranking method. We present the evaluation results of our approach on three scientific articles. We show that semantic role information, when integrated with a PageRank system, can become a new lexical feature. Our approach had an overall improvement on all the data sets over the state-of-art baseline approaches.