 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
Feb 07, 2025



Realizing the vision of using AI agents to automate critical IT tasks depends on the ability to measure and understand effectiveness of proposed solutions. We introduce ITBench, a framework that offers a systematic methodology for benchmarking AI agents to address real-world IT automation tasks. Our initial release targets three key areas: Site Reliability Engineering (SRE), Compliance and Security Operations (CISO), and Financial Operations (FinOps). The design enables AI researchers to understand the challenges and opportunities of AI agents for IT automation with push-button workflows and interpretable metrics. ITBench includes an initial set of 94 real-world scenarios, which can be easily extended by community contributions. Our results show that agents powered by state-of-the-art models resolve only 13.8% of SRE scenarios, 25.2% of CISO scenarios, and 0% of FinOps scenarios. We expect ITBench to be a key enabler of AI-driven IT automation that is correct, safe, and fast.
CodeSift: An LLM-Based Reference-Less Framework for Automatic Code Validation
Aug 28, 2024



The advent of large language models (LLMs) has greatly facilitated code generation, but ensuring the functional correctness of generated code remains a challenge. Traditional validation methods are often time-consuming, error-prone, and impractical for large volumes of code. We introduce CodeSift, a novel framework that leverages LLMs as the first-line filter of code validation without the need for execution, reference code, or human feedback, thereby reducing the validation effort. We assess the effectiveness of our method across three diverse datasets encompassing two programming languages. Our results indicate that CodeSift outperforms state-of-the-art code evaluation methods. Internal testing conducted with subject matter experts reveals that the output generated by CodeSift is in line with human preference, reinforcing its effectiveness as a dependable automated code validation tool.
Learning Representations on Logs for AIOps
Aug 18, 2023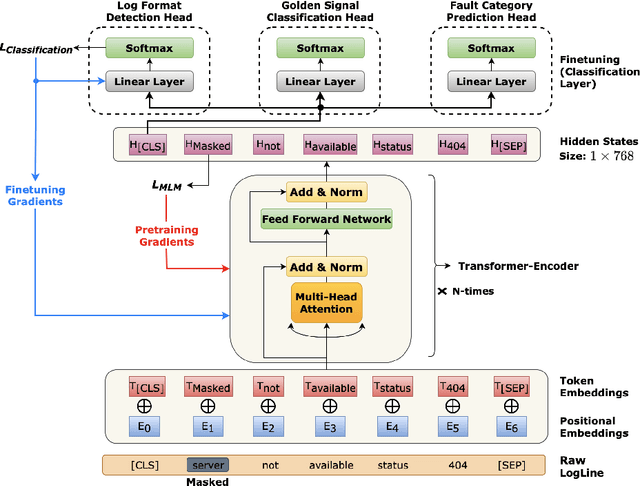



AI for IT Operations (AIOps) is a powerful platform that Site Reliability Engineers (SREs) use to automate and streamline operational workflows with minimal human intervention. Automated log analysis is a critical task in AIOps as it provides key insights for SREs to identify and address ongoing faults. Tasks such as log format detection, log classification, and log parsing are key components of automated log analysis. Most of these tasks require supervised learning; however, there are multiple challenges due to limited labelled log data and the diverse nature of log data. Large Language Models (LLMs) such as BERT and GPT3 are trained using self-supervision on a vast amount of unlabeled data. These models provide generalized representations that can be effectively used for various downstream tasks with limited labelled data. Motivated by the success of LLMs in specific domains like science and biology, this paper introduces a LLM for log data which is trained on public and proprietary log data. The results of our experiments demonstrate that the proposed LLM outperforms existing models on multiple downstream tasks. In summary, AIOps powered by LLMs offers an efficient and effective solution for automating log analysis tasks and enabling SREs to focus on higher-level tasks. Our proposed LLM, trained on public and proprietary log data, offers superior performance on multiple downstream tasks, making it a valuable addition to the AIOps platform.
MuRIL: Multilingual Representations for Indian Languages
Apr 02, 2021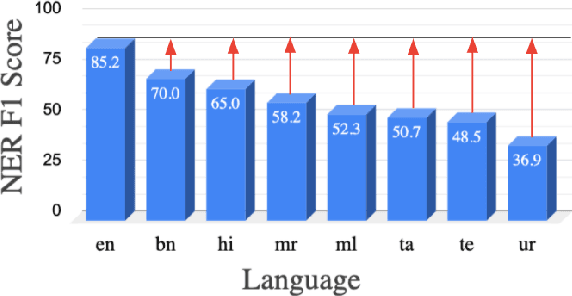


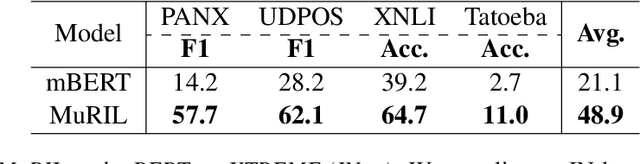
India is a multilingual society with 1369 rationalized languages and dialects being spoken across the country (INDIA, 2011). Of these, the 22 scheduled languages have a staggering total of 1.17 billion speakers and 121 languages have more than 10,000 speakers (INDIA, 2011). India also has the second largest (and an ever growing) digital footprint (Statista, 2020). Despite this, today's state-of-the-art multilingual systems perform suboptimally on Indian (IN) languages. This can be explained by the fact that multilingual language models (LMs) are often trained on 100+ languages together, leading to a small representation of IN languages in their vocabulary and training data. Multilingual LMs are substantially less effective in resource-lean scenarios (Wu and Dredze, 2020; Lauscher et al., 2020), as limited data doesn't help capture the various nuances of a language. One also commonly observes IN language text transliterated to Latin or code-mixed with English, especially in informal settings (for example, on social media platforms) (Rijhwani et al., 2017). This phenomenon is not adequately handled by current state-of-the-art multilingual LMs. To address the aforementioned gaps, we propose MuRIL, a multilingual LM specifically built for IN languages. MuRIL is trained on significantly large amounts of IN text corpora only. We explicitly augment monolingual text corpora with both translated and transliterated document pairs, that serve as supervised cross-lingual signals in training. MuRIL significantly outperforms multilingual BERT (mBERT) on all tasks in the challenging cross-lingual XTREME benchmark (Hu et al., 2020). We also present results on transliterated (native to Latin script) test sets of the chosen datasets and demonstrate the efficacy of MuRIL in handling transliterated data.