 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
Feb 07, 2025



Realizing the vision of using AI agents to automate critical IT tasks depends on the ability to measure and understand effectiveness of proposed solutions. We introduce ITBench, a framework that offers a systematic methodology for benchmarking AI agents to address real-world IT automation tasks. Our initial release targets three key areas: Site Reliability Engineering (SRE), Compliance and Security Operations (CISO), and Financial Operations (FinOps). The design enables AI researchers to understand the challenges and opportunities of AI agents for IT automation with push-button workflows and interpretable metrics. ITBench includes an initial set of 94 real-world scenarios, which can be easily extended by community contributions. Our results show that agents powered by state-of-the-art models resolve only 13.8% of SRE scenarios, 25.2% of CISO scenarios, and 0% of FinOps scenarios. We expect ITBench to be a key enabler of AI-driven IT automation that is correct, safe, and fast.
AIOpsLab: A Holistic Framework to Evaluate AI Agents for Enabling Autonomous Clouds
Jan 12, 2025



AI for IT Operations (AIOps) aims to automate complex operational tasks, such as fault localization and root cause analysis, to reduce human workload and minimize customer impact. While traditional DevOps tools and AIOps algorithms often focus on addressing isolated operational tasks, recent advances in Large Language Models (LLMs) and AI agents are revolutionizing AIOps by enabling end-to-end and multitask automation. This paper envisions a future where AI agents autonomously manage operational tasks throughout the entire incident lifecycle, leading to self-healing cloud systems, a paradigm we term AgentOps. Realizing this vision requires a comprehensive framework to guide the design, development, and evaluation of these agents. To this end, we present AIOPSLAB, a framework that not only deploys microservice cloud environments, injects faults, generates workloads, and exports telemetry data but also orchestrates these components and provides interfaces for interacting with and evaluating agents. We discuss the key requirements for such a holistic framework and demonstrate how AIOPSLAB can facilitate the evaluation of next-generation AIOps agents. Through evaluations of state-of-the-art LLM agents within the benchmark created by AIOPSLAB, we provide insights into their capabilities and limitations in handling complex operational tasks in cloud environments.
Building AI Agents for Autonomous Clouds: Challenges and Design Principles
Jul 16, 2024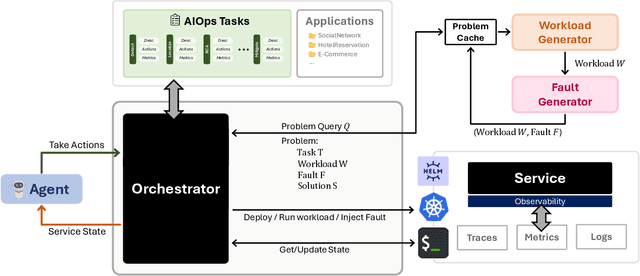


The rapid growth in the use of Large Language Models (LLMs) and AI Agents as part of software development and deployment is revolutionizing the information technology landscape. While code generation receives significant attention, a higher-impact application lies in using AI agents for operational resilience of cloud services, which currently require significant human effort and domain knowledge. There is a growing interest in AI for IT Operations (AIOps) which aims to automate complex operational tasks, like fault localization and root cause analysis, thereby reducing human intervention and customer impact. However, achieving the vision of autonomous and self-healing clouds though AIOps is hampered by the lack of standardized frameworks for building, evaluating, and improving AIOps agents. This vision paper lays the groundwork for such a framework by first framing the requirements and then discussing design decisions that satisfy them. We also propose AIOpsLab, a prototype implementation leveraging agent-cloud-interface that orchestrates an application, injects real-time faults using chaos engineering, and interfaces with an agent to localize and resolve the faults. We report promising results and lay the groundwork to build a modular and robust framework for building, evaluating, and improving agents for autonomous clouds.
Configuration Validation with Large Language Models
Oct 15, 2023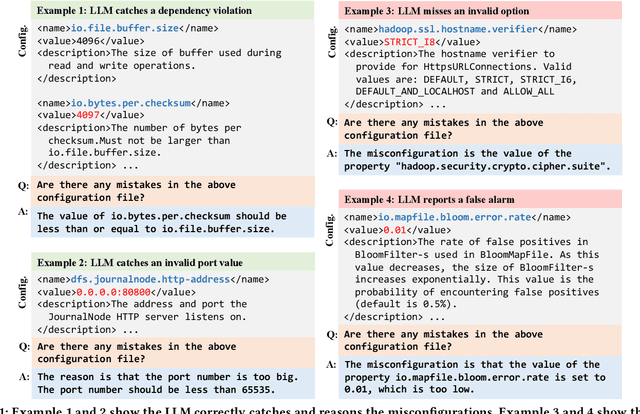

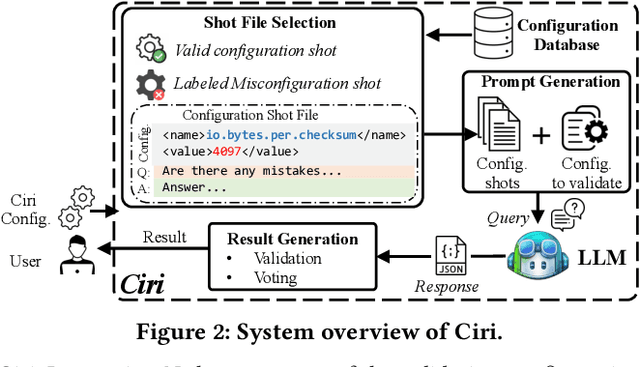
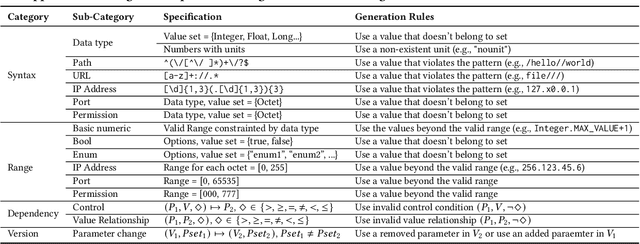
Misconfigurations are the major causes of software failures. Existing configuration validation techniques rely on manually written rules or test cases, which are expensive to implement and maintain, and are hard to be comprehensive. Leveraging machine learning (ML) and natural language processing (NLP) for configuration validation is considered a promising direction, but has been facing challenges such as the need of not only large-scale configuration data, but also system-specific features and models which are hard to generalize. Recent advances in Large Language Models (LLMs) show the promises to address some of the long-lasting limitations of ML/NLP-based configuration validation techniques. In this paper, we present an exploratory analysis on the feasibility and effectiveness of using LLMs like GPT and Codex for configuration validation. Specifically, we take a first step to empirically evaluate LLMs as configuration validators without additional fine-tuning or code generation. We develop a generic LLM-based validation framework, named Ciri, which integrates different LLMs. Ciri devises effective prompt engineering with few-shot learning based on both valid configuration and misconfiguration data. Ciri also validates and aggregates the outputs of LLMs to generate validation results, coping with known hallucination and nondeterminism of LLMs. We evaluate the validation effectiveness of Ciri on five popular LLMs using configuration data of six mature, widely deployed open-source systems. Our analysis (1) confirms the potential of using LLMs for configuration validation, (2) understands the design space of LLMbased validators like Ciri, especially in terms of prompt engineering with few-shot learning, and (3) reveals open challenges such as ineffectiveness in detecting certain types of misconfigurations and biases to popular configuration parameters.