 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Finding Needles in Images: Can Multimodal LLMs Locate Fine Details?
Aug 07, 2025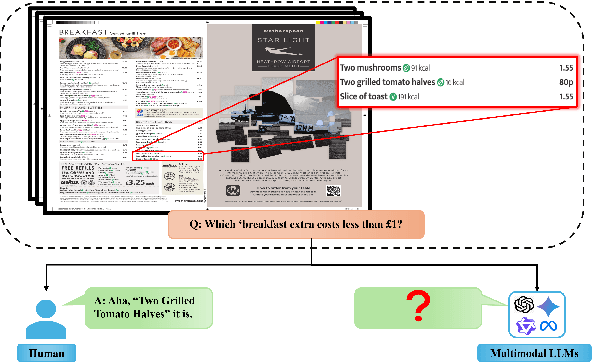
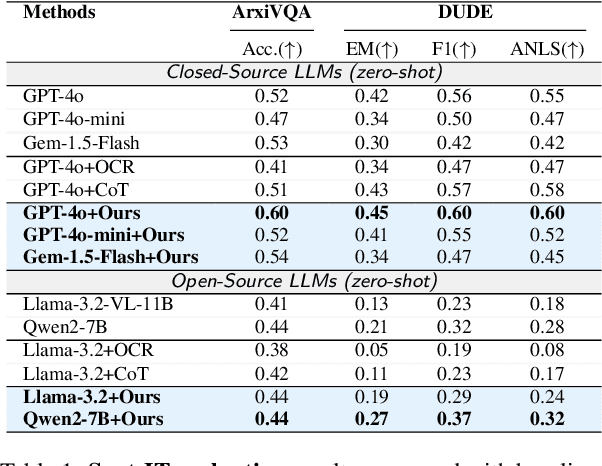
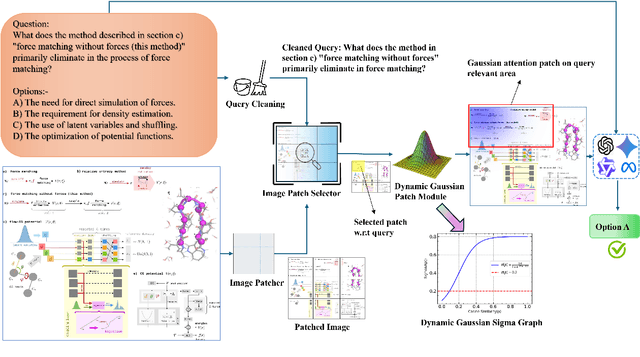
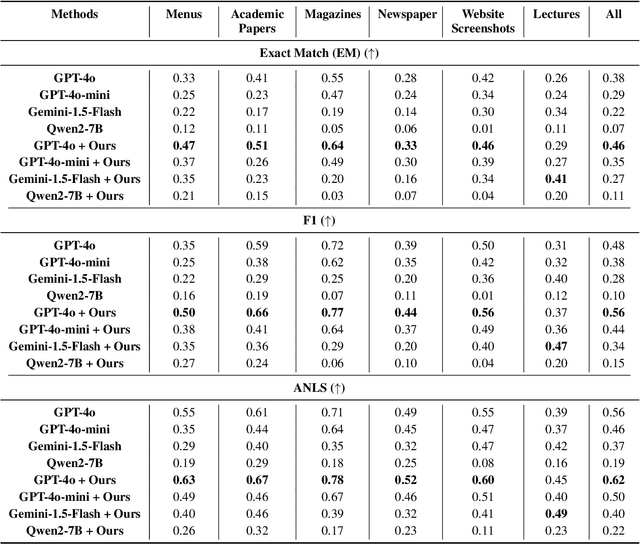
While Multi-modal Large Language Models (MLLMs) have shown impressive capabilities in document understanding tasks, their ability to locate and reason about fine-grained details within complex documents remains understudied. Consider searching a restaurant menu for a specific nutritional detail or identifying a disclaimer in a lengthy newspaper article tasks that demand careful attention to small but significant details within a broader narrative, akin to Finding Needles in Images (NiM). To address this gap, we introduce NiM, a carefully curated benchmark spanning diverse real-world documents including newspapers, menus, and lecture images, specifically designed to evaluate MLLMs' capability in these intricate tasks. Building on this, we further propose Spot-IT, a simple yet effective approach that enhances MLLMs capability through intelligent patch selection and Gaussian attention, motivated from how humans zoom and focus when searching documents. Our extensive experiments reveal both the capabilities and limitations of current MLLMs in handling fine-grained document understanding tasks, while demonstrating the effectiveness of our approach. Spot-IT achieves significant improvements over baseline methods, particularly in scenarios requiring precise detail extraction from complex layouts.
* Accepted at ACL 2025 in the main track
AI-Assisted Fixes to Code Review Comments at Scale
Jul 17, 2025Aim. There are 10s of thousands of code review comments each week at Meta. We developed Metamate for Code Review (MetaMateCR) that provides AI-assisted fixes for reviewer comments in production at scale. Method. We developed an internal benchmark of 64k <review comment, patch> data points to fine-tune Llama models. Once our models achieve reasonable offline results, we roll them into production. To ensure that our AI-assisted fixes do not negatively impact the time it takes to do code reviews, we conduct randomized controlled safety trials as well as full production experiments. Offline Results. As a baseline, we compare GPT-4o to our small and large Llama models. In offline results, our LargeLSFT model creates an exact match patch 68% of the time outperforming GPT-4o by 9 percentage points (pp). The internal models also use more modern Hack functions when compared to the PHP functions suggested by GPT-4o. Safety Trial. When we roll MetaMateCR into production in a safety trial that compares no AI patches with AI patch suggestions, we see a large regression with reviewers taking over 5% longer to conduct reviews. After investigation, we modify the UX to only show authors the AI patches, and see no regressions in the time for reviews. Production. When we roll LargeLSFT into production, we see an ActionableToApplied rate of 19.7%, which is a 9.2pp improvement over GPT-4o. Our results illustrate the importance of safety trials in ensuring that AI does not inadvertently slow down engineers, and a successful review comment to AI patch product running at scale.
Multi-line AI-assisted Code Authoring
Feb 06, 2024
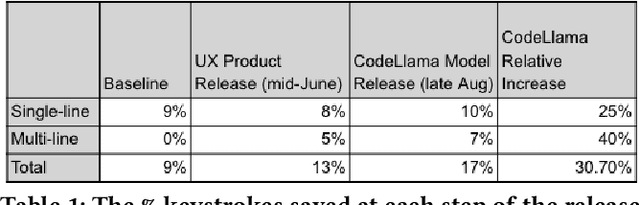

CodeCompose is an AI-assisted code authoring tool powered by large language models (LLMs) that provides inline suggestions to 10's of thousands of developers at Meta. In this paper, we present how we scaled the product from displaying single-line suggestions to multi-line suggestions. This evolution required us to overcome several unique challenges in improving the usability of these suggestions for developers. First, we discuss how multi-line suggestions can have a 'jarring' effect, as the LLM's suggestions constantly move around the developer's existing code, which would otherwise result in decreased productivity and satisfaction. Second, multi-line suggestions take significantly longer to generate; hence we present several innovative investments we made to reduce the perceived latency for users. These model-hosting optimizations sped up multi-line suggestion latency by 2.5x. Finally, we conduct experiments on 10's of thousands of engineers to understand how multi-line suggestions impact the user experience and contrast this with single-line suggestions. Our experiments reveal that (i) multi-line suggestions account for 42% of total characters accepted (despite only accounting for 16% for displayed suggestions) (ii) multi-line suggestions almost doubled the percentage of keystrokes saved for users from 9% to 17%. Multi-line CodeCompose has been rolled out to all engineers at Meta, and less than 1% of engineers have opted out of multi-line suggestions.
Configuration Validation with Large Language Models
Oct 15, 2023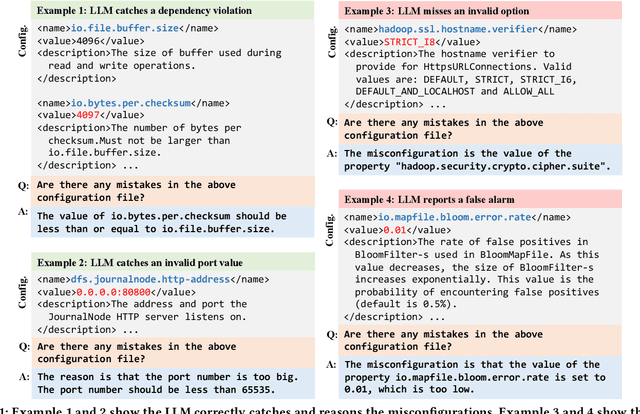

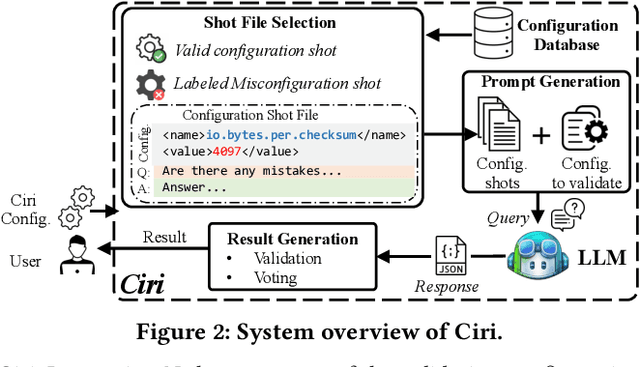
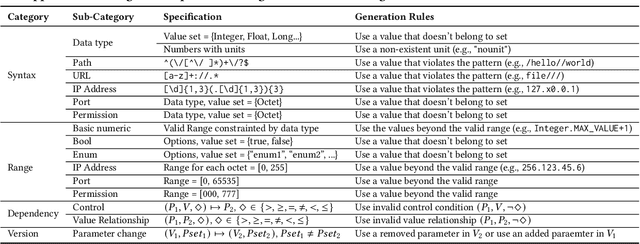
Misconfigurations are the major causes of software failures. Existing configuration validation techniques rely on manually written rules or test cases, which are expensive to implement and maintain, and are hard to be comprehensive. Leveraging machine learning (ML) and natural language processing (NLP) for configuration validation is considered a promising direction, but has been facing challenges such as the need of not only large-scale configuration data, but also system-specific features and models which are hard to generalize. Recent advances in Large Language Models (LLMs) show the promises to address some of the long-lasting limitations of ML/NLP-based configuration validation techniques. In this paper, we present an exploratory analysis on the feasibility and effectiveness of using LLMs like GPT and Codex for configuration validation. Specifically, we take a first step to empirically evaluate LLMs as configuration validators without additional fine-tuning or code generation. We develop a generic LLM-based validation framework, named Ciri, which integrates different LLMs. Ciri devises effective prompt engineering with few-shot learning based on both valid configuration and misconfiguration data. Ciri also validates and aggregates the outputs of LLMs to generate validation results, coping with known hallucination and nondeterminism of LLMs. We evaluate the validation effectiveness of Ciri on five popular LLMs using configuration data of six mature, widely deployed open-source systems. Our analysis (1) confirms the potential of using LLMs for configuration validation, (2) understands the design space of LLMbased validators like Ciri, especially in terms of prompt engineering with few-shot learning, and (3) reveals open challenges such as ineffectiveness in detecting certain types of misconfigurations and biases to popular configuration parameters.