 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Symbolic Verification on Instruction Following of LLMs
Jan 25, 2026A fundamental problem of applying Large Language Models (LLMs) to important applications is that LLMs do not always follow instructions, and violations are often hard to observe or check. In LLM-based agentic workflows, such violations can propagate and amplify along reasoning chains, causing task failures and system incidents. This paper presents NSVIF, a neuro-symbolic framework for verifying whether an LLM's output follows the instructions used to prompt the LLM. NSVIF is a universal, general-purpose verifier; it makes no assumption about the instruction or the LLM. NSVIF formulates instruction-following verification as a constraint-satisfaction problem by modeling user instructions as constraints. NSVIF models both logical and semantic constraints; constraint solving is done by a unified solver that orchestrates logical reasoning and semantic analysis. To evaluate NSVIF, we develop VIFBENCH, a new benchmark for instruction-following verifiers with fine-grained data labels. Experiments show that NSVIF significantly outperforms LLM-based approaches and provides interpretable feedback. We also show that feedback from NSVIF helps improve LLMs' instruction-following capability without post-training.
PerfTracker: Online Performance Troubleshooting for Large-scale Model Training in Production
Jun 12, 2025



Troubleshooting performance problems of large model training (LMT) is immensely challenging, due to unprecedented scales of modern GPU clusters, the complexity of software-hardware interactions, and the data intensity of the training process. Existing troubleshooting approaches designed for traditional distributed systems or datacenter networks fall short and can hardly apply to real-world training systems. In this paper, we present PerfTracker, the first online troubleshooting system utilizing fine-grained profiling, to diagnose performance issues of large-scale model training in production. PerfTracker can diagnose performance issues rooted in both hardware (e.g., GPUs and their interconnects) and software (e.g., Python functions and GPU operations). It scales to LMT on modern GPU clusters. PerfTracker effectively summarizes runtime behavior patterns of fine-grained LMT functions via online profiling, and leverages differential observability to localize the root cause with minimal production impact. PerfTracker has been deployed as a production service for large-scale GPU clusters of O(10, 000) GPUs (product homepage https://help.aliyun.com/zh/pai/user-guide/perftracker-online-performance-analysis-diagnostic-tool). It has been used to diagnose a variety of difficult performance issues.
ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
Feb 07, 2025



Realizing the vision of using AI agents to automate critical IT tasks depends on the ability to measure and understand effectiveness of proposed solutions. We introduce ITBench, a framework that offers a systematic methodology for benchmarking AI agents to address real-world IT automation tasks. Our initial release targets three key areas: Site Reliability Engineering (SRE), Compliance and Security Operations (CISO), and Financial Operations (FinOps). The design enables AI researchers to understand the challenges and opportunities of AI agents for IT automation with push-button workflows and interpretable metrics. ITBench includes an initial set of 94 real-world scenarios, which can be easily extended by community contributions. Our results show that agents powered by state-of-the-art models resolve only 13.8% of SRE scenarios, 25.2% of CISO scenarios, and 0% of FinOps scenarios. We expect ITBench to be a key enabler of AI-driven IT automation that is correct, safe, and fast.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024



This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
Configuration Validation with Large Language Models
Oct 15, 2023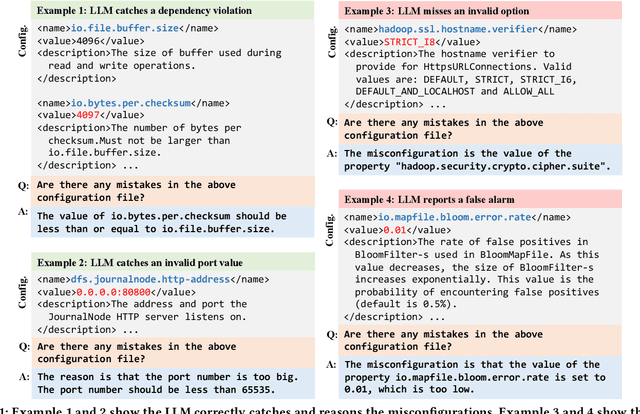

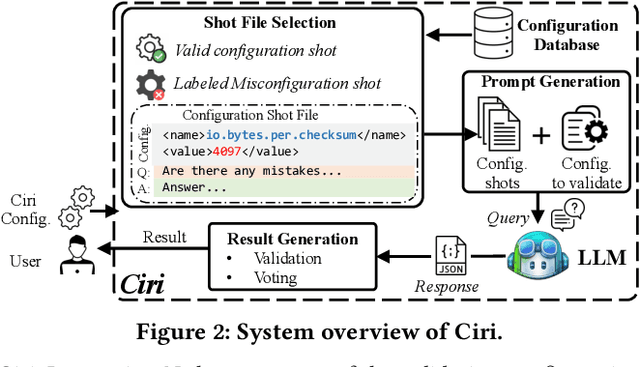
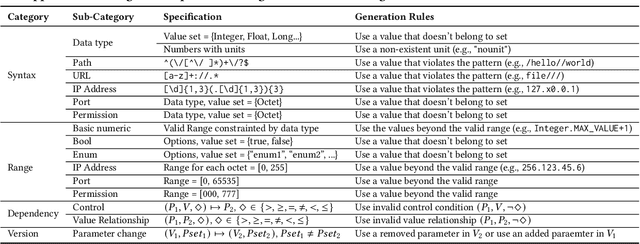
Misconfigurations are the major causes of software failures. Existing configuration validation techniques rely on manually written rules or test cases, which are expensive to implement and maintain, and are hard to be comprehensive. Leveraging machine learning (ML) and natural language processing (NLP) for configuration validation is considered a promising direction, but has been facing challenges such as the need of not only large-scale configuration data, but also system-specific features and models which are hard to generalize. Recent advances in Large Language Models (LLMs) show the promises to address some of the long-lasting limitations of ML/NLP-based configuration validation techniques. In this paper, we present an exploratory analysis on the feasibility and effectiveness of using LLMs like GPT and Codex for configuration validation. Specifically, we take a first step to empirically evaluate LLMs as configuration validators without additional fine-tuning or code generation. We develop a generic LLM-based validation framework, named Ciri, which integrates different LLMs. Ciri devises effective prompt engineering with few-shot learning based on both valid configuration and misconfiguration data. Ciri also validates and aggregates the outputs of LLMs to generate validation results, coping with known hallucination and nondeterminism of LLMs. We evaluate the validation effectiveness of Ciri on five popular LLMs using configuration data of six mature, widely deployed open-source systems. Our analysis (1) confirms the potential of using LLMs for configuration validation, (2) understands the design space of LLMbased validators like Ciri, especially in terms of prompt engineering with few-shot learning, and (3) reveals open challenges such as ineffectiveness in detecting certain types of misconfigurations and biases to popular configuration parameters.
Live Forensics for Distributed Storage Systems
Jul 24, 2019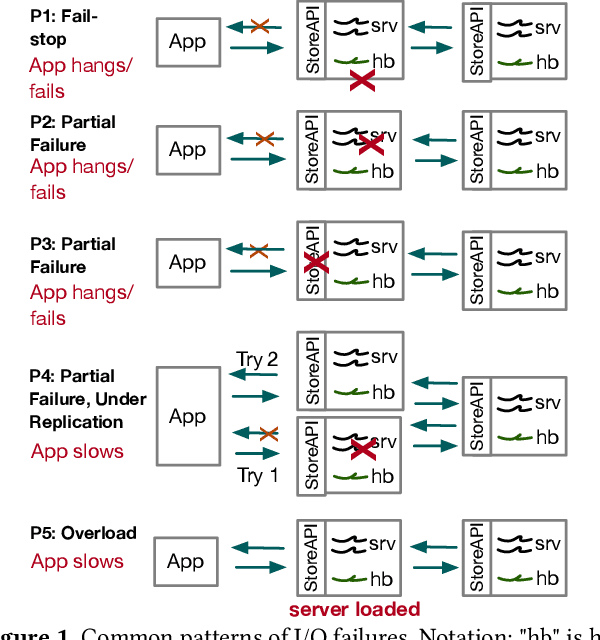



We present Kaleidoscope an innovative system that supports live forensics for application performance problems caused by either individual component failures or resource contention issues in large-scale distributed storage systems. The design of Kaleidoscope is driven by our study of I/O failures observed in a peta-scale storage system anonymized as PetaStore. Kaleidoscope is built on three key features: 1) using temporal and spatial differential observability for end-to-end performance monitoring of I/O requests, 2) modeling the health of storage components as a stochastic process using domain-guided functions that accounts for path redundancy and uncertainty in measurements, and, 3) observing differences in reliability and performance metrics between similar types of healthy and unhealthy components to attribute the most likely root causes. We deployed Kaleidoscope on PetaStore and our evaluation shows that Kaleidoscope can run live forensics at 5-minute intervals and pinpoint the root causes of 95.8% of real-world performance issues, with negligible monitoring overhead.