 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Spike Agreement Dependent Plasticity for Fast Local Learning in Spiking Neural Networks
Jan 13, 2026Spike-Timing-Dependent Plasticity (STDP) provides a biologically grounded learning rule for spiking neural networks (SNNs), but its reliance on precise spike timing and pairwise updates limits fast learning of weights. We introduce a supervised extension of Spike Agreement-Dependent Plasticity (SADP), which replaces pairwise spike-timing comparisons with population-level agreement metrics such as Cohen's kappa. The proposed learning rule preserves strict synaptic locality, admits linear-time complexity, and enables efficient supervised learning without backpropagation, surrogate gradients, or teacher forcing. We integrate supervised SADP within hybrid CNN-SNN architectures, where convolutional encoders provide compact feature representations that are converted into Poisson spike trains for agreement-driven learning in the SNN. Extensive experiments on MNIST, Fashion-MNIST, CIFAR-10, and biomedical image classification tasks demonstrate competitive performance and fast convergence. Additional analyses show stable performance across broad hyperparameter ranges and compatibility with device-inspired synaptic update dynamics. Together, these results establish supervised SADP as a scalable, biologically grounded, and hardware-aligned learning paradigm for spiking neural networks.
Scalable and Efficient Large-Scale Log Analysis with LLMs: An IT Software Support Case Study
Nov 17, 2025IT environments typically have logging mechanisms to monitor system health and detect issues. However, the huge volume of generated logs makes manual inspection impractical, highlighting the importance of automated log analysis in IT Software Support. In this paper, we propose a log analytics tool that leverages Large Language Models (LLMs) for log data processing and issue diagnosis, enabling the generation of automated insights and summaries. We further present a novel approach for efficiently running LLMs on CPUs to process massive log volumes in minimal time without compromising output quality. We share the insights and lessons learned from deployment of the tool - in production since March 2024 - scaled across 70 software products, processing over 2000 tickets for issue diagnosis, achieving a time savings of 300+ man hours and an estimated $15,444 per month in manpower costs compared to the traditional log analysis practices.
From 2D to 3D Without Extra Baggage: Data-Efficient Cancer Detection in Digital Breast Tomosynthesis
Nov 13, 2025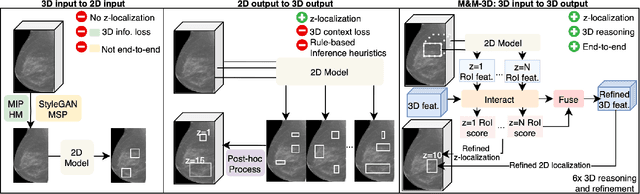
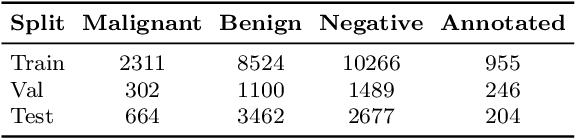
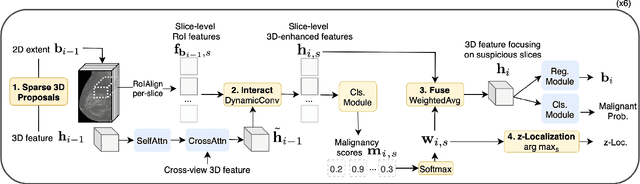
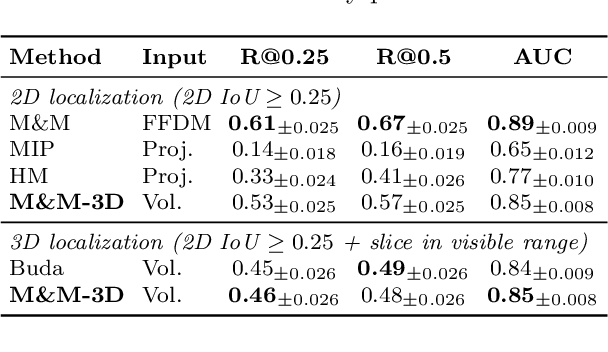
Digital Breast Tomosynthesis (DBT) enhances finding visibility for breast cancer detection by providing volumetric information that reduces the impact of overlapping tissues; however, limited annotated data has constrained the development of deep learning models for DBT. To address data scarcity, existing methods attempt to reuse 2D full-field digital mammography (FFDM) models by either flattening DBT volumes or processing slices individually, thus discarding volumetric information. Alternatively, 3D reasoning approaches introduce complex architectures that require more DBT training data. Tackling these drawbacks, we propose M&M-3D, an architecture that enables learnable 3D reasoning while remaining parameter-free relative to its FFDM counterpart, M&M. M&M-3D constructs malignancy-guided 3D features, and 3D reasoning is learned through repeatedly mixing these 3D features with slice-level information. This is achieved by modifying operations in M&M without adding parameters, thus enabling direct weight transfer from FFDM. Extensive experiments show that M&M-3D surpasses 2D projection and 3D slice-based methods by 11-54% for localization and 3-10% for classification. Additionally, M&M-3D outperforms complex 3D reasoning variants by 20-47% for localization and 2-10% for classification in the low-data regime, while matching their performance in high-data regime. On the popular BCS-DBT benchmark, M&M-3D outperforms previous top baseline by 4% for classification and 10% for localization.
Detecting Silent Failures in Multi-Agentic AI Trajectories
Nov 06, 2025Multi-Agentic AI systems, powered by large language models (LLMs), are inherently non-deterministic and prone to silent failures such as drift, cycles, and missing details in outputs, which are difficult to detect. We introduce the task of anomaly detection in agentic trajectories to identify these failures and present a dataset curation pipeline that captures user behavior, agent non-determinism, and LLM variation. Using this pipeline, we curate and label two benchmark datasets comprising \textbf{4,275 and 894} trajectories from Multi-Agentic AI systems. Benchmarking anomaly detection methods on these datasets, we show that supervised (XGBoost) and semi-supervised (SVDD) approaches perform comparably, achieving accuracies up to 98% and 96%, respectively. This work provides the first systematic study of anomaly detection in Multi-Agentic AI systems, offering datasets, benchmarks, and insights to guide future research.
ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
Feb 07, 2025



Realizing the vision of using AI agents to automate critical IT tasks depends on the ability to measure and understand effectiveness of proposed solutions. We introduce ITBench, a framework that offers a systematic methodology for benchmarking AI agents to address real-world IT automation tasks. Our initial release targets three key areas: Site Reliability Engineering (SRE), Compliance and Security Operations (CISO), and Financial Operations (FinOps). The design enables AI researchers to understand the challenges and opportunities of AI agents for IT automation with push-button workflows and interpretable metrics. ITBench includes an initial set of 94 real-world scenarios, which can be easily extended by community contributions. Our results show that agents powered by state-of-the-art models resolve only 13.8% of SRE scenarios, 25.2% of CISO scenarios, and 0% of FinOps scenarios. We expect ITBench to be a key enabler of AI-driven IT automation that is correct, safe, and fast.
A Dynamical Systems-Inspired Pruning Strategy for Addressing Oversmoothing in Graph Neural Networks
Dec 10, 2024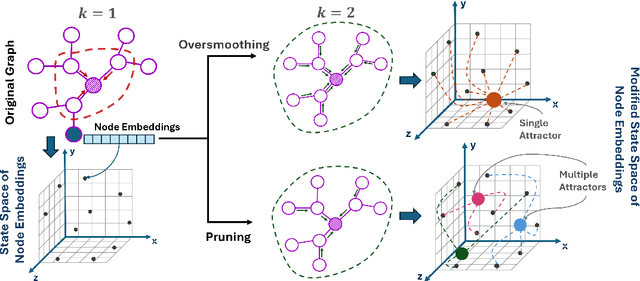
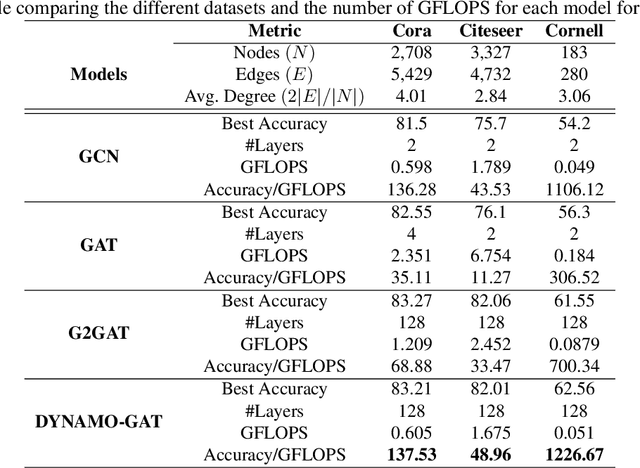
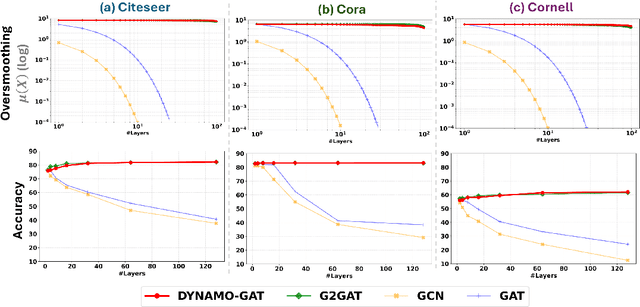
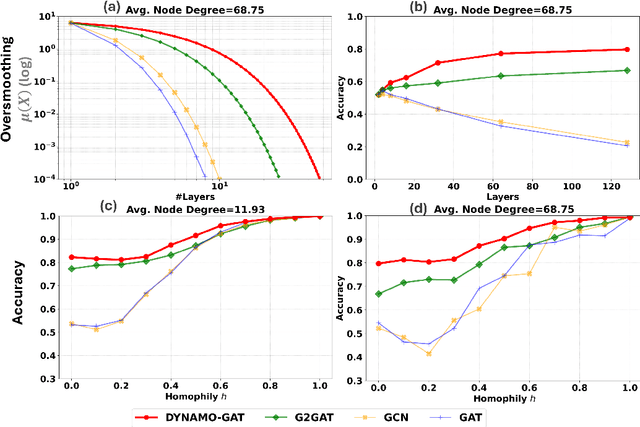
Oversmoothing in Graph Neural Networks (GNNs) poses a significant challenge as network depth increases, leading to homogenized node representations and a loss of expressiveness. In this work, we approach the oversmoothing problem from a dynamical systems perspective, providing a deeper understanding of the stability and convergence behavior of GNNs. Leveraging insights from dynamical systems theory, we identify the root causes of oversmoothing and propose \textbf{\textit{DYNAMO-GAT}}. This approach utilizes noise-driven covariance analysis and Anti-Hebbian principles to selectively prune redundant attention weights, dynamically adjusting the network's behavior to maintain node feature diversity and stability. Our theoretical analysis reveals how DYNAMO-GAT disrupts the convergence to oversmoothed states, while experimental results on benchmark datasets demonstrate its superior performance and efficiency compared to traditional and state-of-the-art methods. DYNAMO-GAT not only advances the theoretical understanding of oversmoothing through the lens of dynamical systems but also provides a practical and effective solution for improving the stability and expressiveness of deep GNNs.
Towards Robust Real-Time Hardware-based Mobile Malware Detection using Multiple Instance Learning Formulation
Apr 19, 2024This study introduces RT-HMD, a Hardware-based Malware Detector (HMD) for mobile devices, that refines malware representation in segmented time-series through a Multiple Instance Learning (MIL) approach. We address the mislabeling issue in real-time HMDs, where benign segments in malware time-series incorrectly inherit malware labels, leading to increased false positives. Utilizing the proposed Malicious Discriminative Score within the MIL framework, RT-HMD effectively identifies localized malware behaviors, thereby improving the predictive accuracy. Empirical analysis, using a hardware telemetry dataset collected from a mobile platform across 723 benign and 1033 malware samples, shows a 5% precision boost while maintaining recall, outperforming baselines affected by mislabeled benign segments.
Learning Locally Interacting Discrete Dynamical Systems: Towards Data-Efficient and Scalable Prediction
Apr 09, 2024



Locally interacting dynamical systems, such as epidemic spread, rumor propagation through crowd, and forest fire, exhibit complex global dynamics originated from local, relatively simple, and often stochastic interactions between dynamic elements. Their temporal evolution is often driven by transitions between a finite number of discrete states. Despite significant advancements in predictive modeling through deep learning, such interactions among many elements have rarely explored as a specific domain for predictive modeling. We present Attentive Recurrent Neural Cellular Automata (AR-NCA), to effectively discover unknown local state transition rules by associating the temporal information between neighboring cells in a permutation-invariant manner. AR-NCA exhibits the superior generalizability across various system configurations (i.e., spatial distribution of states), data efficiency and robustness in extremely data-limited scenarios even in the presence of stochastic interactions, and scalability through spatial dimension-independent prediction.
Sparse Spiking Neural Network: Exploiting Heterogeneity in Timescales for Pruning Recurrent SNN
Mar 06, 2024Recurrent Spiking Neural Networks (RSNNs) have emerged as a computationally efficient and brain-inspired learning model. The design of sparse RSNNs with fewer neurons and synapses helps reduce the computational complexity of RSNNs. Traditionally, sparse SNNs are obtained by first training a dense and complex SNN for a target task, and, then, pruning neurons with low activity (activity-based pruning) while maintaining task performance. In contrast, this paper presents a task-agnostic methodology for designing sparse RSNNs by pruning a large randomly initialized model. We introduce a novel Lyapunov Noise Pruning (LNP) algorithm that uses graph sparsification methods and utilizes Lyapunov exponents to design a stable sparse RSNN from a randomly initialized RSNN. We show that the LNP can leverage diversity in neuronal timescales to design a sparse Heterogeneous RSNN (HRSNN). Further, we show that the same sparse HRSNN model can be trained for different tasks, such as image classification and temporal prediction. We experimentally show that, in spite of being task-agnostic, LNP increases computational efficiency (fewer neurons and synapses) and prediction performance of RSNNs compared to traditional activity-based pruning of trained dense models.
* Published as a conference paper at ICLR 2024
Studying the Impact of Stochasticity on the Evaluation of Deep Neural Networks for Forest-Fire Prediction
Feb 23, 2024



This paper presents the first systematic study of the evaluation of Deep Neural Networks (DNNs) for discrete dynamical systems under stochastic assumptions, with a focus on wildfire prediction. We develop a framework to study the impact of stochasticity on two classes of evaluation metrics: classification-based metrics, which assess fidelity to observed ground truth (GT), and proper scoring rules, which test fidelity-to-statistic. Our findings reveal that evaluating for fidelity-to-statistic is a reliable alternative in highly stochastic scenarios. We extend our analysis to real-world wildfire data, highlighting limitations in traditional wildfire prediction evaluation methods, and suggest interpretable stochasticity-compatible alternatives.