 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKITLM: Domain-Specific Knowledge InTegration into Language Models for Question Answering
Aug 07, 2023



Large language models (LLMs) have demonstrated remarkable performance in a wide range of natural language tasks. However, as these models continue to grow in size, they face significant challenges in terms of computational costs. Additionally, LLMs often lack efficient domain-specific understanding, which is particularly crucial in specialized fields such as aviation and healthcare. To boost the domain-specific understanding, we propose, KITLM, a novel knowledge base integration approach into language model through relevant information infusion. By integrating pertinent knowledge, not only the performance of the language model is greatly enhanced, but the model size requirement is also significantly reduced while achieving comparable performance. Our proposed knowledge-infused model surpasses the performance of both GPT-3.5-turbo and the state-of-the-art knowledge infusion method, SKILL, achieving over 1.5 times improvement in exact match scores on the MetaQA. KITLM showed a similar performance boost in the aviation domain with AeroQA. The drastic performance improvement of KITLM over the existing methods can be attributed to the infusion of relevant knowledge while mitigating noise. In addition, we release two curated datasets to accelerate knowledge infusion research in specialized fields: a) AeroQA, a new benchmark dataset designed for multi-hop question-answering within the aviation domain, and b) Aviation Corpus, a dataset constructed from unstructured text extracted from the National Transportation Safety Board reports. Our research contributes to advancing the field of domain-specific language understanding and showcases the potential of knowledge infusion techniques in improving the performance of language models on question-answering.
Let the CAT out of the bag: Contrastive Attributed explanations for Text
Sep 16, 2021
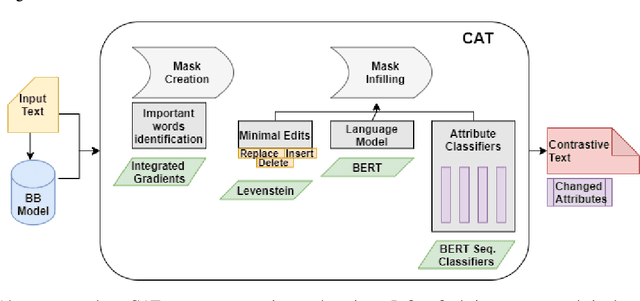
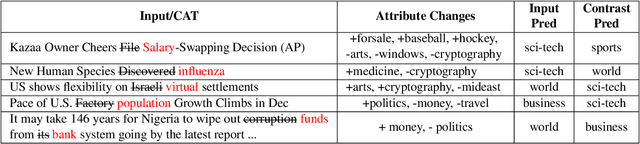
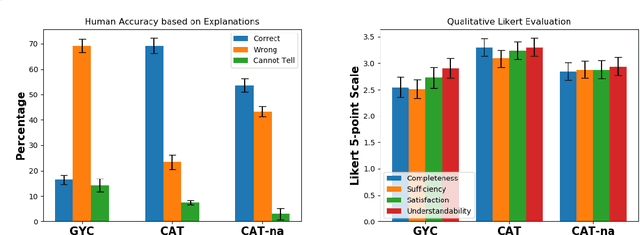
Contrastive explanations for understanding the behavior of black box models has gained a lot of attention recently as they provide potential for recourse. In this paper, we propose a method Contrastive Attributed explanations for Text (CAT) which provides contrastive explanations for natural language text data with a novel twist as we build and exploit attribute classifiers leading to more semantically meaningful explanations. To ensure that our contrastive generated text has the fewest possible edits with respect to the original text, while also being fluent and close to a human generated contrastive, we resort to a minimal perturbation approach regularized using a BERT language model and attribute classifiers trained on available attributes. We show through qualitative examples and a user study that our method not only conveys more insight because of these attributes, but also leads to better quality (contrastive) text. Moreover, quantitatively we show that our method is more efficient than other state-of-the-art methods with it also scoring higher on benchmark metrics such as flip rate, (normalized) Levenstein distance, fluency and content preservation.
Picking Pearl From Seabed: Extracting Artefacts from Noisy Issue Triaging Collaborative Conversations for Hybrid Cloud Services
May 31, 2021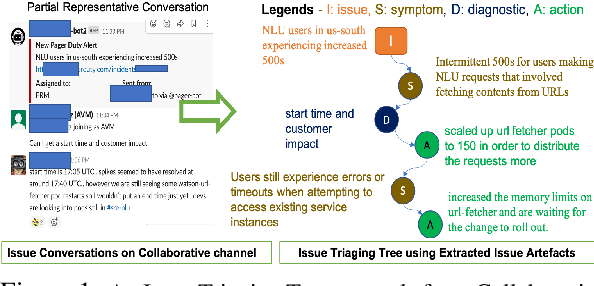
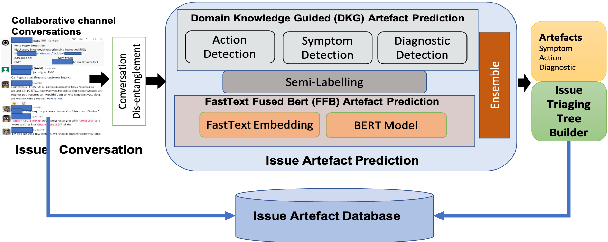
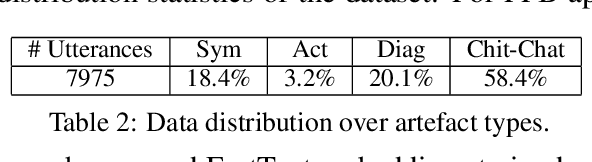

Site Reliability Engineers (SREs) play a key role in issue identification and resolution. After an issue is reported, SREs come together in a virtual room (collaboration platform) to triage the issue. While doing so, they leave behind a wealth of information which can be used later for triaging similar issues. However, usability of the conversations offer challenges due to them being i) noisy and ii) unlabelled. This paper presents a novel approach for issue artefact extraction from the noisy conversations with minimal labelled data. We propose a combination of unsupervised and supervised model with minimum human intervention that leverages domain knowledge to predict artefacts for a small amount of conversation data and use that for fine-tuning an already pretrained language model for artefact prediction on a large amount of conversation data. Experimental results on our dataset show that the proposed ensemble of unsupervised and supervised model is better than using either one of them individually.
No Rumours Please! A Multi-Indic-Lingual Approach for COVID Fake-Tweet Detection
Oct 14, 2020



The sudden widespread menace created by the present global pandemic COVID-19 has had an unprecedented effect on our lives. Man-kind is going through humongous fear and dependence on social media like never before. Fear inevitably leads to panic, speculations, and the spread of misinformation. Many governments have taken measures to curb the spread of such misinformation for public well being. Besides global measures, to have effective outreach, systems for demographically local languages have an important role to play in this effort. Towards this, we propose an approach to detect fake news about COVID-19 early on from social media, such as tweets, for multiple Indic-Languages besides English. In addition, we also create an annotated dataset of Hindi and Bengali tweet for fake news detection. We propose a BERT based model augmented with additional relevant features extracted from Twitter to identify fake tweets. To expand our approach to multiple Indic languages, we resort to mBERT based model which is fine-tuned over created dataset in Hindi and Bengali. We also propose a zero-shot learning approach to alleviate the data scarcity issue for such low resource languages. Through rigorous experiments, we show that our approach reaches around 89% F-Score in fake tweet detection which supercedes the state-of-the-art (SOTA) results. Moreover, we establish the first benchmark for two Indic-Languages, Hindi and Bengali. Using our annotated data, our model achieves about 79% F-Score in Hindi and 81% F-Score for Bengali Tweets. Our zero-shot model achieves about 81% F-Score in Hindi and 78% F-Score for Bengali Tweets without any annotated data, which clearly indicates the efficacy of our approach.
Meta-Context Transformers for Domain-Specific Response Generation
Oct 12, 2020


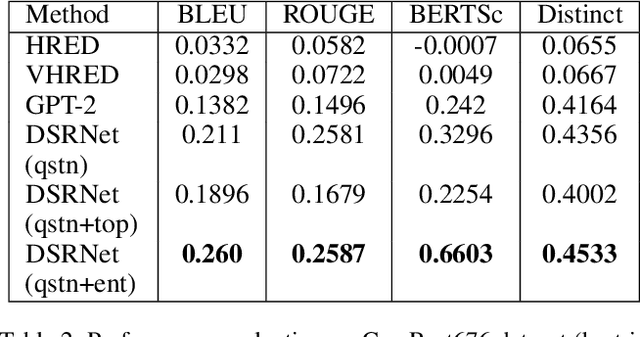
Despite the tremendous success of neural dialogue models in recent years, it suffers a lack of relevance, diversity, and some times coherence in generated responses. Lately, transformer-based models, such as GPT-2, have revolutionized the landscape of dialogue generation by capturing the long-range structures through language modeling. Though these models have exhibited excellent language coherence, they often lack relevance and terms when used for domain-specific response generation. In this paper, we present DSRNet (Domain Specific Response Network), a transformer-based model for dialogue response generation by reinforcing domain-specific attributes. In particular, we extract meta attributes from context and infuse them with the context utterances for better attention over domain-specific key terms and relevance. We study the use of DSRNet in a multi-turn multi-interlocutor environment for domain-specific response generation. In our experiments, we evaluate DSRNet on Ubuntu dialogue datasets, which are mainly composed of various technical domain related dialogues for IT domain issue resolutions and also on CamRest676 dataset, which contains restaurant domain conversations. Trained with maximum likelihood objective, our model shows significant improvement over the state-of-the-art for multi-turn dialogue systems supported by better BLEU and semantic similarity (BertScore) scores. Besides, we also observe that the responses produced by our model carry higher relevance due to the presence of domain-specific key attributes that exhibit better overlap with the attributes of the context. Our analysis shows that the performance improvement is mostly due to the infusion of key terms along with dialogues which result in better attention over domain-relevant terms. Other contributing factors include joint modeling of dialogue context with the domain-specific meta attributes and topics.
Carbon to Diamond: An Incident Remediation Assistant System From Site Reliability Engineers' Conversations in Hybrid Cloud Operations
Oct 12, 2020



Conversational channels are changing the landscape of hybrid cloud service management. These channels are becoming important avenues for Site Reliability Engineers (SREs) %Subject Matter Experts (SME) to collaboratively work together to resolve an incident or issue. Identifying segmented conversations and extracting key insights or artefacts from them can help engineers to improve the efficiency of the incident remediation process by using information retrieval mechanisms for similar incidents. However, it has been empirically observed that due to the semi-formal behavior of such conversations (human language) they are very unique in nature and also contain lot of domain-specific terms. This makes it difficult to use the standard natural language processing frameworks directly, which are popularly used in standard NLP tasks. %It is important to identify the correct keywords and artefacts like symptoms, issue etc., present in the conversation chats. In this paper, we build a framework that taps into the conversational channels and uses various learning methods to (a) understand and extract key artefacts from conversations like diagnostic steps and resolution actions taken, and (b) present an approach to identify past conversations about similar issues. Experimental results on our dataset show the efficacy of our proposed method.
A Unified Labeling Approach by Pooling Diverse Datasets for Entity Typing
Oct 27, 2018
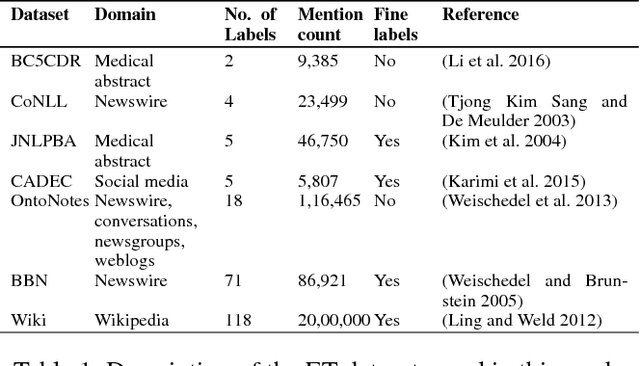
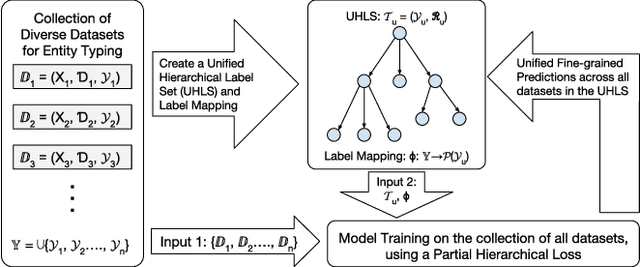
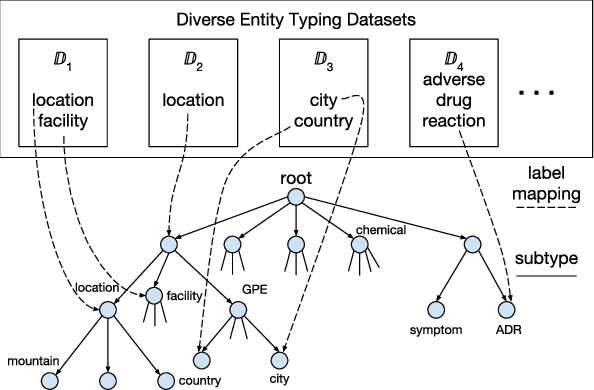
Evolution of entity typing (ET) has led to the generation of multiple datasets. These datasets span from being coarse-grained to fine-grained encompassing numerous domains. Existing works primarily focus on improving the performance of a model on an individual dataset, independently. This narrowly focused view of ET causes two issues: 1) type assignment when information about the test data domain or target label set is not available; 2) fine-grained type prediction when there is no dataset in the same domain with finer-type annotations. Our goal is to shift the focus from individual domain-specific datasets to all the datasets available for ET. In our proposed approach, we convert the label set of all datasets to a unified hierarchical label set while preserving the semantic properties of the individual labels. Then utilizing a partial label loss, we train a single neural network based classifier using every available dataset for the ET task. We empirically evaluate the effectiveness of our approach on seven real-world diverse ET datasets. The results convey that the combined training on multiple datasets helps the model to generalize better and to predict fine-types across all domains without relying on a specific domain or label set information during evaluation.
Deep Domain Adaptation under Deep Label Scarcity
Sep 20, 2018


The goal behind Domain Adaptation (DA) is to leverage the labeled examples from a source domain so as to infer an accurate model in a target domain where labels are not available or in scarce at the best. A state-of-the-art approach for the DA is due to (Ganin et al. 2016), known as DANN, where they attempt to induce a common representation of source and target domains via adversarial training. This approach requires a large number of labeled examples from the source domain to be able to infer a good model for the target domain. However, in many situations obtaining labels in the source domain is expensive which results in deteriorated performance of DANN and limits its applicability in such scenarios. In this paper, we propose a novel approach to overcome this limitation. In our work, we first establish that DANN reduces the original DA problem into a semi-supervised learning problem over the space of common representation. Next, we propose a learning approach, namely TransDANN, that amalgamates adversarial learning and transductive learning to mitigate the detrimental impact of limited source labels and yields improved performance. Experimental results (both on text and images) show a significant boost in the performance of TransDANN over DANN under such scenarios. We also provide theoretical justification for the performance boost.
Unsupervised Controllable Text Formalization
Sep 10, 2018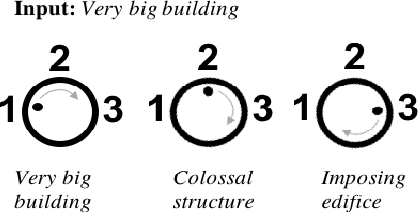
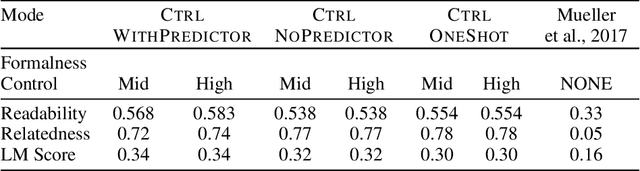
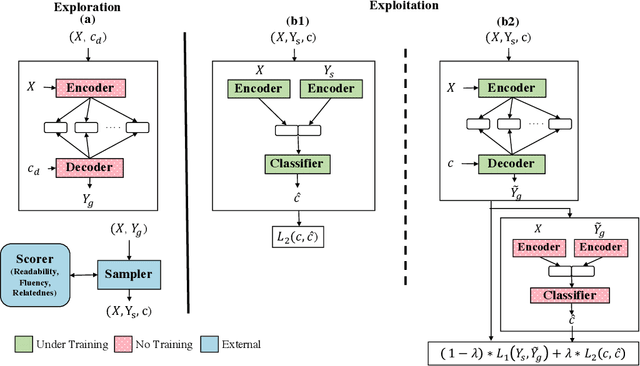
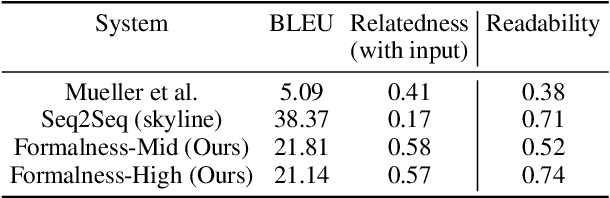
We propose a novel framework for controllable natural language transformation. Realizing that the requirement of parallel corpus is practically unsustainable for controllable generation tasks, an unsupervised training scheme is introduced. The crux of the framework is a deep neural encoder-decoder that is reinforced with text-transformation knowledge through auxiliary modules (called scorers). The scorers, based on off-the-shelf language processing tools, decide the learning scheme of the encoder-decoder based on its actions. We apply this framework for the text-transformation task of formalizing an input text by improving its readability grade; the degree of required formalization can be controlled by the user at run-time. Experiments on public datasets demonstrate the efficacy of our model towards: (a) transforming a given text to a more formal style, and (b) introducing appropriate amount of formalness in the output text pertaining to the input control. Our code and datasets are released for academic use.