 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Labeling Approach by Pooling Diverse Datasets for Entity Typing
Paper and Code
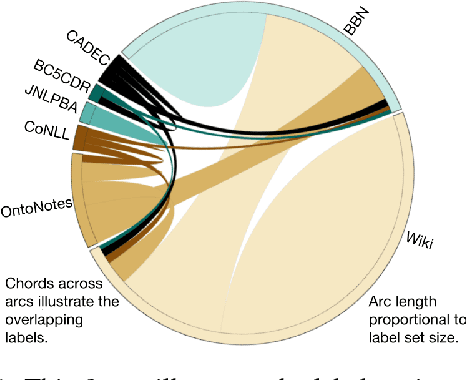
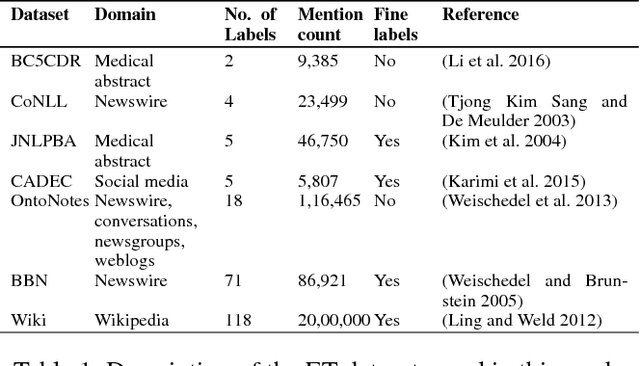
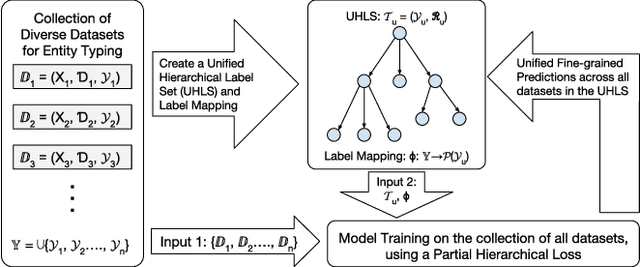
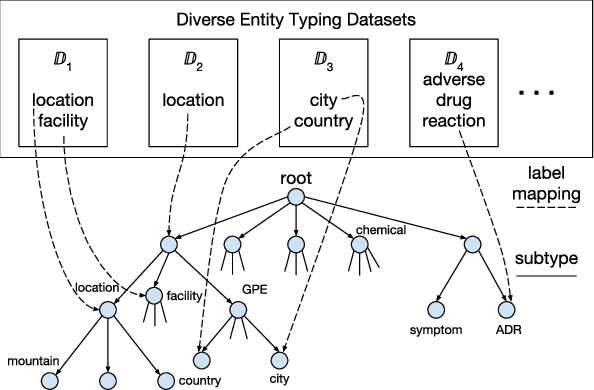
Evolution of entity typing (ET) has led to the generation of multiple datasets. These datasets span from being coarse-grained to fine-grained encompassing numerous domains. Existing works primarily focus on improving the performance of a model on an individual dataset, independently. This narrowly focused view of ET causes two issues: 1) type assignment when information about the test data domain or target label set is not available; 2) fine-grained type prediction when there is no dataset in the same domain with finer-type annotations. Our goal is to shift the focus from individual domain-specific datasets to all the datasets available for ET. In our proposed approach, we convert the label set of all datasets to a unified hierarchical label set while preserving the semantic properties of the individual labels. Then utilizing a partial label loss, we train a single neural network based classifier using every available dataset for the ET task. We empirically evaluate the effectiveness of our approach on seven real-world diverse ET datasets. The results convey that the combined training on multiple datasets helps the model to generalize better and to predict fine-types across all domains without relying on a specific domain or label set information during evaluation.