 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication Specific Compression of Deep Learning Models
Sep 09, 2024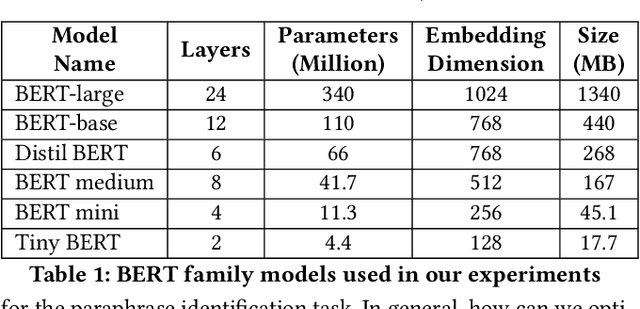
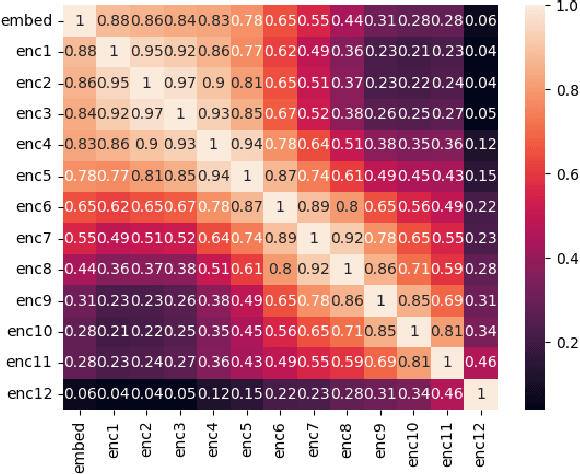
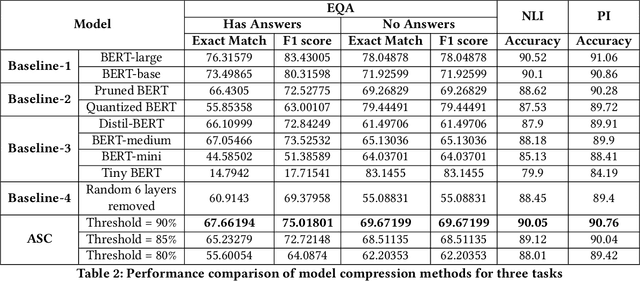
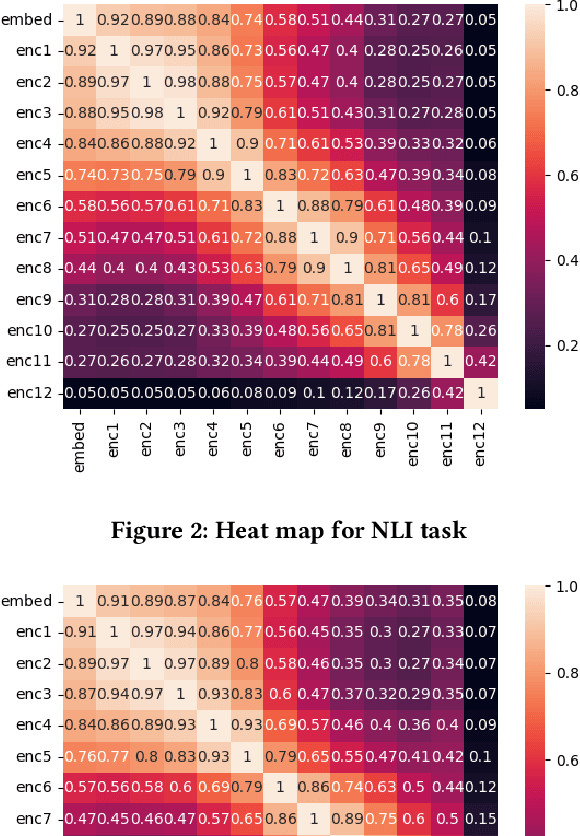
Large Deep Learning models are compressed and deployed for specific applications. However, current Deep Learning model compression methods do not utilize the information about the target application. As a result, the compressed models are application agnostic. Our goal is to customize the model compression process to create a compressed model that will perform better for the target application. Our method, Application Specific Compression (ASC), identifies and prunes components of the large Deep Learning model that are redundant specifically for the given target application. The intuition of our work is to prune the parts of the network that do not contribute significantly to updating the data representation for the given application. We have experimented with the BERT family of models for three applications: Extractive QA, Natural Language Inference, and Paraphrase Identification. We observe that customized compressed models created using ASC method perform better than existing model compression methods and off-the-shelf compressed models.
Compressed models are NOT miniature versions of large models
Jul 18, 2024
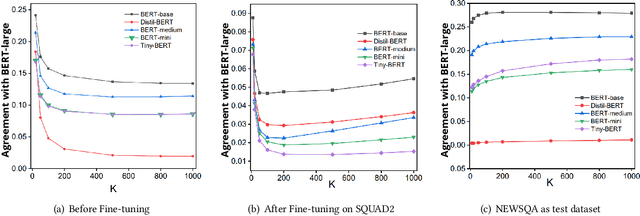
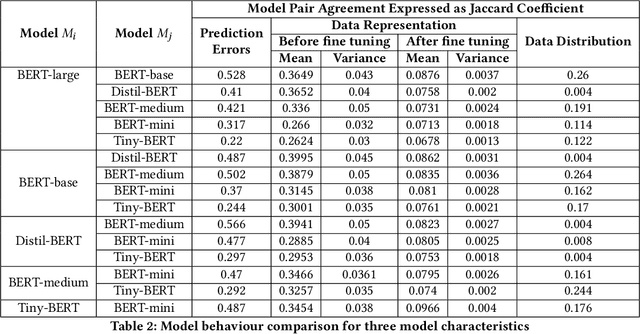
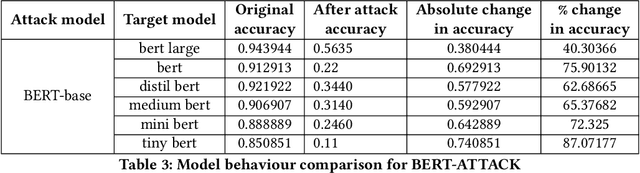
Large neural models are often compressed before deployment. Model compression is necessary for many practical reasons, such as inference latency, memory footprint, and energy consumption. Compressed models are assumed to be miniature versions of corresponding large neural models. However, we question this belief in our work. We compare compressed models with corresponding large neural models using four model characteristics: prediction errors, data representation, data distribution, and vulnerability to adversarial attack. We perform experiments using the BERT-large model and its five compressed versions. For all four model characteristics, compressed models significantly differ from the BERT-large model. Even among compressed models, they differ from each other on all four model characteristics. Apart from the expected loss in model performance, there are major side effects of using compressed models to replace large neural models.
Effect of dimensionality change on the bias of word embeddings
Dec 28, 2023Word embedding methods (WEMs) are extensively used for representing text data. The dimensionality of these embeddings varies across various tasks and implementations. The effect of dimensionality change on the accuracy of the downstream task is a well-explored question. However, how the dimensionality change affects the bias of word embeddings needs to be investigated. Using the English Wikipedia corpus, we study this effect for two static (Word2Vec and fastText) and two context-sensitive (ElMo and BERT) WEMs. We have two observations. First, there is a significant variation in the bias of word embeddings with the dimensionality change. Second, there is no uniformity in how the dimensionality change affects the bias of word embeddings. These factors should be considered while selecting the dimensionality of word embeddings.
Noise in Relation Classification Dataset TACRED: Characterization and Reduction
Nov 21, 2023The overarching objective of this paper is two-fold. First, to explore model-based approaches to characterize the primary cause of the noise. in the RE dataset TACRED Second, to identify the potentially noisy instances. Towards the first objective, we analyze predictions and performance of state-of-the-art (SOTA) models to identify the root cause of noise in the dataset. Our analysis of TACRED shows that the majority of the noise in the dataset originates from the instances labeled as no-relation which are negative examples. For the second objective, we explore two nearest-neighbor-based strategies to automatically identify potentially noisy examples for elimination and reannotation. Our first strategy, referred to as Intrinsic Strategy (IS), is based on the assumption that positive examples are clean. Thus, we have used false-negative predictions to identify noisy negative examples. Whereas, our second approach, referred to as Extrinsic Strategy, is based on using a clean subset of the dataset to identify potentially noisy negative examples. Finally, we retrained the SOTA models on the eliminated and reannotated dataset. Our empirical results based on two SOTA models trained on TACRED-E following the IS show an average 4% F1-score improvement, whereas reannotation (TACRED-R) does not improve the original results. However, following ES, SOTA models show the average F1-score improvement of 3.8% and 4.4% when trained on respective eliminated (TACRED-EN) and reannotated (TACRED-RN) datasets respectively. We further extended the ES for cleaning positive examples as well, which resulted in an average performance improvement of 5.8% and 5.6% for the eliminated (TACRED-ENP) and reannotated (TACRED-RNP) datasets respectively.
Budget Sensitive Reannotation of Noisy Relation Classification Data Using Label Hierarchy
Dec 26, 2021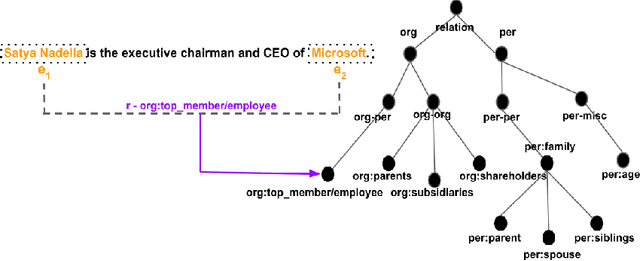
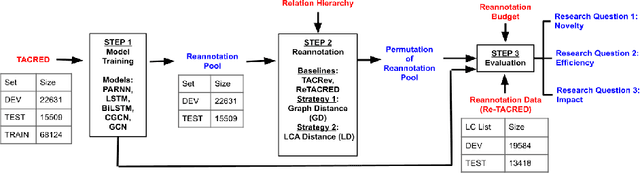

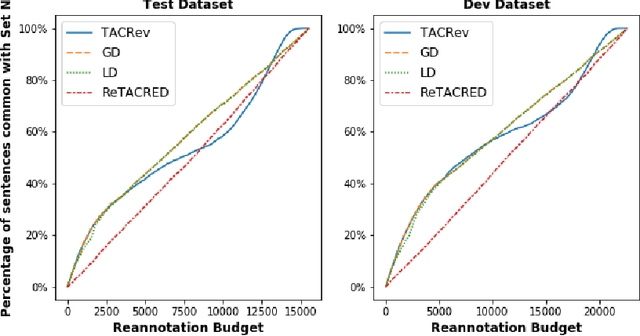
Large crowd-sourced datasets are often noisy and relation classification (RC) datasets are no exception. Reannotating the entire dataset is one probable solution however it is not always viable due to time and budget constraints. This paper addresses the problem of efficient reannotation of a large noisy dataset for the RC. Our goal is to catch more annotation errors in the dataset while reannotating fewer instances. Existing work on RC dataset reannotation lacks the flexibility about how much data to reannotate. We introduce the concept of a reannotation budget to overcome this limitation. The immediate follow-up problem is: Given a specific reannotation budget, which subset of the data should we reannotate? To address this problem, we present two strategies to selectively reannotate RC datasets. Our strategies utilize the taxonomic hierarchy of relation labels. The intuition of our work is to rely on the graph distance between actual and predicted relation labels in the label hierarchy graph. We evaluate our reannotation strategies on the well-known TACRED dataset. We design our experiments to answer three specific research questions. First, does our strategy select novel candidates for reannotation? Second, for a given reannotation budget is our reannotation strategy more efficient at catching annotation errors? Third, what is the impact of data reannotation on RC model performance measurement? Experimental results show that our both reannotation strategies are novel and efficient. Our analysis indicates that the current reported performance of RC models on noisy TACRED data is inflated.
Are Word Embedding Methods Stable and Should We Care About It?
Apr 17, 2021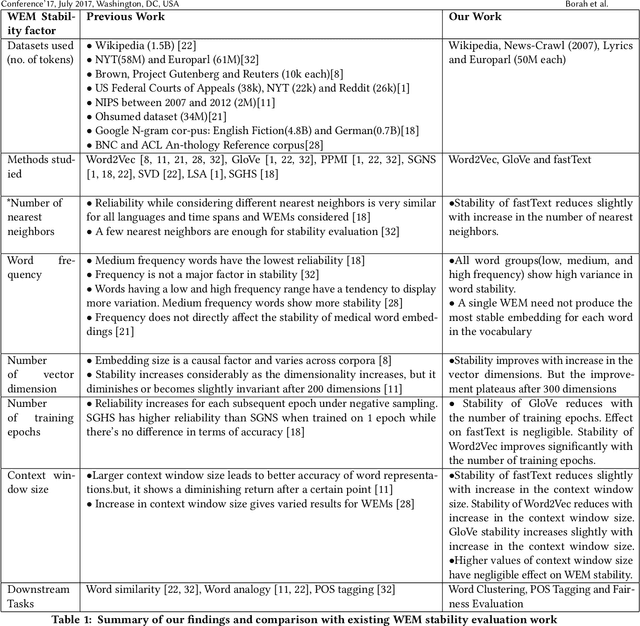
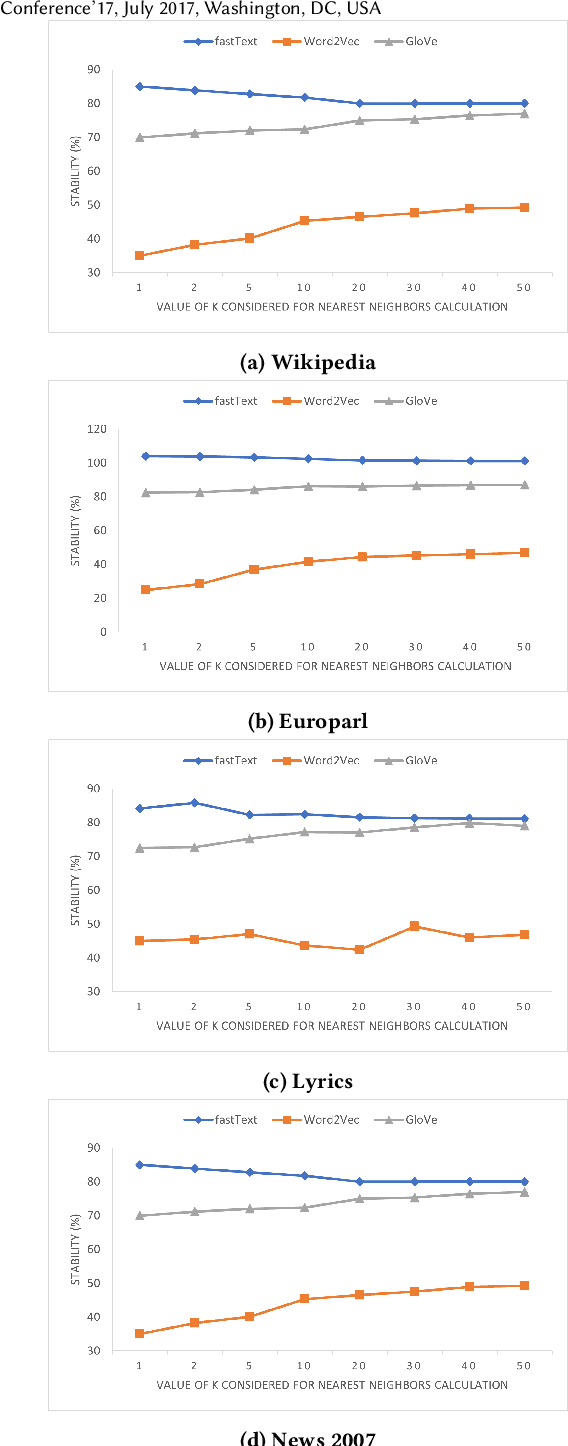
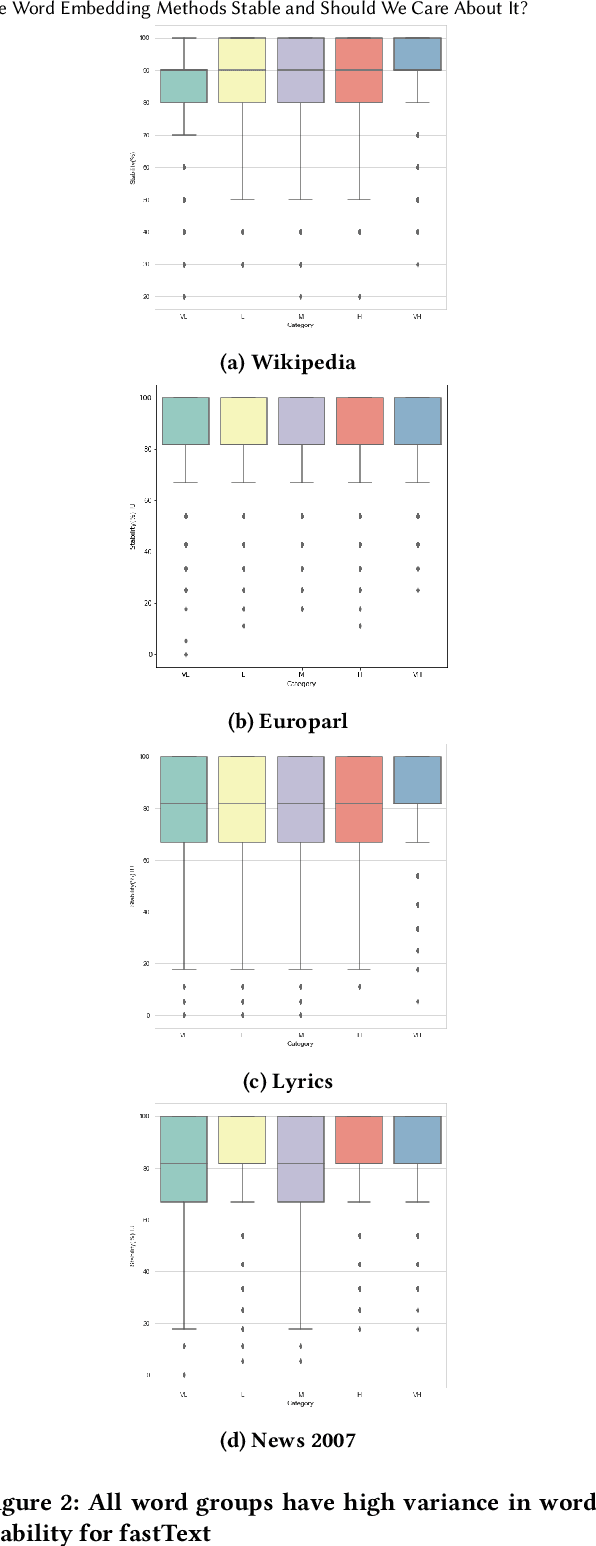
A representation learning method is considered stable if it consistently generates similar representation of the given data across multiple runs. Word Embedding Methods (WEMs) are a class of representation learning methods that generate dense vector representation for each word in the given text data. The central idea of this paper is to explore the stability measurement of WEMs using intrinsic evaluation based on word similarity. We experiment with three popular WEMs: Word2Vec, GloVe, and fastText. For stability measurement, we investigate the effect of five parameters involved in training these models. We perform experiments using four real-world datasets from different domains: Wikipedia, News, Song lyrics, and European parliament proceedings. We also observe the effect of WEM stability on three downstream tasks: Clustering, POS tagging, and Fairness evaluation. Our experiments indicate that amongst the three WEMs, fastText is the most stable, followed by GloVe and Word2Vec.
Taxonomical hierarchy of canonicalized relations from multiple Knowledge Bases
Sep 17, 2019
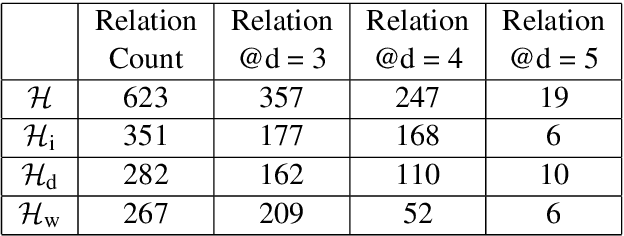


This work addresses two important questions pertinent to Relation Extraction (RE). First, what are all possible relations that could exist between any two given entity types? Second, how do we define an unambiguous taxonomical (is-a) hierarchy among the identified relations? To address the first question, we use three resources Wikipedia Infobox, Wikidata, and DBpedia. This study focuses on relations between person, organization and location entity types. We exploit Wikidata and DBpedia in a data-driven manner, and Wikipedia Infobox templates manually to generate lists of relations. Further, to address the second question, we canonicalize, filter, and combine the identified relations from the three resources to construct a taxonomical hierarchy. This hierarchy contains 623 canonical relations with highest contribution from Wikipedia Infobox followed by DBpedia and Wikidata. The generated relation list subsumes an average of 85% of relations from RE datasets when entity types are restricted.
Decoding the Style and Bias of Song Lyrics
Jul 17, 2019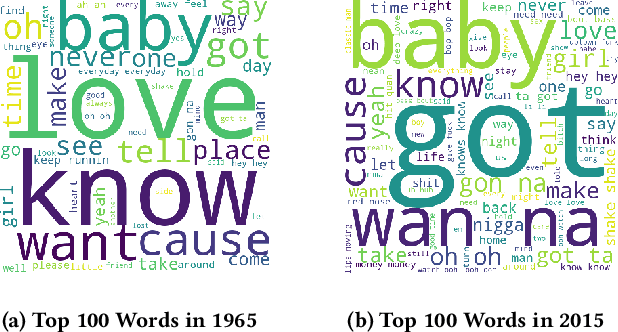
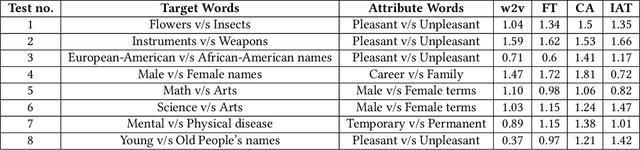
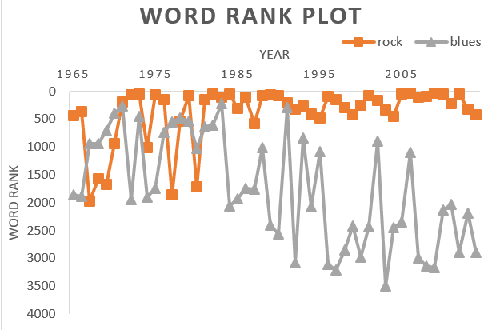
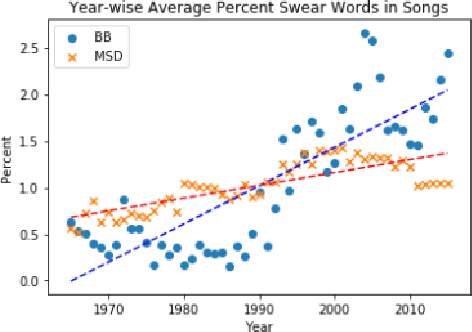
The central idea of this paper is to gain a deeper understanding of song lyrics computationally. We focus on two aspects: style and biases of song lyrics. All prior works to understand these two aspects are limited to manual analysis of a small corpus of song lyrics. In contrast, we analyzed more than half a million songs spread over five decades. We characterize the lyrics style in terms of vocabulary, length, repetitiveness, speed, and readability. We have observed that the style of popular songs significantly differs from other songs. We have used distributed representation methods and WEAT test to measure various gender and racial biases in the song lyrics. We have observed that biases in song lyrics correlate with prior results on human subjects. This correlation indicates that song lyrics reflect the biases that exist in society. Increasing consumption of music and the effect of lyrics on human emotions makes this analysis important.
Fine-grained Entity Recognition with Reduced False Negatives and Large Type Coverage
Apr 30, 2019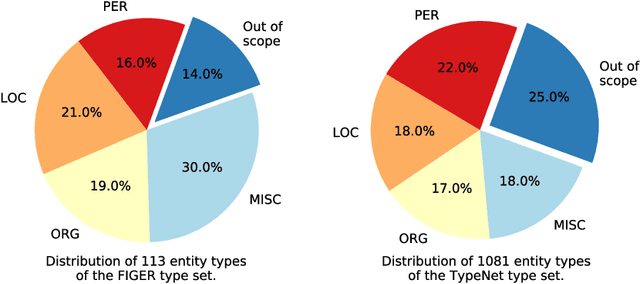


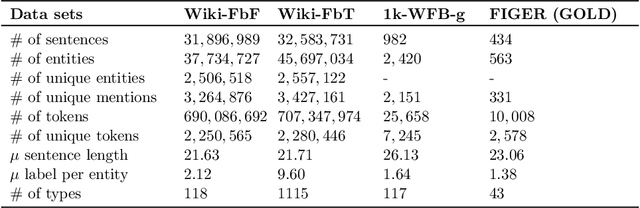
Fine-grained Entity Recognition (FgER) is the task of detecting and classifying entity mentions to a large set of types spanning diverse domains such as biomedical, finance and sports. We observe that when the type set spans several domains, detection of entity mention becomes a limitation for supervised learning models. The primary reason being lack of dataset where entity boundaries are properly annotated while covering a large spectrum of entity types. Our work directly addresses this issue. We propose Heuristics Allied with Distant Supervision (HAnDS) framework to automatically construct a quality dataset suitable for the FgER task. HAnDS framework exploits the high interlink among Wikipedia and Freebase in a pipelined manner, reducing annotation errors introduced by naively using distant supervision approach. Using HAnDS framework, we create two datasets, one suitable for building FgER systems recognizing up to 118 entity types based on the FIGER type hierarchy and another for up to 1115 entity types based on the TypeNet hierarchy. Our extensive empirical experimentation warrants the quality of the generated datasets. Along with this, we also provide a manually annotated dataset for benchmarking FgER systems.
A Unified Labeling Approach by Pooling Diverse Datasets for Entity Typing
Oct 27, 2018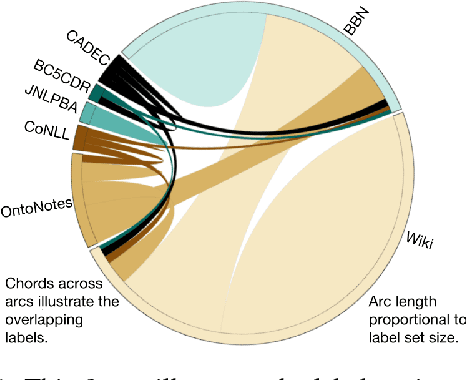
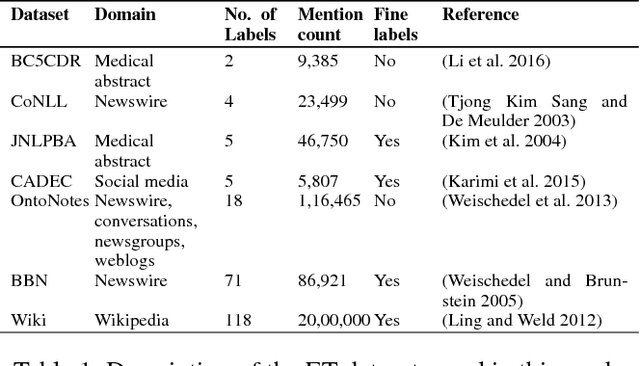
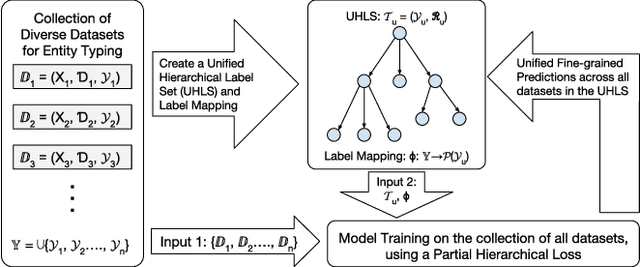
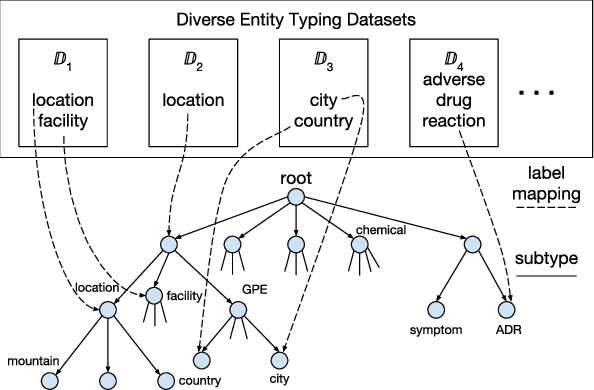
Evolution of entity typing (ET) has led to the generation of multiple datasets. These datasets span from being coarse-grained to fine-grained encompassing numerous domains. Existing works primarily focus on improving the performance of a model on an individual dataset, independently. This narrowly focused view of ET causes two issues: 1) type assignment when information about the test data domain or target label set is not available; 2) fine-grained type prediction when there is no dataset in the same domain with finer-type annotations. Our goal is to shift the focus from individual domain-specific datasets to all the datasets available for ET. In our proposed approach, we convert the label set of all datasets to a unified hierarchical label set while preserving the semantic properties of the individual labels. Then utilizing a partial label loss, we train a single neural network based classifier using every available dataset for the ET task. We empirically evaluate the effectiveness of our approach on seven real-world diverse ET datasets. The results convey that the combined training on multiple datasets helps the model to generalize better and to predict fine-types across all domains without relying on a specific domain or label set information during evaluation.