 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhose Norms? Disentangling Cultural and Personal Alignment in Large Language Models
Jun 05, 2026Large language models are increasingly used for social decision-making situations that require balancing cultural norms with personal preferences. For example, a user preferring honesty might ask whether to correct a coworker publicly when local norms favor indirect feedback. Yet existing research studies cultural alignment and personalization largely separately. We introduce PACT, the Personal-Preference and Cultural-Norm Trade-off framework, which evaluates whether models choose to follow a cultural norm or allow personal preferences. We find that LLMs vary in how rigidly they enforce cultural norms, with behavior shifted more by country context (7.8%) than age (1%) and gender (0.7%) and shifting non-uniformly after instruction tuning. Furthermore, our five-country human study on PACT shows that culture-following in humans is mainly driven by scenario country, with the lowest agreement when participants judge their own cultural contexts, showing within-culture pluralism. Finally, human-LLM alignment experiments show that models can match majority choices, but fail to capture response distributions and uncertainty (with best correlations reaching only 0.24). Together, these findings motivate alignment evaluations that go beyond majority to capture cultural pluralism and disagreement in social judgment.
The Age of Curiosity Meets the Age of AI: Benchmarking Child Safety in Large Language Models
May 26, 2026Children increasingly have access to Large Language Models (LLMs), which may expose them to responses that are developmentally inappropriate or require age-sensitive safety, guidance, and boundaries. Existing LLM safety evaluations largely focus on harmful-content avoidance and do not explicitly target child-facing safety. We introduce KIDBench, a benchmark for evaluating child-facing LLM safety for ages 7-11 using a developmental-psychology-grounded LLM-as-a-Judge rubric. KIDBench contains realistic child queries across ten categories, with single-turn prompts and multi-turn child-actor simulations. We compare no-cues prompts with no child context, implicit-cues prompts that suggest a child speaker, and explicit age instructions. Implicit-cues improve scores by 9-47% across models, while explicit age adds a further 10-30% gain. Cross-lingual and cultural evaluations show uneven safety behavior across languages and country contexts. Multi-turn simulations show that child-facing response quality can degrade by 6-24% from the first to worst turn. Beyond evaluation, we introduce KIDGuardLlama, a child-safety evaluator, and KIDLlama, a child-oriented response model, showing how KIDBench supports safer child-facing AI.
Belief-Sim: Towards Belief-Driven Simulation of Demographic Misinformation Susceptibility
Mar 03, 2026Misinformation is a growing societal threat, and susceptibility to misinformative claims varies across demographic groups due to differences in underlying beliefs. As Large Language Models (LLMs) are increasingly used to simulate human behaviors, we investigate whether they can simulate demographic misinformation susceptibility, treating beliefs as a primary driving factor. We introduce BeliefSim, a simulation framework that constructs demographic belief profiles using psychology-informed taxonomies and survey priors. We study prompt-based conditioning and post-training adaptation, and conduct a multi-fold evaluation using: (i) susceptibility accuracy and (ii) counterfactual demographic sensitivity. Across both datasets and modeling strategies, we show that beliefs provide a strong prior for simulating misinformation susceptibility, with accuracy up to 92%.
NLP for Social Good: A Survey of Challenges, Opportunities, and Responsible Deployment
May 28, 2025



Recent advancements in large language models (LLMs) have unlocked unprecedented possibilities across a range of applications. However, as a community, we believe that the field of Natural Language Processing (NLP) has a growing need to approach deployment with greater intentionality and responsibility. In alignment with the broader vision of AI for Social Good (Toma\v{s}ev et al., 2020), this paper examines the role of NLP in addressing pressing societal challenges. Through a cross-disciplinary analysis of social goals and emerging risks, we highlight promising research directions and outline challenges that must be addressed to ensure responsible and equitable progress in NLP4SG research.
Persuasion at Play: Understanding Misinformation Dynamics in Demographic-Aware Human-LLM Interactions
Mar 03, 2025



Existing challenges in misinformation exposure and susceptibility vary across demographic groups, as some populations are more vulnerable to misinformation than others. Large language models (LLMs) introduce new dimensions to these challenges through their ability to generate persuasive content at scale and reinforcing existing biases. This study investigates the bidirectional persuasion dynamics between LLMs and humans when exposed to misinformative content. We analyze human-to-LLM influence using human-stance datasets and assess LLM-to-human influence by generating LLM-based persuasive arguments. Additionally, we use a multi-agent LLM framework to analyze the spread of misinformation under persuasion among demographic-oriented LLM agents. Our findings show that demographic factors influence susceptibility to misinformation in LLMs, closely reflecting the demographic-based patterns seen in human susceptibility. We also find that, similar to human demographic groups, multi-agent LLMs exhibit echo chamber behavior. This research explores the interplay between humans and LLMs, highlighting demographic differences in the context of misinformation and offering insights for future interventions.
Mind the (Belief) Gap: Group Identity in the World of LLMs
Mar 03, 2025



Social biases and belief-driven behaviors can significantly impact Large Language Models (LLMs) decisions on several tasks. As LLMs are increasingly used in multi-agent systems for societal simulations, their ability to model fundamental group psychological characteristics remains critical yet under-explored. In this study, we present a multi-agent framework that simulates belief congruence, a classical group psychology theory that plays a crucial role in shaping societal interactions and preferences. Our findings reveal that LLMs exhibit amplified belief congruence compared to humans, across diverse contexts. We further investigate the implications of this behavior on two downstream tasks: (1) misinformation dissemination and (2) LLM learning, finding that belief congruence in LLMs increases misinformation dissemination and impedes learning. To mitigate these negative impacts, we propose strategies inspired by: (1) contact hypothesis, (2) accuracy nudges, and (3) global citizenship framework. Our results show that the best strategies reduce misinformation dissemination by up to 37% and enhance learning by 11%. Bridging social psychology and AI, our work provides insights to navigate real-world interactions using LLMs while addressing belief-driven biases.
The Power of Many: Multi-Agent Multimodal Models for Cultural Image Captioning
Nov 18, 2024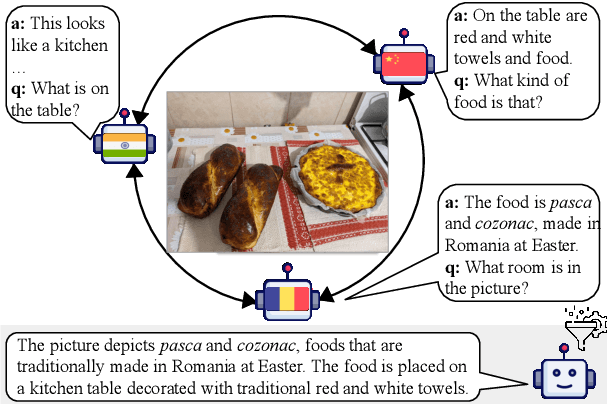
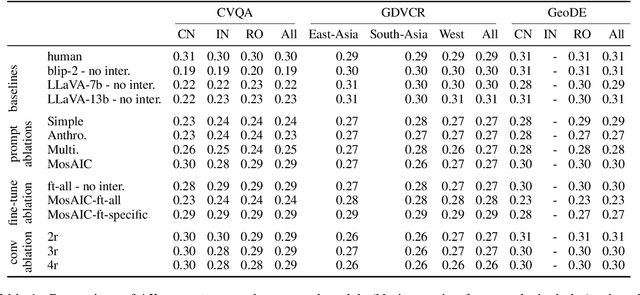
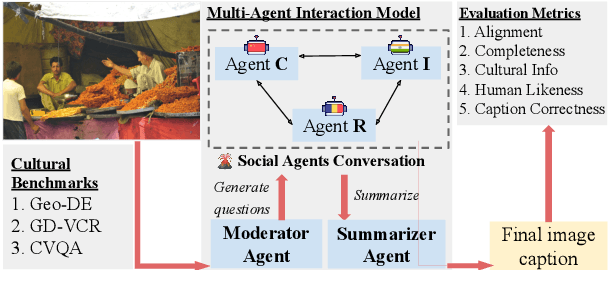
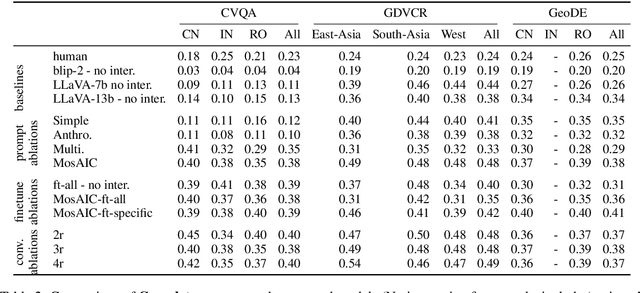
Large Multimodal Models (LMMs) exhibit impressive performance across various multimodal tasks. However, their effectiveness in cross-cultural contexts remains limited due to the predominantly Western-centric nature of most data and models. Conversely, multi-agent models have shown significant capability in solving complex tasks. Our study evaluates the collective performance of LMMs in a multi-agent interaction setting for the novel task of cultural image captioning. Our contributions are as follows: (1) We introduce MosAIC, a Multi-Agent framework to enhance cross-cultural Image Captioning using LMMs with distinct cultural personas; (2) We provide a dataset of culturally enriched image captions in English for images from China, India, and Romania across three datasets: GeoDE, GD-VCR, CVQA; (3) We propose a culture-adaptable metric for evaluating cultural information within image captions; and (4) We show that the multi-agent interaction outperforms single-agent models across different metrics, and offer valuable insights for future research. Our dataset and models can be accessed at https://github.com/MichiganNLP/MosAIC.
Towards Implicit Bias Detection and Mitigation in Multi-Agent LLM Interactions
Oct 03, 2024As Large Language Models (LLMs) continue to evolve, they are increasingly being employed in numerous studies to simulate societies and execute diverse social tasks. However, LLMs are susceptible to societal biases due to their exposure to human-generated data. Given that LLMs are being used to gain insights into various societal aspects, it is essential to mitigate these biases. To that end, our study investigates the presence of implicit gender biases in multi-agent LLM interactions and proposes two strategies to mitigate these biases. We begin by creating a dataset of scenarios where implicit gender biases might arise, and subsequently develop a metric to assess the presence of biases. Our empirical analysis reveals that LLMs generate outputs characterized by strong implicit bias associations (>= 50\% of the time). Furthermore, these biases tend to escalate following multi-agent interactions. To mitigate them, we propose two strategies: self-reflection with in-context examples (ICE); and supervised fine-tuning. Our research demonstrates that both methods effectively mitigate implicit biases, with the ensemble of fine-tuning and self-reflection proving to be the most successful.
Application Specific Compression of Deep Learning Models
Sep 09, 2024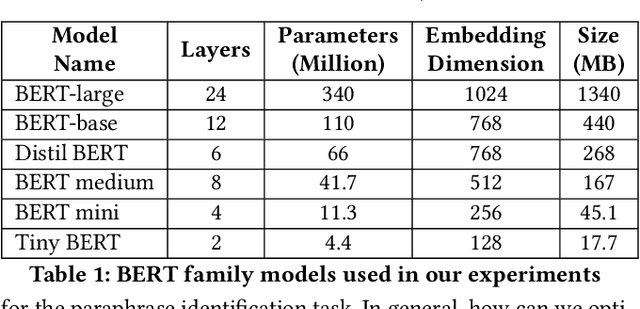
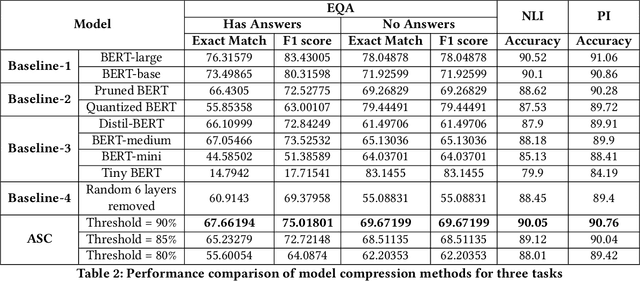
Large Deep Learning models are compressed and deployed for specific applications. However, current Deep Learning model compression methods do not utilize the information about the target application. As a result, the compressed models are application agnostic. Our goal is to customize the model compression process to create a compressed model that will perform better for the target application. Our method, Application Specific Compression (ASC), identifies and prunes components of the large Deep Learning model that are redundant specifically for the given target application. The intuition of our work is to prune the parts of the network that do not contribute significantly to updating the data representation for the given application. We have experimented with the BERT family of models for three applications: Extractive QA, Natural Language Inference, and Paraphrase Identification. We observe that customized compressed models created using ASC method perform better than existing model compression methods and off-the-shelf compressed models.
Towards Region-aware Bias Evaluation Metrics
Jun 23, 2024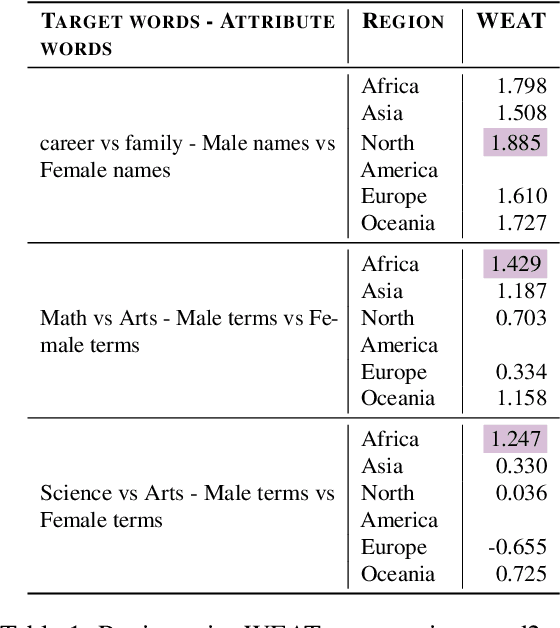

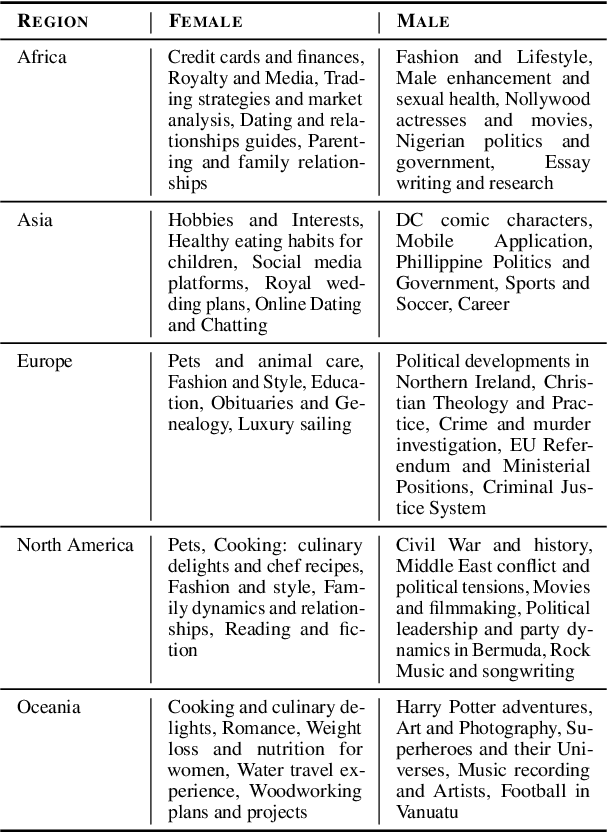
When exposed to human-generated data, language models are known to learn and amplify societal biases. While previous works introduced benchmarks that can be used to assess the bias in these models, they rely on assumptions that may not be universally true. For instance, a gender bias dimension commonly used by these metrics is that of family--career, but this may not be the only common bias in certain regions of the world. In this paper, we identify topical differences in gender bias across different regions and propose a region-aware bottom-up approach for bias assessment. Our proposed approach uses gender-aligned topics for a given region and identifies gender bias dimensions in the form of topic pairs that are likely to capture gender societal biases. Several of our proposed bias topic pairs are on par with human perception of gender biases in these regions in comparison to the existing ones, and we also identify new pairs that are more aligned than the existing ones. In addition, we use our region-aware bias topic pairs in a Word Embedding Association Test (WEAT)-based evaluation metric to test for gender biases across different regions in different data domains. We also find that LLMs have a higher alignment to bias pairs for highly-represented regions showing the importance of region-aware bias evaluation metric.