 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP for Social Good: A Survey of Challenges, Opportunities, and Responsible Deployment
May 28, 2025



Recent advancements in large language models (LLMs) have unlocked unprecedented possibilities across a range of applications. However, as a community, we believe that the field of Natural Language Processing (NLP) has a growing need to approach deployment with greater intentionality and responsibility. In alignment with the broader vision of AI for Social Good (Toma\v{s}ev et al., 2020), this paper examines the role of NLP in addressing pressing societal challenges. Through a cross-disciplinary analysis of social goals and emerging risks, we highlight promising research directions and outline challenges that must be addressed to ensure responsible and equitable progress in NLP4SG research.
DiversityMedQA: Assessing Demographic Biases in Medical Diagnosis using Large Language Models
Sep 02, 2024



As large language models (LLMs) gain traction in healthcare, concerns about their susceptibility to demographic biases are growing. We introduce {DiversityMedQA}, a novel benchmark designed to assess LLM responses to medical queries across diverse patient demographics, such as gender and ethnicity. By perturbing questions from the MedQA dataset, which comprises medical board exam questions, we created a benchmark that captures the nuanced differences in medical diagnosis across varying patient profiles. Our findings reveal notable discrepancies in model performance when tested against these demographic variations. Furthermore, to ensure the perturbations were accurate, we also propose a filtering strategy that validates each perturbation. By releasing DiversityMedQA, we provide a resource for evaluating and mitigating demographic bias in LLM medical diagnoses.
PhenoTagger: A Hybrid Method for Phenotype Concept Recognition using Human Phenotype Ontology
Sep 17, 2020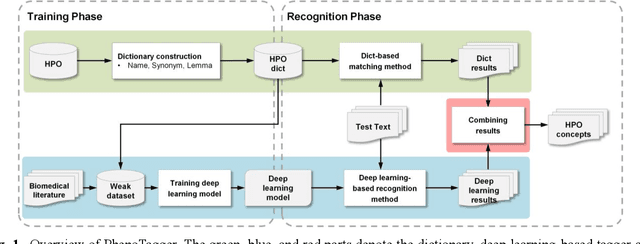
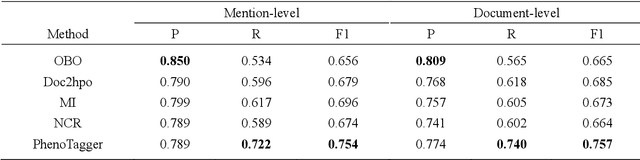
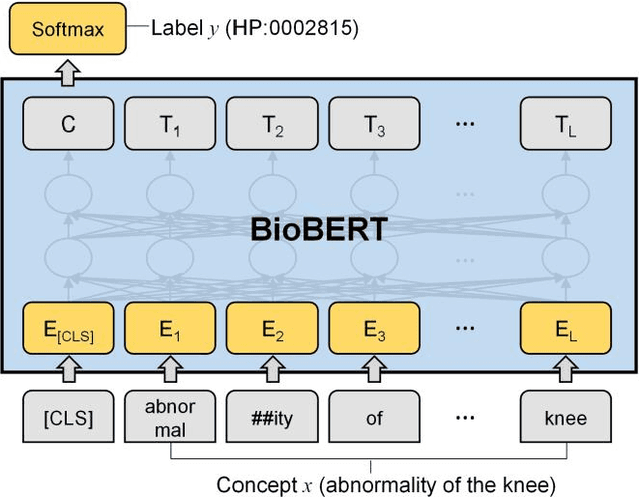
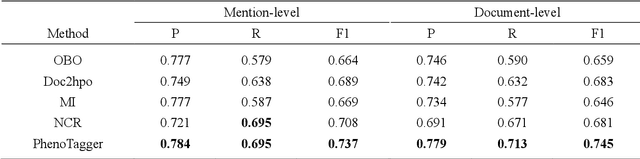
Automatic phenotype concept recognition from unstructured text remains a challenging task in biomedical text mining research. Previous works that address the task typically use dictionary-based matching methods, which can achieve high precision but suffer from lower recall. Recently, machine learning-based methods have been proposed to identify biomedical concepts, which can recognize more unseen concept synonyms by automatic feature learning. However, most methods require large corpora of manually annotated data for model training, which is difficult to obtain due to the high cost of human annotation. In this paper, we propose PhenoTagger, a hybrid method that combines both dictionary and machine learning-based methods to recognize Human Phenotype Ontology (HPO) concepts in unstructured biomedical text. We first use all concepts and synonyms in HPO to construct a dictionary. Then, the dictionary and biomedical literature are used to automatically build a weakly-supervised training dataset for machine learning. Next, a cutting-edge deep learning model is trained to classify each candidate phrase into a corresponding concept label. Finally, the dictionary and machine learning-based prediction results are combined for improved performance. Our method is validated with two HPO corpora, and the results show that PhenoTagger compares favorably to state-of-the-art methods. In addition, to demonstrate the generalizability of our method, we retrained PhenoTagger using the disease ontology MEDIC for disease concept recognition to investigate the effect of training on different ontologies. Experimental results on the NCBI disease corpus show that PhenoTagger without requiring manually annotated training data achieves competitive performance as compared with state-of-the-art supervised methods.