 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP for Social Good: A Survey of Challenges, Opportunities, and Responsible Deployment
May 28, 2025



Recent advancements in large language models (LLMs) have unlocked unprecedented possibilities across a range of applications. However, as a community, we believe that the field of Natural Language Processing (NLP) has a growing need to approach deployment with greater intentionality and responsibility. In alignment with the broader vision of AI for Social Good (Toma\v{s}ev et al., 2020), this paper examines the role of NLP in addressing pressing societal challenges. Through a cross-disciplinary analysis of social goals and emerging risks, we highlight promising research directions and outline challenges that must be addressed to ensure responsible and equitable progress in NLP4SG research.
Hermit Kingdom Through the Lens of Multiple Perspectives: A Case Study of LLM Hallucination on North Korea
Jan 10, 2025Hallucination in large language models (LLMs) remains a significant challenge for their safe deployment, particularly due to its potential to spread misinformation. Most existing solutions address this challenge by focusing on aligning the models with credible sources or by improving how models communicate their confidence (or lack thereof) in their outputs. While these measures may be effective in most contexts, they may fall short in scenarios requiring more nuanced approaches, especially in situations where access to accurate data is limited or determining credible sources is challenging. In this study, we take North Korea - a country characterised by an extreme lack of reliable sources and the prevalence of sensationalist falsehoods - as a case study. We explore and evaluate how some of the best-performing multilingual LLMs and specific language-based models generate information about North Korea in three languages spoken in countries with significant geo-political interests: English (United States, United Kingdom), Korean (South Korea), and Mandarin Chinese (China). Our findings reveal significant differences, suggesting that the choice of model and language can lead to vastly different understandings of North Korea, which has important implications given the global security challenges the country poses.
Aligning Large Language Models with Diverse Political Viewpoints
Jun 20, 2024Large language models such as ChatGPT often exhibit striking political biases. If users query them about political information, they might take a normative stance and reinforce such biases. To overcome this, we align LLMs with diverse political viewpoints from 100,000 comments written by candidates running for national parliament in Switzerland. Such aligned models are able to generate more accurate political viewpoints from Swiss parties compared to commercial models such as ChatGPT. We also propose a procedure to generate balanced overviews from multiple viewpoints using such models.
Problem-Solving Guide: Predicting the Algorithm Tags and Difficulty for Competitive Programming Problems
Oct 09, 2023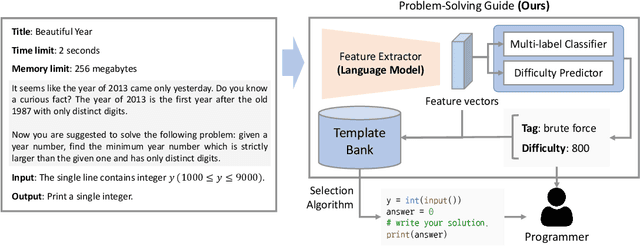
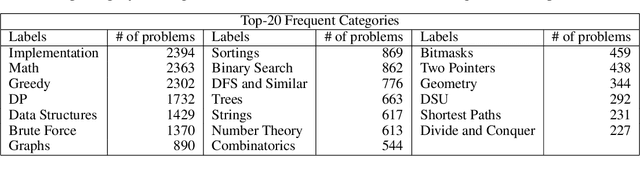
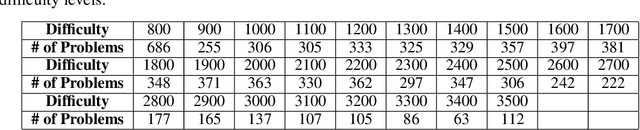
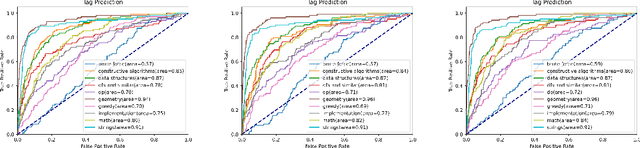
The recent program development industries have required problem-solving abilities for engineers, especially application developers. However, AI-based education systems to help solve computer algorithm problems have not yet attracted attention, while most big tech companies require the ability to solve algorithm problems including Google, Meta, and Amazon. The most useful guide to solving algorithm problems might be guessing the category (tag) of the facing problems. Therefore, our study addresses the task of predicting the algorithm tag as a useful tool for engineers and developers. Moreover, we also consider predicting the difficulty levels of algorithm problems, which can be used as useful guidance to calculate the required time to solve that problem. In this paper, we present a real-world algorithm problem multi-task dataset, AMT, by mainly collecting problem samples from the most famous and large competitive programming website Codeforces. To the best of our knowledge, our proposed dataset is the most large-scale dataset for predicting algorithm tags compared to previous studies. Moreover, our work is the first to address predicting the difficulty levels of algorithm problems. We present a deep learning-based novel method for simultaneously predicting algorithm tags and the difficulty levels of an algorithm problem given. All datasets and source codes are available at https://github.com/sronger/PSG_Predicting_Algorithm_Tags_and_Difficulty.