 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHermit Kingdom Through the Lens of Multiple Perspectives: A Case Study of LLM Hallucination on North Korea
Jan 10, 2025Hallucination in large language models (LLMs) remains a significant challenge for their safe deployment, particularly due to its potential to spread misinformation. Most existing solutions address this challenge by focusing on aligning the models with credible sources or by improving how models communicate their confidence (or lack thereof) in their outputs. While these measures may be effective in most contexts, they may fall short in scenarios requiring more nuanced approaches, especially in situations where access to accurate data is limited or determining credible sources is challenging. In this study, we take North Korea - a country characterised by an extreme lack of reliable sources and the prevalence of sensationalist falsehoods - as a case study. We explore and evaluate how some of the best-performing multilingual LLMs and specific language-based models generate information about North Korea in three languages spoken in countries with significant geo-political interests: English (United States, United Kingdom), Korean (South Korea), and Mandarin Chinese (China). Our findings reveal significant differences, suggesting that the choice of model and language can lead to vastly different understandings of North Korea, which has important implications given the global security challenges the country poses.
SIPSA-Net: Shift-Invariant Pan Sharpening with Moving Object Alignment for Satellite Imagery
May 06, 2021
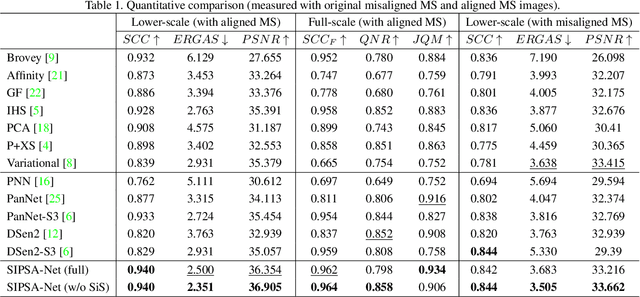
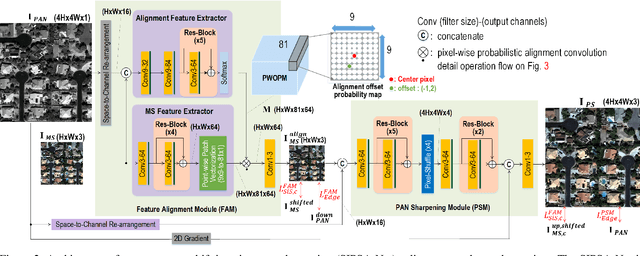
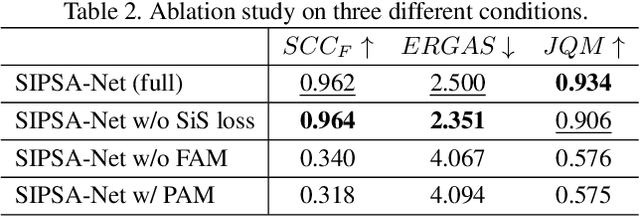
Pan-sharpening is a process of merging a high-resolution (HR) panchromatic (PAN) image and its corresponding low-resolution (LR) multi-spectral (MS) image to create an HR-MS and pan-sharpened image. However, due to the different sensors' locations, characteristics and acquisition time, PAN and MS image pairs often tend to have various amounts of misalignment. Conventional deep-learning-based methods that were trained with such misaligned PAN-MS image pairs suffer from diverse artifacts such as double-edge and blur artifacts in the resultant PAN-sharpened images. In this paper, we propose a novel framework called shift-invariant pan-sharpening with moving object alignment (SIPSA-Net) which is the first method to take into account such large misalignment of moving object regions for PAN sharpening. The SISPA-Net has a feature alignment module (FAM) that can adjust one feature to be aligned to another feature, even between the two different PAN and MS domains. For better alignment in pan-sharpened images, a shift-invariant spectral loss is newly designed, which ignores the inherent misalignment in the original MS input, thereby having the same effect as optimizing the spectral loss with a well-aligned MS image. Extensive experimental results show that our SIPSA-Net can generate pan-sharpened images with remarkable improvements in terms of visual quality and alignment, compared to the state-of-the-art methods.
Deep HVS-IQA Net: Human Visual System Inspired Deep Image Quality Assessment Networks
Feb 14, 2019
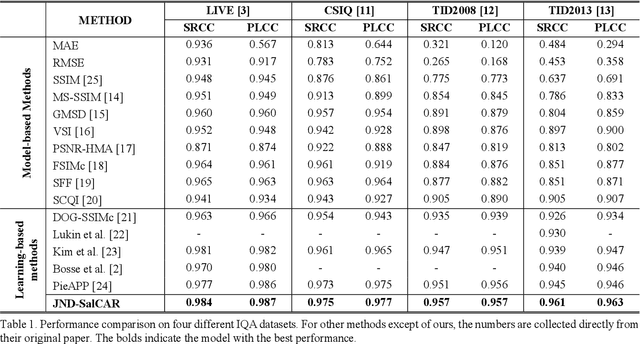
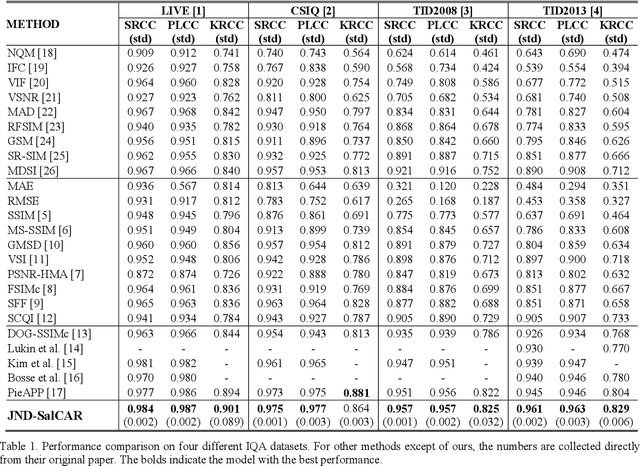
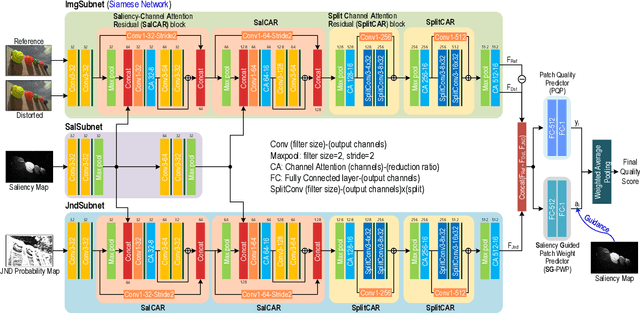
In image quality enhancement processing, it is the most important to predict how humans perceive processed images since human observers are the ultimate receivers of the images. Thus, objective image quality assessment (IQA) methods based on human visual sensitivity from psychophysical experiments have been extensively studied. Thanks to the powerfulness of deep convolutional neural networks (CNN), many CNN based IQA models have been studied. However, previous CNN-based IQA models have not fully utilized the characteristics of human visual systems (HVS) for IQA problems by simply entrusting everything to CNN where the CNN-based models are often trained as a regressor to predict the scores of subjective quality assessment obtained from IQA datasets. In this paper, we propose a novel HVS-inspired deep IQA network, called Deep HVS-IQA Net, where the human psychophysical characteristics such as visual saliency and just noticeable difference (JND) are incorporated at the front-end of the Deep HVS-IQA Net. To our best knowledge, our work is the first HVS-inspired trainable IQA network that considers both the visual saliency and JND characteristics of HVS. Furthermore, we propose a rank loss to train our Deep HVS-IQA Net effectively so that perceptually important features can be extracted for image quality prediction. The rank loss can penalize the Deep HVS-IQA Net when the order of its predicted quality scores is different from that of the ground truth scores. We evaluate the proposed Deep HVS-IQA Net on large IQA datasets where it outperforms all the recent state-of-the-art IQA methods.