 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-Guided Attribute Aware Pretraining for Generalizable Image Quality Assessment
Jun 03, 2024In no-reference image quality assessment (NR-IQA), the challenge of limited dataset sizes hampers the development of robust and generalizable models. Conventional methods address this issue by utilizing large datasets to extract rich representations for IQA. Also, some approaches propose vision language models (VLM) based IQA, but the domain gap between generic VLM and IQA constrains their scalability. In this work, we propose a novel pretraining framework that constructs a generalizable representation for IQA by selectively extracting quality-related knowledge from VLM and leveraging the scalability of large datasets. Specifically, we carefully select optimal text prompts for five representative image quality attributes and use VLM to generate pseudo-labels. Numerous attribute-aware pseudo-labels can be generated with large image datasets, allowing our IQA model to learn rich representations about image quality. Our approach achieves state-of-the-art performance on multiple IQA datasets and exhibits remarkable generalization capabilities. Leveraging these strengths, we propose several applications, such as evaluating image generation models and training image enhancement models, demonstrating our model's real-world applicability. We will make the code available for access.
Information-Theoretic GAN Compression with Variational Energy-based Model
Mar 28, 2023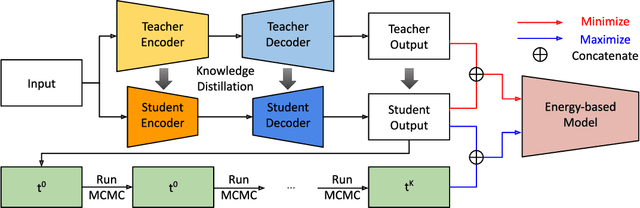
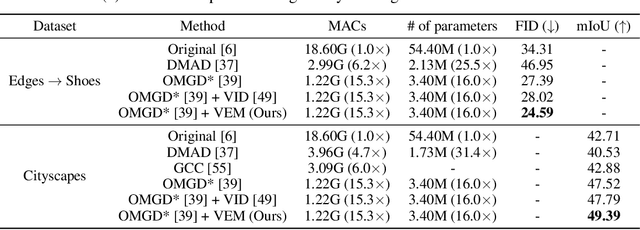

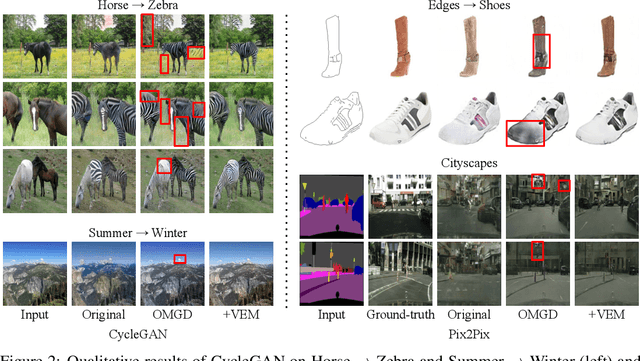
We propose an information-theoretic knowledge distillation approach for the compression of generative adversarial networks, which aims to maximize the mutual information between teacher and student networks via a variational optimization based on an energy-based model. Because the direct computation of the mutual information in continuous domains is intractable, our approach alternatively optimizes the student network by maximizing the variational lower bound of the mutual information. To achieve a tight lower bound, we introduce an energy-based model relying on a deep neural network to represent a flexible variational distribution that deals with high-dimensional images and consider spatial dependencies between pixels, effectively. Since the proposed method is a generic optimization algorithm, it can be conveniently incorporated into arbitrary generative adversarial networks and even dense prediction networks, e.g., image enhancement models. We demonstrate that the proposed algorithm achieves outstanding performance in model compression of generative adversarial networks consistently when combined with several existing models.
Deep HVS-IQA Net: Human Visual System Inspired Deep Image Quality Assessment Networks
Feb 14, 2019
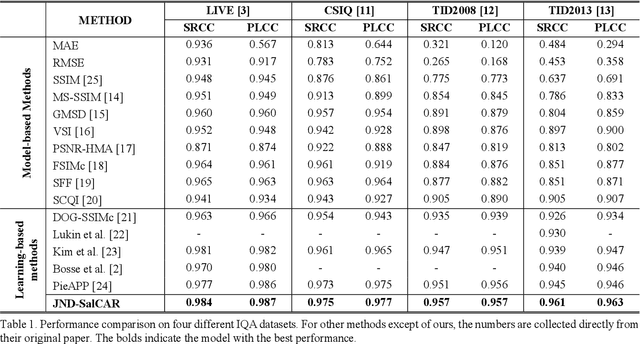
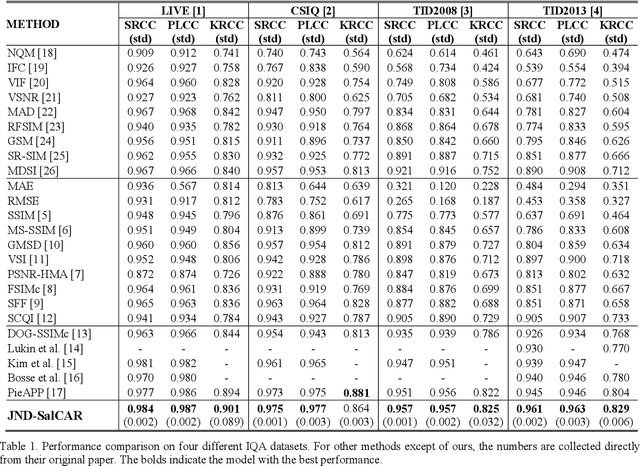
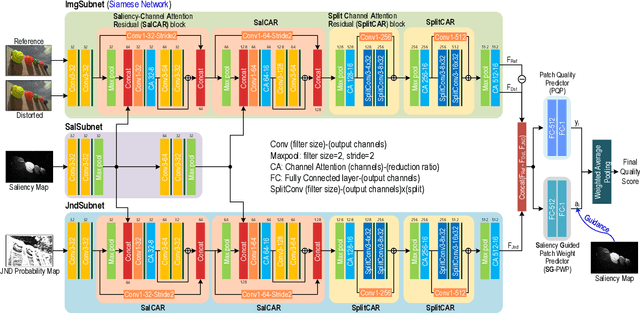
In image quality enhancement processing, it is the most important to predict how humans perceive processed images since human observers are the ultimate receivers of the images. Thus, objective image quality assessment (IQA) methods based on human visual sensitivity from psychophysical experiments have been extensively studied. Thanks to the powerfulness of deep convolutional neural networks (CNN), many CNN based IQA models have been studied. However, previous CNN-based IQA models have not fully utilized the characteristics of human visual systems (HVS) for IQA problems by simply entrusting everything to CNN where the CNN-based models are often trained as a regressor to predict the scores of subjective quality assessment obtained from IQA datasets. In this paper, we propose a novel HVS-inspired deep IQA network, called Deep HVS-IQA Net, where the human psychophysical characteristics such as visual saliency and just noticeable difference (JND) are incorporated at the front-end of the Deep HVS-IQA Net. To our best knowledge, our work is the first HVS-inspired trainable IQA network that considers both the visual saliency and JND characteristics of HVS. Furthermore, we propose a rank loss to train our Deep HVS-IQA Net effectively so that perceptually important features can be extracted for image quality prediction. The rank loss can penalize the Deep HVS-IQA Net when the order of its predicted quality scores is different from that of the ground truth scores. We evaluate the proposed Deep HVS-IQA Net on large IQA datasets where it outperforms all the recent state-of-the-art IQA methods.