 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Image Super-Resolution Networks with Pixel-Level Classification
Jul 31, 2024In recent times, the need for effective super-resolution (SR) techniques has surged, especially for large-scale images ranging 2K to 8K resolutions. For DNN-based SISR, decomposing images into overlapping patches is typically necessary due to computational constraints. In such patch-decomposing scheme, one can allocate computational resources differently based on each patch's difficulty to further improve efficiency while maintaining SR performance. However, this approach has a limitation: computational resources is uniformly allocated within a patch, leading to lower efficiency when the patch contain pixels with varying levels of restoration difficulty. To address the issue, we propose the Pixel-level Classifier for Single Image Super-Resolution (PCSR), a novel method designed to distribute computational resources adaptively at the pixel level. A PCSR model comprises a backbone, a pixel-level classifier, and a set of pixel-level upsamplers with varying capacities. The pixel-level classifier assigns each pixel to an appropriate upsampler based on its restoration difficulty, thereby optimizing computational resource usage. Our method allows for performance and computational cost balance during inference without re-training. Our experiments demonstrate PCSR's advantage over existing patch-distributing methods in PSNR-FLOP trade-offs across different backbone models and benchmarks. The code is available at https://github.com/3587jjh/PCSR.
CLIP-Guided Attribute Aware Pretraining for Generalizable Image Quality Assessment
Jun 03, 2024In no-reference image quality assessment (NR-IQA), the challenge of limited dataset sizes hampers the development of robust and generalizable models. Conventional methods address this issue by utilizing large datasets to extract rich representations for IQA. Also, some approaches propose vision language models (VLM) based IQA, but the domain gap between generic VLM and IQA constrains their scalability. In this work, we propose a novel pretraining framework that constructs a generalizable representation for IQA by selectively extracting quality-related knowledge from VLM and leveraging the scalability of large datasets. Specifically, we carefully select optimal text prompts for five representative image quality attributes and use VLM to generate pseudo-labels. Numerous attribute-aware pseudo-labels can be generated with large image datasets, allowing our IQA model to learn rich representations about image quality. Our approach achieves state-of-the-art performance on multiple IQA datasets and exhibits remarkable generalization capabilities. Leveraging these strengths, we propose several applications, such as evaluating image generation models and training image enhancement models, demonstrating our model's real-world applicability. We will make the code available for access.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
NTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
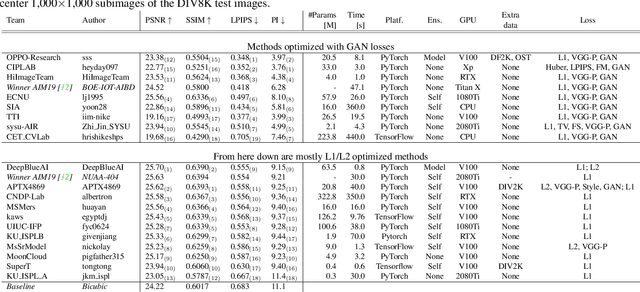

This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.
Deep Space-Time Video Upsampling Networks
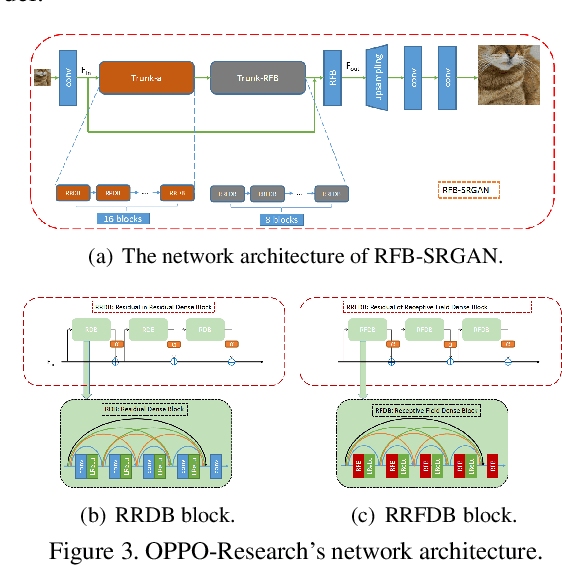
Apr 06, 2020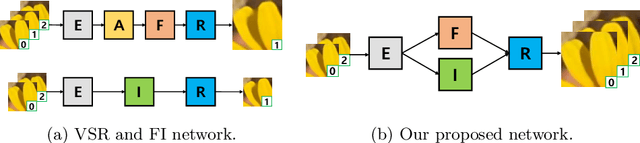


Video super-resolution (VSR) and frame interpolation (FI) are traditional computer vision problems, and the performance have been improving by incorporating deep learning recently. In this paper, we investigate the problem of jointly upsampling videos both in space and time, which is becoming more important with advances in display systems. One solution for this is to run VSR and FI, one by one, independently. This is highly inefficient as heavy deep neural networks (DNN) are involved in each solution. To this end, we propose an end-to-end DNN framework for the space-time video upsampling by efficiently merging VSR and FI into a joint framework. In our framework, a novel weighting scheme is proposed to fuse input frames effectively without explicit motion compensation for efficient processing of videos. The results show better results both quantitatively and qualitatively, while reducing the computation time (x7 faster) and the number of parameters (30%) compared to baselines.
Learning the Loss Functions in a Discriminative Space for Video Restoration
Mar 20, 2020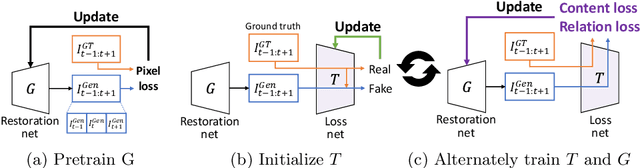
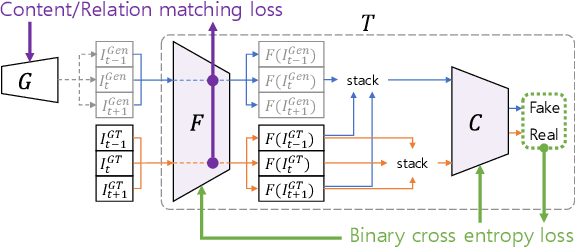

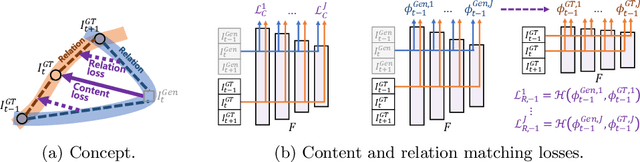
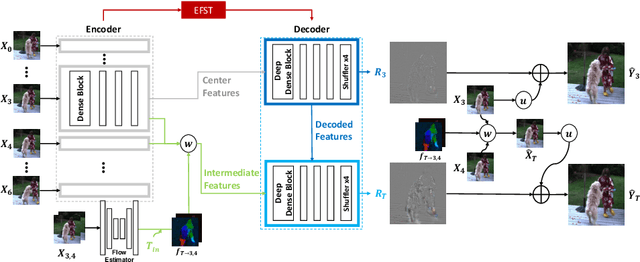
With more advanced deep network architectures and learning schemes such as GANs, the performance of video restoration algorithms has greatly improved recently. Meanwhile, the loss functions for optimizing deep neural networks remain relatively unchanged. To this end, we propose a new framework for building effective loss functions by learning a discriminative space specific to a video restoration task. Our framework is similar to GANs in that we iteratively train two networks - a generator and a loss network. The generator learns to restore videos in a supervised fashion, by following ground truth features through the feature matching in the discriminative space learned by the loss network. In addition, we also introduce a new relation loss in order to maintain the temporal consistency in output videos. Experiments on video superresolution and deblurring show that our method generates visually more pleasing videos with better quantitative perceptual metric values than the other state-of-the-art methods.