 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError Compensation Framework for Flow-Guided Video Inpainting
Jul 21, 2022
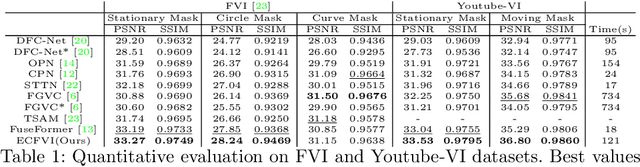


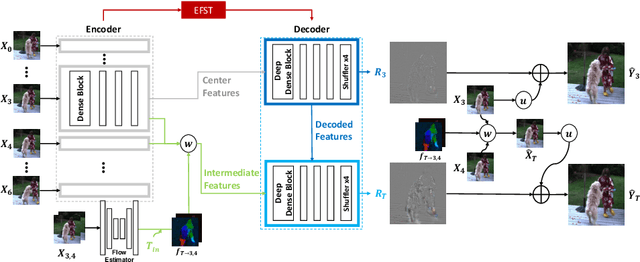
The key to video inpainting is to use correlation information from as many reference frames as possible. Existing flow-based propagation methods split the video synthesis process into multiple steps: flow completion -> pixel propagation -> synthesis. However, there is a significant drawback that the errors in each step continue to accumulate and amplify in the next step. To this end, we propose an Error Compensation Framework for Flow-guided Video Inpainting (ECFVI), which takes advantage of the flow-based method and offsets its weaknesses. We address the weakness with the newly designed flow completion module and the error compensation network that exploits the error guidance map. Our approach greatly improves the temporal consistency and the visual quality of the completed videos. Experimental results show the superior performance of our proposed method with the speed up of x6, compared to the state-of-the-art methods. In addition, we present a new benchmark dataset for evaluation by supplementing the weaknesses of existing test datasets.
Deep Space-Time Video Upsampling Networks
Apr 06, 2020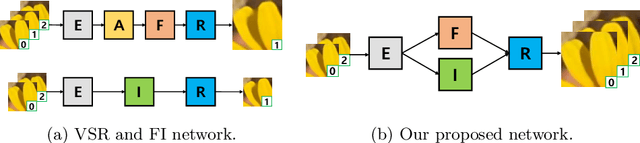


Video super-resolution (VSR) and frame interpolation (FI) are traditional computer vision problems, and the performance have been improving by incorporating deep learning recently. In this paper, we investigate the problem of jointly upsampling videos both in space and time, which is becoming more important with advances in display systems. One solution for this is to run VSR and FI, one by one, independently. This is highly inefficient as heavy deep neural networks (DNN) are involved in each solution. To this end, we propose an end-to-end DNN framework for the space-time video upsampling by efficiently merging VSR and FI into a joint framework. In our framework, a novel weighting scheme is proposed to fuse input frames effectively without explicit motion compensation for efficient processing of videos. The results show better results both quantitatively and qualitatively, while reducing the computation time (x7 faster) and the number of parameters (30%) compared to baselines.
Learning the Loss Functions in a Discriminative Space for Video Restoration
Mar 20, 2020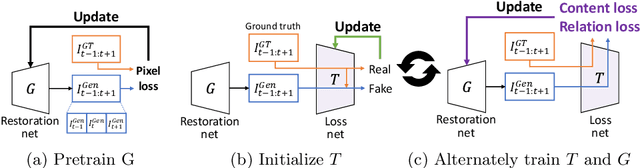
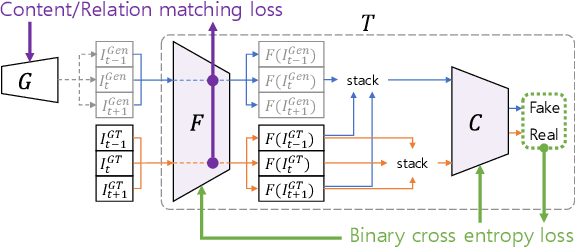

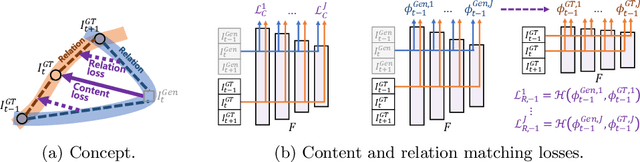
With more advanced deep network architectures and learning schemes such as GANs, the performance of video restoration algorithms has greatly improved recently. Meanwhile, the loss functions for optimizing deep neural networks remain relatively unchanged. To this end, we propose a new framework for building effective loss functions by learning a discriminative space specific to a video restoration task. Our framework is similar to GANs in that we iteratively train two networks - a generator and a loss network. The generator learns to restore videos in a supervised fashion, by following ground truth features through the feature matching in the discriminative space learned by the loss network. In addition, we also introduce a new relation loss in order to maintain the temporal consistency in output videos. Experiments on video superresolution and deblurring show that our method generates visually more pleasing videos with better quantitative perceptual metric values than the other state-of-the-art methods.