 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaVR: Scene Latent Conditioned Generative Video Trajectory Re-Rendering using Large 4D Reconstruction Models
Jan 21, 2026Given a monocular video, the goal of video re-rendering is to generate views of the scene from a novel camera trajectory. Existing methods face two distinct challenges. Geometrically unconditioned models lack spatial awareness, leading to drift and deformation under viewpoint changes. On the other hand, geometrically-conditioned models depend on estimated depth and explicit reconstruction, making them susceptible to depth inaccuracies and calibration errors. We propose to address these challenges by using the implicit geometric knowledge embedded in the latent space of a large 4D reconstruction model to condition the video generation process. These latents capture scene structure in a continuous space without explicit reconstruction. Therefore, they provide a flexible representation that allows the pretrained diffusion prior to regularize errors more effectively. By jointly conditioning on these latents and source camera poses, we demonstrate that our model achieves state-of-the-art results on the video re-rendering task. Project webpage is https://lavr-4d-scene-rerender.github.io/
EgoQR: Efficient QR Code Reading in Egocentric Settings
Oct 07, 2024



QR codes have become ubiquitous in daily life, enabling rapid information exchange. With the increasing adoption of smart wearable devices, there is a need for efficient, and friction-less QR code reading capabilities from Egocentric point-of-views. However, adapting existing phone-based QR code readers to egocentric images poses significant challenges. Code reading from egocentric images bring unique challenges such as wide field-of-view, code distortion and lack of visual feedback as compared to phones where users can adjust the position and framing. Furthermore, wearable devices impose constraints on resources like compute, power and memory. To address these challenges, we present EgoQR, a novel system for reading QR codes from egocentric images, and is well suited for deployment on wearable devices. Our approach consists of two primary components: detection and decoding, designed to operate on high-resolution images on the device with minimal power consumption and added latency. The detection component efficiently locates potential QR codes within the image, while our enhanced decoding component extracts and interprets the encoded information. We incorporate innovative techniques to handle the specific challenges of egocentric imagery, such as varying perspectives, wider field of view, and motion blur. We evaluate our approach on a dataset of egocentric images, demonstrating 34% improvement in reading the code compared to an existing state of the art QR code readers.
Geometry Transfer for Stylizing Radiance Fields
Feb 02, 2024Shape and geometric patterns are essential in defining stylistic identity. However, current 3D style transfer methods predominantly focus on transferring colors and textures, often overlooking geometric aspects. In this paper, we introduce Geometry Transfer, a novel method that leverages geometric deformation for 3D style transfer. This technique employs depth maps to extract a style guide, subsequently applied to stylize the geometry of radiance fields. Moreover, we propose new techniques that utilize geometric cues from the 3D scene, thereby enhancing aesthetic expressiveness and more accurately reflecting intended styles. Our extensive experiments show that Geometry Transfer enables a broader and more expressive range of stylizations, thereby significantly expanding the scope of 3D style transfer.
Learning Neural Duplex Radiance Fields for Real-Time View Synthesis
Apr 20, 2023



Neural radiance fields (NeRFs) enable novel view synthesis with unprecedented visual quality. However, to render photorealistic images, NeRFs require hundreds of deep multilayer perceptron (MLP) evaluations - for each pixel. This is prohibitively expensive and makes real-time rendering infeasible, even on powerful modern GPUs. In this paper, we propose a novel approach to distill and bake NeRFs into highly efficient mesh-based neural representations that are fully compatible with the massively parallel graphics rendering pipeline. We represent scenes as neural radiance features encoded on a two-layer duplex mesh, which effectively overcomes the inherent inaccuracies in 3D surface reconstruction by learning the aggregated radiance information from a reliable interval of ray-surface intersections. To exploit local geometric relationships of nearby pixels, we leverage screen-space convolutions instead of the MLPs used in NeRFs to achieve high-quality appearance. Finally, the performance of the whole framework is further boosted by a novel multi-view distillation optimization strategy. We demonstrate the effectiveness and superiority of our approach via extensive experiments on a range of standard datasets.
FSID: Fully Synthetic Image Denoising via Procedural Scene Generation
Dec 07, 2022



For low-level computer vision and image processing ML tasks, training on large datasets is critical for generalization. However, the standard practice of relying on real-world images primarily from the Internet comes with image quality, scalability, and privacy issues, especially in commercial contexts. To address this, we have developed a procedural synthetic data generation pipeline and dataset tailored to low-level vision tasks. Our Unreal engine-based synthetic data pipeline populates large scenes algorithmically with a combination of random 3D objects, materials, and geometric transformations. Then, we calibrate the camera noise profiles to synthesize the noisy images. From this pipeline, we generated a fully synthetic image denoising dataset (FSID) which consists of 175,000 noisy/clean image pairs. We then trained and validated a CNN-based denoising model, and demonstrated that the model trained on this synthetic data alone can achieve competitive denoising results when evaluated on real-world noisy images captured with smartphone cameras.
Learning sRGB-to-Raw-RGB De-rendering with Content-Aware Metadata
Jun 03, 2022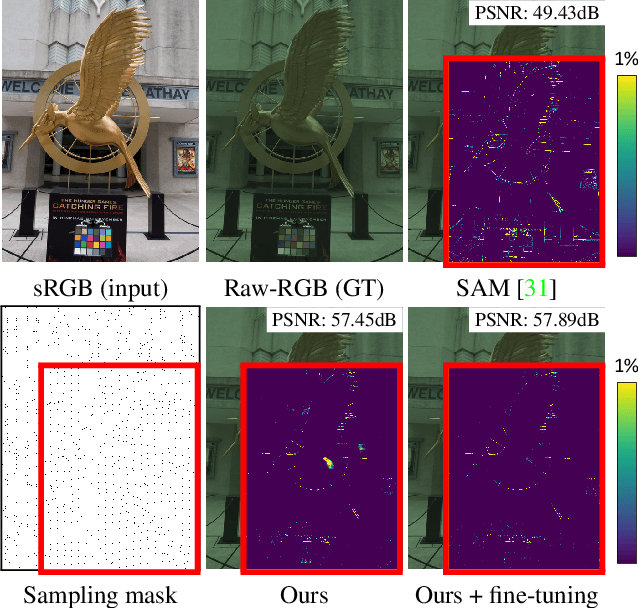

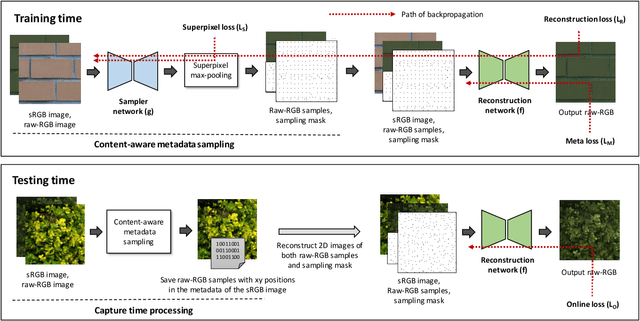
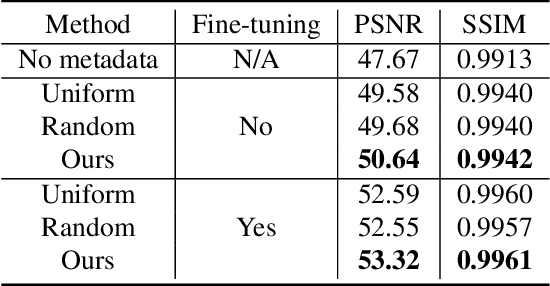
Most camera images are rendered and saved in the standard RGB (sRGB) format by the camera's hardware. Due to the in-camera photo-finishing routines, nonlinear sRGB images are undesirable for computer vision tasks that assume a direct relationship between pixel values and scene radiance. For such applications, linear raw-RGB sensor images are preferred. Saving images in their raw-RGB format is still uncommon due to the large storage requirement and lack of support by many imaging applications. Several "raw reconstruction" methods have been proposed that utilize specialized metadata sampled from the raw-RGB image at capture time and embedded in the sRGB image. This metadata is used to parameterize a mapping function to de-render the sRGB image back to its original raw-RGB format when needed. Existing raw reconstruction methods rely on simple sampling strategies and global mapping to perform the de-rendering. This paper shows how to improve the de-rendering results by jointly learning sampling and reconstruction. Our experiments show that our learned sampling can adapt to the image content to produce better raw reconstructions than existing methods. We also describe an online fine-tuning strategy for the reconstruction network to improve results further.
Neural Image Representations for Multi-Image Fusion and Layer Separation
Aug 24, 2021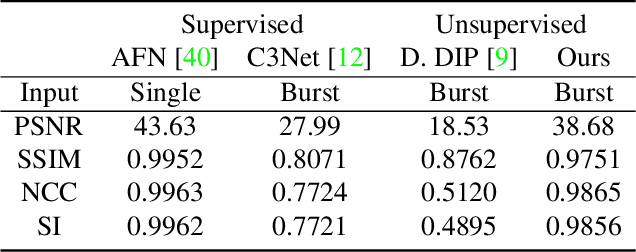
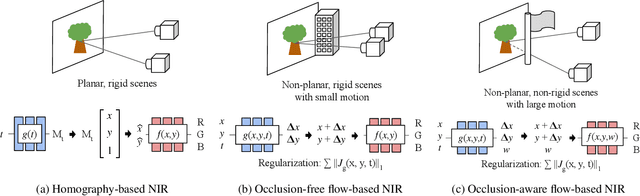
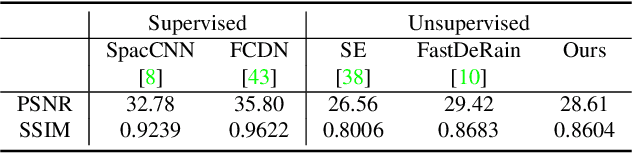
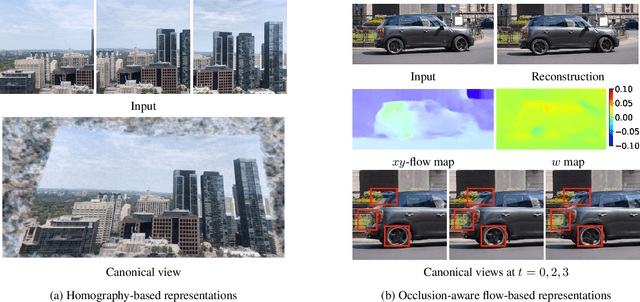
We propose a framework for aligning and fusing multiple images into a single coordinate-based neural representations. Our framework targets burst images that have misalignment due to camera ego motion and small changes in the scene. We describe different strategies for alignment depending on the assumption of the scene motion, namely, perspective planar (i.e., homography), optical flow with minimal scene change, and optical flow with notable occlusion and disocclusion. Our framework effectively combines the multiple inputs into a single neural implicit function without the need for selecting one of the images as a reference frame. We demonstrate how to use this multi-frame fusion framework for various layer separation tasks.
Temporally smooth online action detection using cycle-consistent future anticipation
Apr 16, 2021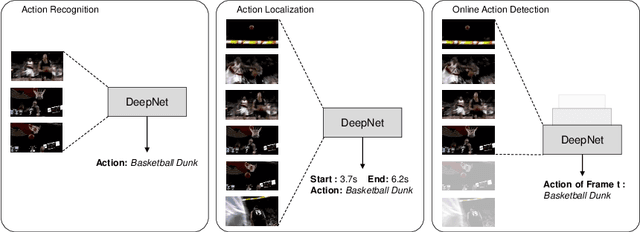
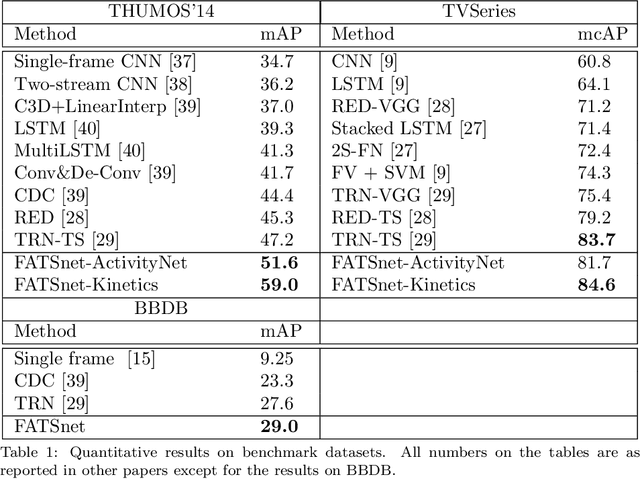
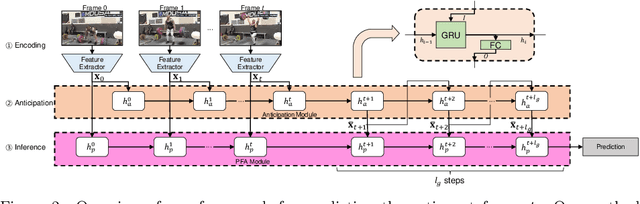

Many video understanding tasks work in the offline setting by assuming that the input video is given from the start to the end. However, many real-world problems require the online setting, making a decision immediately using only the current and the past frames of videos such as in autonomous driving and surveillance systems. In this paper, we present a novel solution for online action detection by using a simple yet effective RNN-based networks called the Future Anticipation and Temporally Smoothing network (FATSnet). The proposed network consists of a module for anticipating the future that can be trained in an unsupervised manner with the cycle-consistency loss, and another component for aggregating the past and the future for temporally smooth frame-by-frame predictions. We also propose a solution to relieve the performance loss when running RNN-based models on very long sequences. Evaluations on TVSeries, THUMOS14, and BBDB show that our method achieve the state-of-the-art performances compared to the previous works on online action detection.
* Accepted by Pattern Recognition
Cross-Identity Motion Transfer for Arbitrary Objects through Pose-Attentive Video Reassembling
Jul 17, 2020
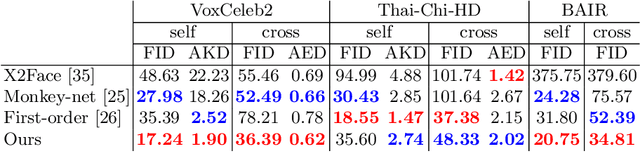
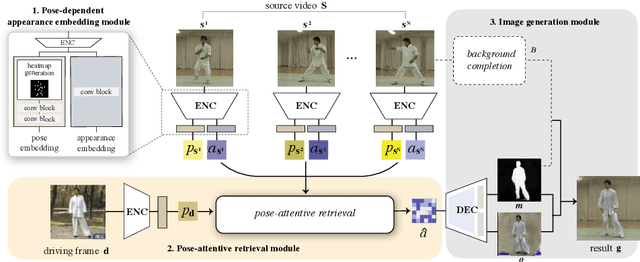
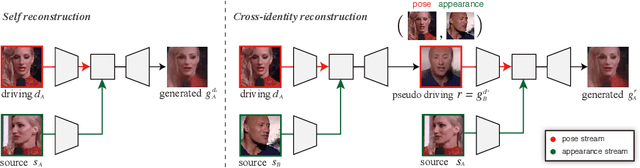
We propose an attention-based networks for transferring motions between arbitrary objects. Given a source image(s) and a driving video, our networks animate the subject in the source images according to the motion in the driving video. In our attention mechanism, dense similarities between the learned keypoints in the source and the driving images are computed in order to retrieve the appearance information from the source images. Taking a different approach from the well-studied warping based models, our attention-based model has several advantages. By reassembling non-locally searched pieces from the source contents, our approach can produce more realistic outputs. Furthermore, our system can make use of multiple observations of the source appearance (e.g. front and sides of faces) to make the results more accurate. To reduce the training-testing discrepancy of the self-supervised learning, a novel cross-identity training scheme is additionally introduced. With the training scheme, our networks is trained to transfer motions between different subjects, as in the real testing scenario. Experimental results validate that our method produces visually pleasing results in various object domains, showing better performances compared to previous works.
Learning the Loss Functions in a Discriminative Space for Video Restoration
Mar 20, 2020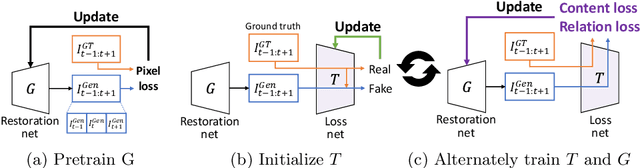
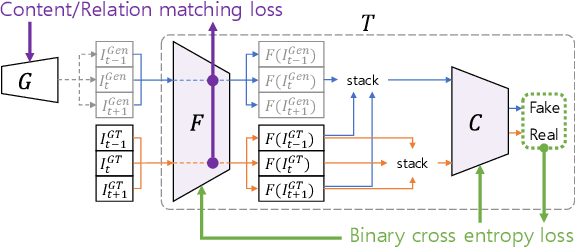

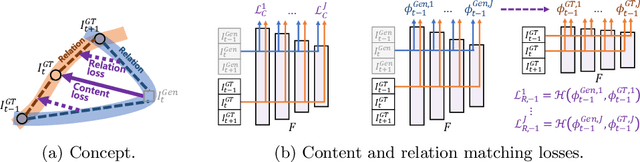
With more advanced deep network architectures and learning schemes such as GANs, the performance of video restoration algorithms has greatly improved recently. Meanwhile, the loss functions for optimizing deep neural networks remain relatively unchanged. To this end, we propose a new framework for building effective loss functions by learning a discriminative space specific to a video restoration task. Our framework is similar to GANs in that we iteratively train two networks - a generator and a loss network. The generator learns to restore videos in a supervised fashion, by following ground truth features through the feature matching in the discriminative space learned by the loss network. In addition, we also introduce a new relation loss in order to maintain the temporal consistency in output videos. Experiments on video superresolution and deblurring show that our method generates visually more pleasing videos with better quantitative perceptual metric values than the other state-of-the-art methods.