 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporally smooth online action detection using cycle-consistent future anticipation
Apr 16, 2021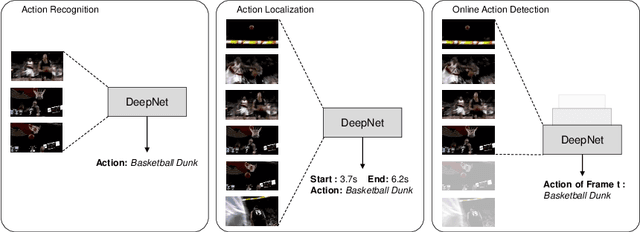
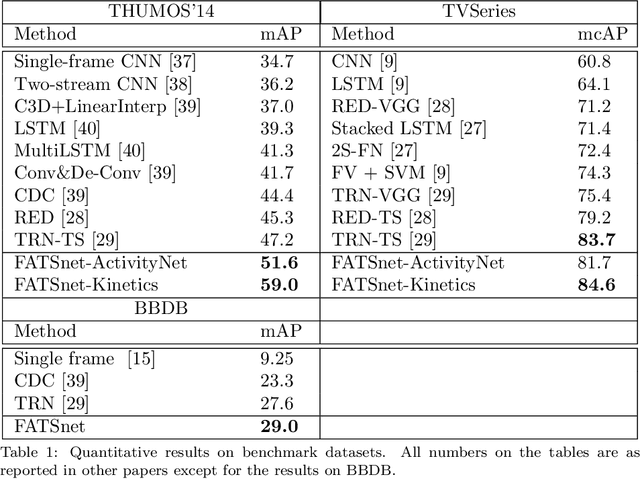
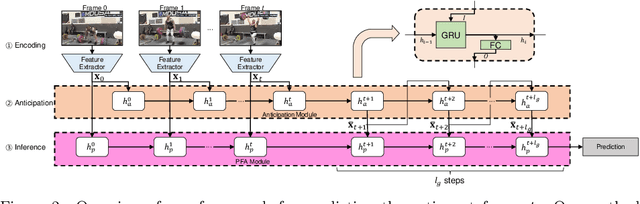

Many video understanding tasks work in the offline setting by assuming that the input video is given from the start to the end. However, many real-world problems require the online setting, making a decision immediately using only the current and the past frames of videos such as in autonomous driving and surveillance systems. In this paper, we present a novel solution for online action detection by using a simple yet effective RNN-based networks called the Future Anticipation and Temporally Smoothing network (FATSnet). The proposed network consists of a module for anticipating the future that can be trained in an unsupervised manner with the cycle-consistency loss, and another component for aggregating the past and the future for temporally smooth frame-by-frame predictions. We also propose a solution to relieve the performance loss when running RNN-based models on very long sequences. Evaluations on TVSeries, THUMOS14, and BBDB show that our method achieve the state-of-the-art performances compared to the previous works on online action detection.
* Accepted by Pattern Recognition