 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Image Authenticity When Cameras Use Generative AI
Apr 23, 2026The ability of generative AI (GenAI) methods to photorealistically alter camera images has raised awareness about the authenticity of images shared online. Interestingly, images captured directly by our cameras are considered authentic and faithful. However, with the increasing integration of deep-learning modules into cameras' capture-time hardware -- namely, the image signal processor (ISP) -- there is now a potential for hallucinated content in images directly output by our cameras. Hallucinated capture-time image content is typically benign, such as enhanced edges or texture, but in certain operations, such as AI-based digital zoom or low-light image enhancement, hallucinations can potentially alter the semantics and interpretation of the image content. As a result, users may not realize that the content in their camera images is not authentic. This paper addresses this issue by enabling users to recover the 'unhallucinated' version of the camera image to avoid misinterpretation of the image content. Our approach works by optimizing an image-specific multi-layer perceptron (MLP) decoder together with a modality-specific encoder so that, given the camera image, we can recover the image before hallucinated content was added. The encoder and MLP are self-contained and can be applied post-capture to the image without requiring access to the camera ISP. Moreover, the encoder and MLP decoder require only 180 KB of storage and can be readily saved as metadata within standard image formats such as JPEG and HEIC.
RawGen: Learning Camera Raw Image Generation
Mar 31, 2026Cameras capture scene-referred linear raw images, which are processed by onboard image signal processors (ISPs) into display-referred 8-bit sRGB outputs. Although raw data is more faithful for low-level vision tasks, collecting large-scale raw datasets remains a major bottleneck, as existing datasets are limited and tied to specific camera hardware. Generative models offer a promising way to address this scarcity -- however, existing diffusion frameworks are designed to synthesize photo-finished sRGB images rather than physically consistent linear representations. This paper presents RawGen, to our knowledge the first diffusion-based framework enabling text-to-raw generation for arbitrary target cameras, alongside sRGB-to-raw inversion. RawGen leverages the generative priors of large-scale sRGB diffusion models to synthesize physically meaningful linear outputs, such as CIE XYZ or camera-specific raw representations, via specialized processing in latent and pixel spaces. To handle unknown and diverse ISP pipelines and photo-finishing effects in diffusion-model training data, we build a many-to-one inverse-ISP dataset where multiple sRGB renditions of the same scene generated using diverse ISP parameters are anchored to a common scene-referred target. Fine-tuning a conditional denoiser and specialized decoder on this dataset allows RawGen to obtain camera-centric linear reconstructions that effectively invert the rendering pipeline. We demonstrate RawGen's superior performance over traditional inverse-ISP methods that assume a fixed ISP. Furthermore, we show that augmenting training pipelines with RawGen's scalable, text-driven synthetic data can benefit downstream low-level vision tasks.
Improved Mapping Between Illuminations and Sensors for RAW Images
Aug 20, 2025RAW images are unprocessed camera sensor output with sensor-specific RGB values based on the sensor's color filter spectral sensitivities. RAW images also incur strong color casts due to the sensor's response to the spectral properties of scene illumination. The sensor- and illumination-specific nature of RAW images makes it challenging to capture RAW datasets for deep learning methods, as scenes need to be captured for each sensor and under a wide range of illumination. Methods for illumination augmentation for a given sensor and the ability to map RAW images between sensors are important for reducing the burden of data capture. To explore this problem, we introduce the first-of-its-kind dataset comprising carefully captured scenes under a wide range of illumination. Specifically, we use a customized lightbox with tunable illumination spectra to capture several scenes with different cameras. Our illumination and sensor mapping dataset has 390 illuminations, four cameras, and 18 scenes. Using this dataset, we introduce a lightweight neural network approach for illumination and sensor mapping that outperforms competing methods. We demonstrate the utility of our approach on the downstream task of training a neural ISP. Link to project page: https://github.com/SamsungLabs/illum-sensor-mapping.
Examining Joint Demosaicing and Denoising for Single-, Quad-, and Nona-Bayer Patterns
Apr 08, 2025Camera sensors have color filters arranged in a mosaic layout, traditionally following the Bayer pattern. Demosaicing is a critical step camera hardware applies to obtain a full-channel RGB image. Many smartphones now have multiple sensors with different patterns, such as Quad-Bayer or Nona-Bayer. Most modern deep network-based models perform joint demosaicing and denoising with the current strategy of training a separate network per pattern. Relying on individual models per pattern requires additional memory overhead and makes it challenging to switch quickly between cameras. In this work, we are interested in analyzing strategies for joint demosaicing and denoising for the three main mosaic layouts (1x1 Single-Bayer, 2x2 Quad-Bayer, and 3x3 Nona-Bayer). We found that concatenating a three-channel mosaic embedding to the input image and training with a unified demosaicing architecture yields results that outperform existing Quad-Bayer and Nona-Bayer models and are comparable to Single-Bayer models. Additionally, we describe a maskout strategy that enhances the model performance and facilitates dead pixel correction -- a step often overlooked by existing AI-based demosaicing models. As part of this effort, we captured a new demosaicing dataset of 638 RAW images that contain challenging scenes with patches annotated for training, validation, and testing.
Time-Aware Auto White Balance in Mobile Photography
Apr 08, 2025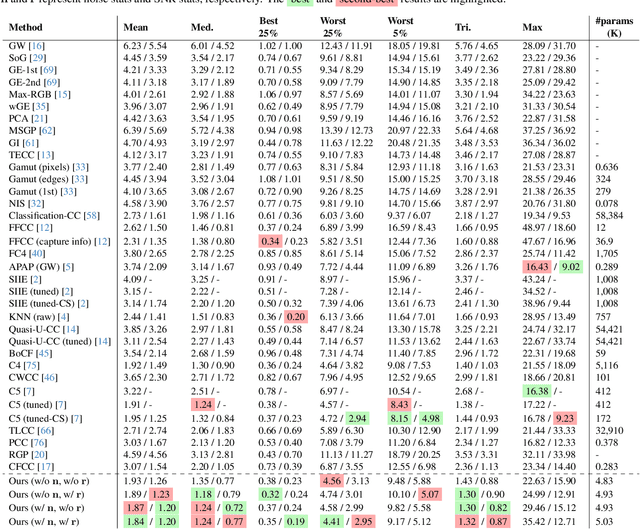
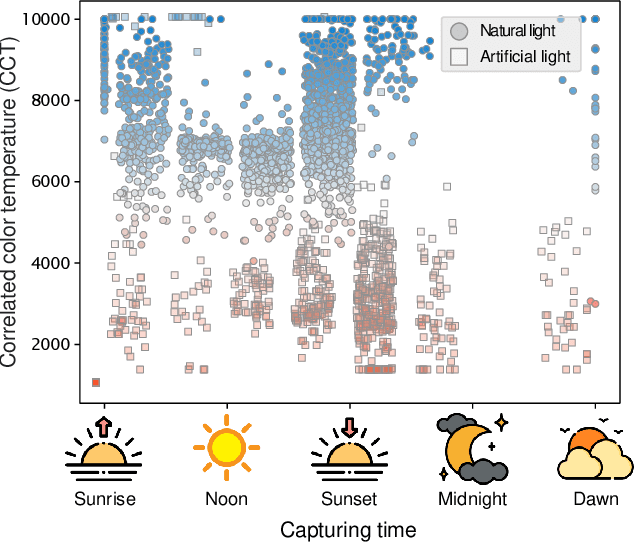
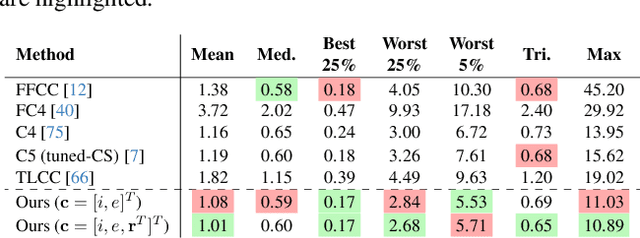
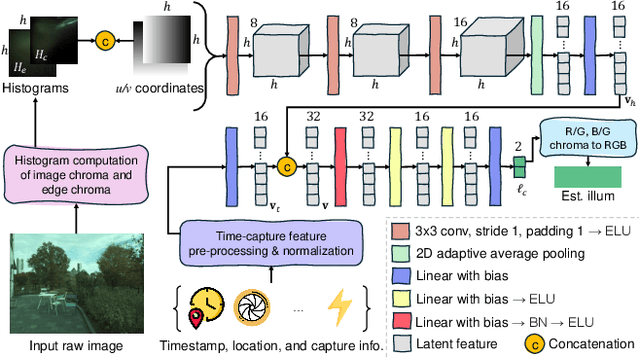
Cameras rely on auto white balance (AWB) to correct undesirable color casts caused by scene illumination and the camera's spectral sensitivity. This is typically achieved using an illuminant estimator that determines the global color cast solely from the color information in the camera's raw sensor image. Mobile devices provide valuable additional metadata-such as capture timestamp and geolocation-that offers strong contextual clues to help narrow down the possible illumination solutions. This paper proposes a lightweight illuminant estimation method that incorporates such contextual metadata, along with additional capture information and image colors, into a compact model (~5K parameters), achieving promising results, matching or surpassing larger models. To validate our method, we introduce a dataset of 3,224 smartphone images with contextual metadata collected at various times of day and under diverse lighting conditions. The dataset includes ground-truth illuminant colors, determined using a color chart, and user-preferred illuminants validated through a user study, providing a comprehensive benchmark for AWB evaluation.
Day-to-Night Image Synthesis for Training Nighttime Neural ISPs
Jun 06, 2022

Many flagship smartphone cameras now use a dedicated neural image signal processor (ISP) to render noisy raw sensor images to the final processed output. Training nightmode ISP networks relies on large-scale datasets of image pairs with: (1) a noisy raw image captured with a short exposure and a high ISO gain; and (2) a ground truth low-noise raw image captured with a long exposure and low ISO that has been rendered through the ISP. Capturing such image pairs is tedious and time-consuming, requiring careful setup to ensure alignment between the image pairs. In addition, ground truth images are often prone to motion blur due to the long exposure. To address this problem, we propose a method that synthesizes nighttime images from daytime images. Daytime images are easy to capture, exhibit low-noise (even on smartphone cameras) and rarely suffer from motion blur. We outline a processing framework to convert daytime raw images to have the appearance of realistic nighttime raw images with different levels of noise. Our procedure allows us to easily produce aligned noisy and clean nighttime image pairs. We show the effectiveness of our synthesis framework by training neural ISPs for nightmode rendering. Furthermore, we demonstrate that using our synthetic nighttime images together with small amounts of real data (e.g., 5% to 10%) yields performance almost on par with training exclusively on real nighttime images. Our dataset and code are available at https://github.com/SamsungLabs/day-to-night.
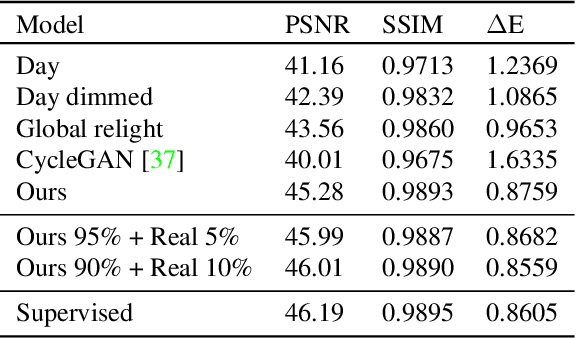
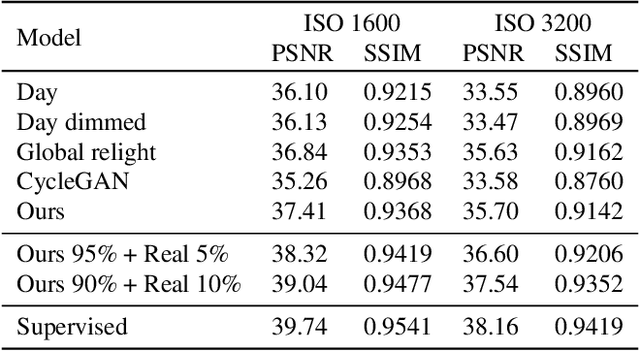
Learning sRGB-to-Raw-RGB De-rendering with Content-Aware Metadata
Jun 03, 2022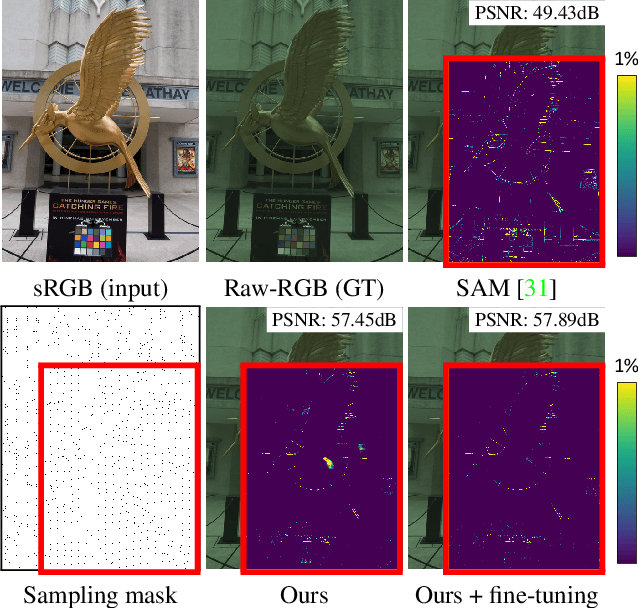

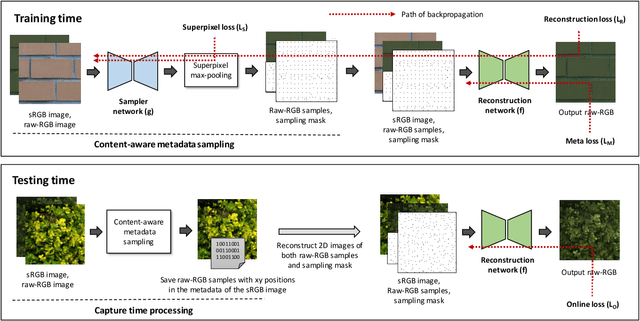
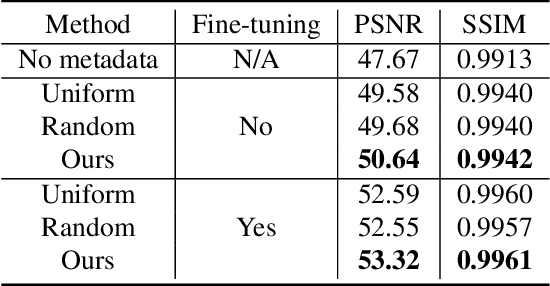
Most camera images are rendered and saved in the standard RGB (sRGB) format by the camera's hardware. Due to the in-camera photo-finishing routines, nonlinear sRGB images are undesirable for computer vision tasks that assume a direct relationship between pixel values and scene radiance. For such applications, linear raw-RGB sensor images are preferred. Saving images in their raw-RGB format is still uncommon due to the large storage requirement and lack of support by many imaging applications. Several "raw reconstruction" methods have been proposed that utilize specialized metadata sampled from the raw-RGB image at capture time and embedded in the sRGB image. This metadata is used to parameterize a mapping function to de-render the sRGB image back to its original raw-RGB format when needed. Existing raw reconstruction methods rely on simple sampling strategies and global mapping to perform the de-rendering. This paper shows how to improve the de-rendering results by jointly learning sampling and reconstruction. Our experiments show that our learned sampling can adapt to the image content to produce better raw reconstructions than existing methods. We also describe an online fine-tuning strategy for the reconstruction network to improve results further.
CIE XYZ Net: Unprocessing Images for Low-Level Computer Vision Tasks
Jun 23, 2020

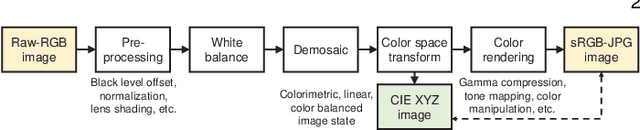

Cameras currently allow access to two image states: (i) a minimally processed linear raw-RGB image state (i.e., raw sensor data) or (ii) a highly-processed nonlinear image state (e.g., sRGB). There are many computer vision tasks that work best with a linear image state, such as image deblurring and image dehazing. Unfortunately, the vast majority of images are saved in the nonlinear image state. Because of this, a number of methods have been proposed to "unprocess" nonlinear images back to a raw-RGB state. However, existing unprocessing methods have a drawback because raw-RGB images are sensor-specific. As a result, it is necessary to know which camera produced the sRGB output and use a method or network tailored for that sensor to properly unprocess it. This paper addresses this limitation by exploiting another camera image state that is not available as an output, but it is available inside the camera pipeline. In particular, cameras apply a colorimetric conversion step to convert the raw-RGB image to a device-independent space based on the CIE XYZ color space before they apply the nonlinear photo-finishing. Leveraging this canonical image state, we propose a deep learning framework, CIE XYZ Net, that can unprocess a nonlinear image back to the canonical CIE XYZ image. This image can then be processed by any low-level computer vision operator and re-rendered back to the nonlinear image. We demonstrate the usefulness of the CIE XYZ Net on several low-level vision tasks and show significant gains that can be obtained by this processing framework. Code and dataset are publicly available at https://github.com/mahmoudnafifi/CIE_XYZ_NET.
A Little Bit More: Bitplane-Wise Bit-Depth Recovery
May 03, 2020

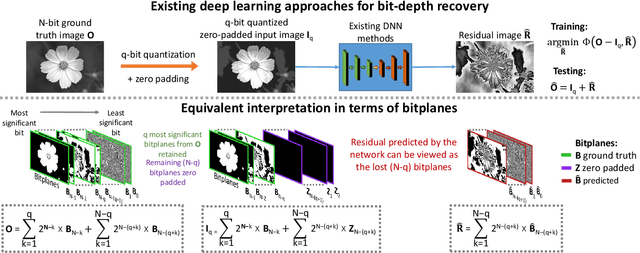
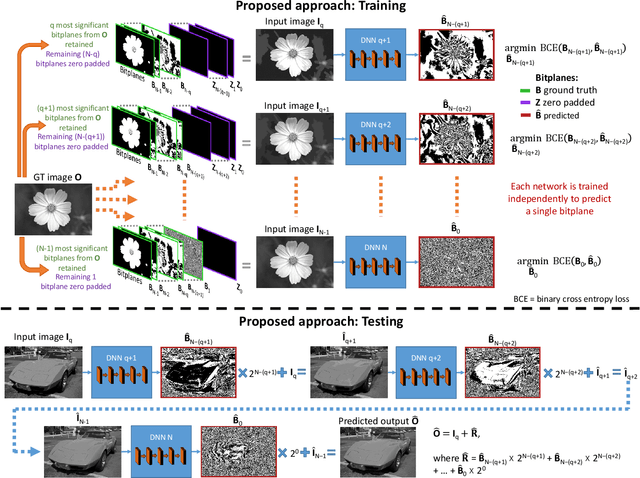
Imaging sensors digitize incoming scene light at a dynamic range of 10--12 bits (i.e., 1024--4096 tonal values). The sensor image is then processed onboard the camera and finally quantized to only 8 bits (i.e., 256 tonal values) to conform to prevailing encoding standards. There are a number of important applications, such as high-bit-depth displays and photo editing, where it is beneficial to recover the lost bit depth. Deep neural networks are effective at this bit-depth reconstruction task. Given the quantized low-bit-depth image as input, existing deep learning methods employ a single-shot approach that attempts to either (1) directly estimate the high-bit-depth image, or (2) directly estimate the residual between the high- and low-bit-depth images. In contrast, we propose a training and inference strategy that recovers the residual image bitplane-by-bitplane. Our bitplane-wise learning framework has the advantage of allowing for multiple levels of supervision during training and is able to obtain state-of-the-art results using a simple network architecture. We test our proposed method extensively on several image datasets and demonstrate an improvement from 0.5dB to 2.3dB PSNR over prior methods depending on the quantization level.