 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\text{DC}^2$: Dual-Camera Defocus Control by Learning to Refocus
Apr 06, 2023Smartphone cameras today are increasingly approaching the versatility and quality of professional cameras through a combination of hardware and software advancements. However, fixed aperture remains a key limitation, preventing users from controlling the depth of field (DoF) of captured images. At the same time, many smartphones now have multiple cameras with different fixed apertures -- specifically, an ultra-wide camera with wider field of view and deeper DoF and a higher resolution primary camera with shallower DoF. In this work, we propose $\text{DC}^2$, a system for defocus control for synthetically varying camera aperture, focus distance and arbitrary defocus effects by fusing information from such a dual-camera system. Our key insight is to leverage real-world smartphone camera dataset by using image refocus as a proxy task for learning to control defocus. Quantitative and qualitative evaluations on real-world data demonstrate our system's efficacy where we outperform state-of-the-art on defocus deblurring, bokeh rendering, and image refocus. Finally, we demonstrate creative post-capture defocus control enabled by our method, including tilt-shift and content-based defocus effects.
Day-to-Night Image Synthesis for Training Nighttime Neural ISPs
Jun 06, 2022
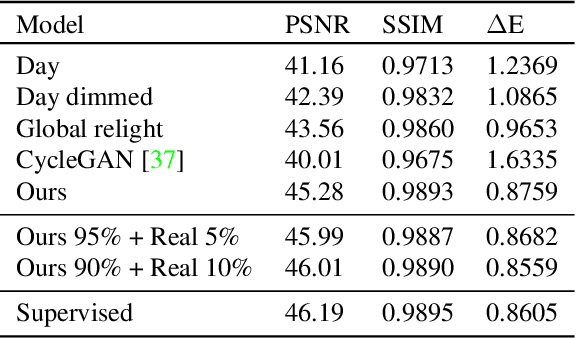

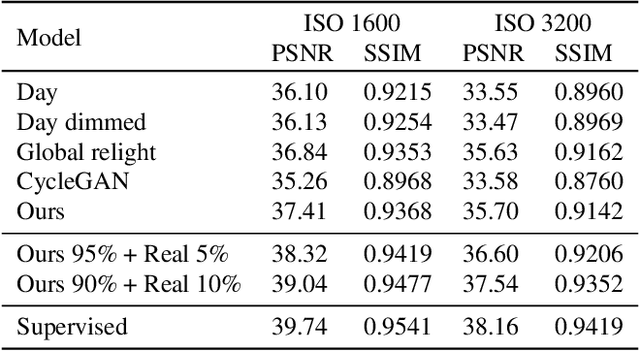
Many flagship smartphone cameras now use a dedicated neural image signal processor (ISP) to render noisy raw sensor images to the final processed output. Training nightmode ISP networks relies on large-scale datasets of image pairs with: (1) a noisy raw image captured with a short exposure and a high ISO gain; and (2) a ground truth low-noise raw image captured with a long exposure and low ISO that has been rendered through the ISP. Capturing such image pairs is tedious and time-consuming, requiring careful setup to ensure alignment between the image pairs. In addition, ground truth images are often prone to motion blur due to the long exposure. To address this problem, we propose a method that synthesizes nighttime images from daytime images. Daytime images are easy to capture, exhibit low-noise (even on smartphone cameras) and rarely suffer from motion blur. We outline a processing framework to convert daytime raw images to have the appearance of realistic nighttime raw images with different levels of noise. Our procedure allows us to easily produce aligned noisy and clean nighttime image pairs. We show the effectiveness of our synthesis framework by training neural ISPs for nightmode rendering. Furthermore, we demonstrate that using our synthetic nighttime images together with small amounts of real data (e.g., 5% to 10%) yields performance almost on par with training exclusively on real nighttime images. Our dataset and code are available at https://github.com/SamsungLabs/day-to-night.
Multi-View Motion Synthesis via Applying Rotated Dual-Pixel Blur Kernels
Nov 15, 2021
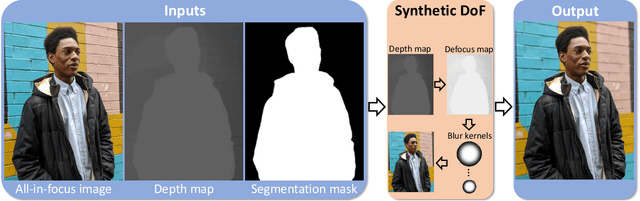
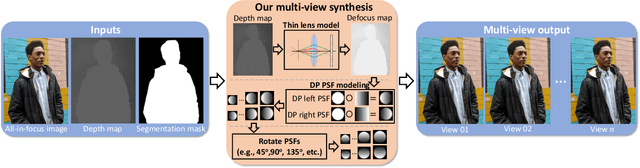
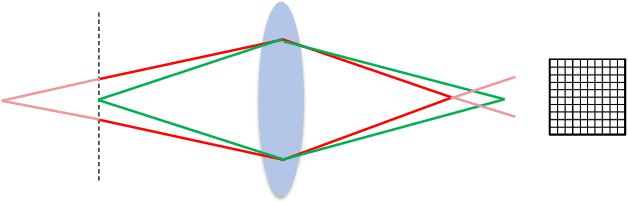
Portrait mode is widely available on smartphone cameras to provide an enhanced photographic experience. One of the primary effects applied to images captured in portrait mode is a synthetic shallow depth of field (DoF). The synthetic DoF (or bokeh effect) selectively blurs regions in the image to emulate the effect of using a large lens with a wide aperture. In addition, many applications now incorporate a new image motion attribute (NIMAT) to emulate background motion, where the motion is correlated with estimated depth at each pixel. In this work, we follow the trend of rendering the NIMAT effect by introducing a modification on the blur synthesis procedure in portrait mode. In particular, our modification enables a high-quality synthesis of multi-view bokeh from a single image by applying rotated blurring kernels. Given the synthesized multiple views, we can generate aesthetically realistic image motion similar to the NIMAT effect. We validate our approach qualitatively compared to the original NIMAT effect and other similar image motions, like Facebook 3D image. Our image motion demonstrates a smooth image view transition with fewer artifacts around the object boundary.
Improving Single-Image Defocus Deblurring: How Dual-Pixel Images Help Through Multi-Task Learning
Aug 11, 2021

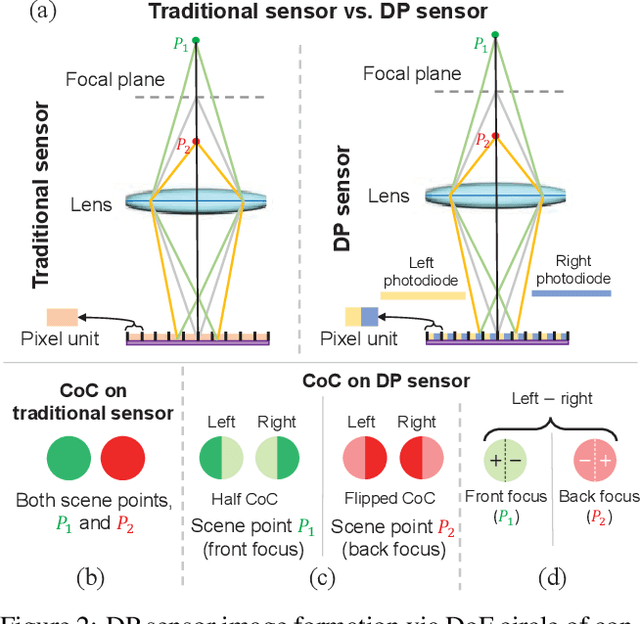
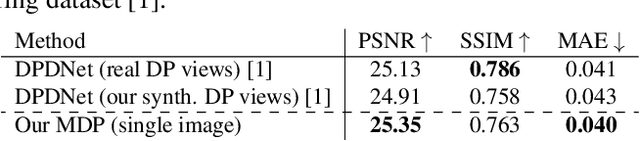
Many camera sensors use a dual-pixel (DP) design that operates as a rudimentary light field providing two sub-aperture views of a scene in a single capture. The DP sensor was developed to improve how cameras perform autofocus. Since the DP sensor's introduction, researchers have found additional uses for the DP data, such as depth estimation, reflection removal, and defocus deblurring. We are interested in the latter task of defocus deblurring. In particular, we propose a single-image deblurring network that incorporates the two sub-aperture views into a multi-task framework. Specifically, we show that jointly learning to predict the two DP views from a single blurry input image improves the network's ability to learn to deblur the image. Our experiments show this multi-task strategy achieves +1dB PSNR improvement over state-of-the-art defocus deblurring methods. In addition, our multi-task framework allows accurate DP-view synthesis (e.g., ~ 39dB PSNR) from the single input image. These high-quality DP views can be used for other DP-based applications, such as reflection removal. As part of this effort, we have captured a new dataset of 7,059 high-quality images to support our training for the DP-view synthesis task. Our dataset, code, and trained models will be made publicly available at https://github.com/Abdullah-Abuolaim/multi-task-defocus-deblurring-dual-pixel-nimat
Semi-Supervised Raw-to-Raw Mapping
Jun 29, 2021
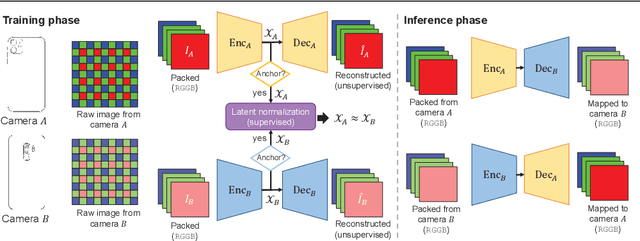


The raw-RGB colors of a camera sensor vary due to the spectral sensitivity differences across different sensor makes and models. This paper focuses on the task of mapping between different sensor raw-RGB color spaces. Prior work addressed this problem using a pairwise calibration to achieve accurate color mapping. Although being accurate, this approach is less practical as it requires: (1) capturing pair of images by both camera devices with a color calibration object placed in each new scene; (2) accurate image alignment or manual annotation of the color calibration object. This paper aims to tackle color mapping in the raw space through a more practical setup. Specifically, we present a semi-supervised raw-to-raw mapping method trained on a small set of paired images alongside an unpaired set of images captured by each camera device. Through extensive experiments, we show that our method achieves better results compared to other domain adaptation alternatives in addition to the single-calibration solution. We have generated a new dataset of raw images from two different smartphone cameras as part of this effort. Our dataset includes unpaired and paired sets for our semi-supervised training and evaluation.
CAMS: Color-Aware Multi-Style Transfer
Jun 26, 2021
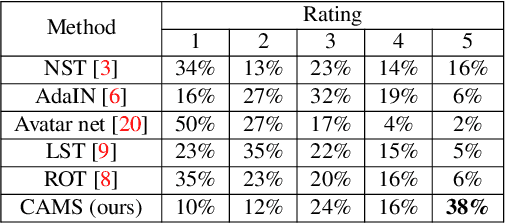

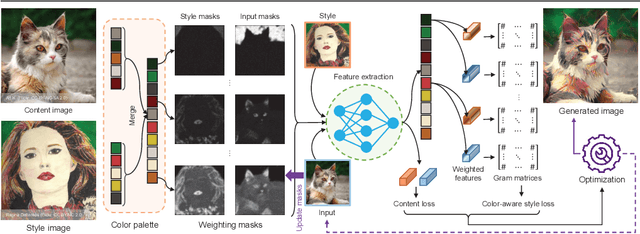
Image style transfer aims to manipulate the appearance of a source image, or "content" image, to share similar texture and colors of a target "style" image. Ideally, the style transfer manipulation should also preserve the semantic content of the source image. A commonly used approach to assist in transferring styles is based on Gram matrix optimization. One problem of Gram matrix-based optimization is that it does not consider the correlation between colors and their styles. Specifically, certain textures or structures should be associated with specific colors. This is particularly challenging when the target style image exhibits multiple style types. In this work, we propose a color-aware multi-style transfer method that generates aesthetically pleasing results while preserving the style-color correlation between style and generated images. We achieve this desired outcome by introducing a simple but efficient modification to classic Gram matrix-based style transfer optimization. A nice feature of our method is that it enables the users to manually select the color associations between the target style and content image for more transfer flexibility. We validated our method with several qualitative comparisons, including a user study conducted with 30 participants. In comparison with prior work, our method is simple, easy to implement, and achieves visually appealing results when targeting images that have multiple styles. Source code is available at https://github.com/mahmoudnafifi/color-aware-style-transfer.
Learning to Reduce Defocus Blur by Realistically Modeling Dual-Pixel Data
Dec 06, 2020
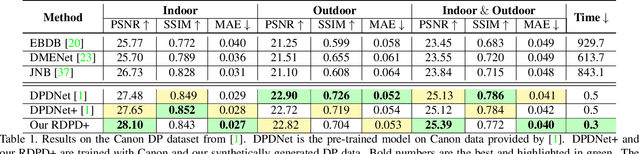
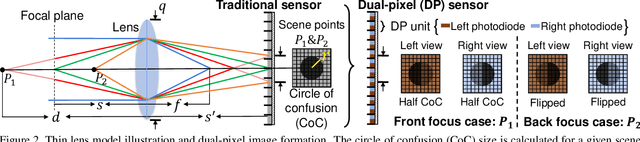
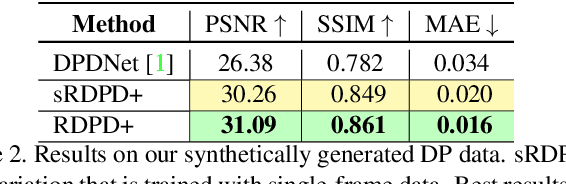
Recent work has shown impressive results on data-driven defocus deblurring using the two-image views available on modern dual-pixel (DP) sensors. One significant challenge in this line of research is access to DP data. Despite many cameras having DP sensors, only a limited number provide access to the low-level DP sensor images. In addition, capturing training data for defocus deblurring involves a time-consuming and tedious setup requiring the camera's aperture to be adjusted. Some cameras with DP sensors (e.g., smartphones) do not have adjustable apertures, further limiting the ability to produce the necessary training data. We address the data capture bottleneck by proposing a procedure to generate realistic DP data synthetically. Our synthesis approach mimics the optical image formation found on DP sensors and can be applied to virtual scenes rendered with standard computer software. Leveraging these realistic synthetic DP images, we introduce a new recurrent convolutional network (RCN) architecture that can improve deblurring results and is suitable for use with single-frame and multi-frame data captured by DP sensors. Finally, we show that our synthetic DP data is useful for training DNN models targeting video deblurring applications where access to DP data remains challenging.
CIE XYZ Net: Unprocessing Images for Low-Level Computer Vision Tasks
Jun 23, 2020

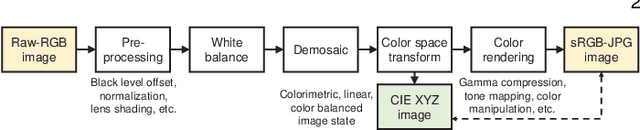

Cameras currently allow access to two image states: (i) a minimally processed linear raw-RGB image state (i.e., raw sensor data) or (ii) a highly-processed nonlinear image state (e.g., sRGB). There are many computer vision tasks that work best with a linear image state, such as image deblurring and image dehazing. Unfortunately, the vast majority of images are saved in the nonlinear image state. Because of this, a number of methods have been proposed to "unprocess" nonlinear images back to a raw-RGB state. However, existing unprocessing methods have a drawback because raw-RGB images are sensor-specific. As a result, it is necessary to know which camera produced the sRGB output and use a method or network tailored for that sensor to properly unprocess it. This paper addresses this limitation by exploiting another camera image state that is not available as an output, but it is available inside the camera pipeline. In particular, cameras apply a colorimetric conversion step to convert the raw-RGB image to a device-independent space based on the CIE XYZ color space before they apply the nonlinear photo-finishing. Leveraging this canonical image state, we propose a deep learning framework, CIE XYZ Net, that can unprocess a nonlinear image back to the canonical CIE XYZ image. This image can then be processed by any low-level computer vision operator and re-rendered back to the nonlinear image. We demonstrate the usefulness of the CIE XYZ Net on several low-level vision tasks and show significant gains that can be obtained by this processing framework. Code and dataset are publicly available at https://github.com/mahmoudnafifi/CIE_XYZ_NET.
Defocus Deblurring Using Dual-Pixel Data
May 04, 2020



Defocus blur arises in images that are captured with a shallow depth of field due to the use of a wide aperture. Correcting defocus blur is challenging because the blur is spatially varying and difficult to estimate. We propose an effective defocus deblurring method that exploits data available on dual-pixel (DP) sensors found on most modern cameras. DP sensors are used to assist a camera's auto-focus by capturing two sub-aperture views of the scene in a single image shot. The two sub-aperture images are used to calculate the appropriate lens position to focus on a particular scene region and are discarded afterwards. We introduce a deep neural network (DNN) architecture that uses these discarded sub-aperture images to reduce defocus blur. A key contribution of our effort is a carefully captured dataset of 500 scenes (2,000 images) where each scene has: (i) an image with defocus blur captured at a large aperture; (ii) the two associated DP sub-aperture views; and (iii) the corresponding all-in-focus image captured with a small aperture. Our proposed DNN produces results that are significantly better than conventional single image methods in terms of both quantitative and perceptual metrics -- all from data that is already available on the camera but ignored. The dataset, code, and trained models will be available at https://github.com/Abdullah-Abuolaim/defocus-deblurring-dual-pixel.