 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Contributions, Small Networks: Efficient Neural Network Pruning Based on Relative Importance
Oct 21, 2024
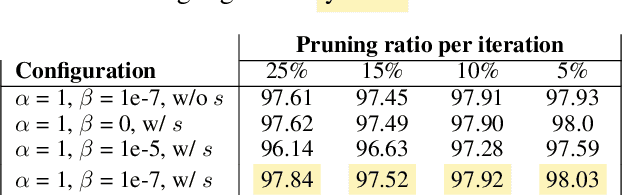

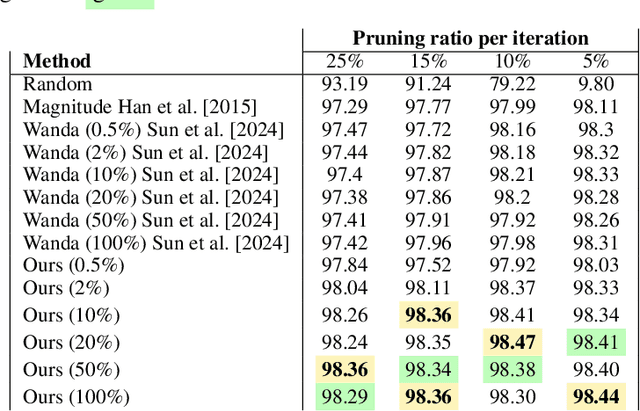
Recent advancements have scaled neural networks to unprecedented sizes, achieving remarkable performance across a wide range of tasks. However, deploying these large-scale models on resource-constrained devices poses significant challenges due to substantial storage and computational requirements. Neural network pruning has emerged as an effective technique to mitigate these limitations by reducing model size and complexity. In this paper, we introduce an intuitive and interpretable pruning method based on activation statistics, rooted in information theory and statistical analysis. Our approach leverages the statistical properties of neuron activations to identify and remove weights with minimal contributions to neuron outputs. Specifically, we build a distribution of weight contributions across the dataset and utilize its parameters to guide the pruning process. Furthermore, we propose a Pruning-aware Training strategy that incorporates an additional regularization term to enhance the effectiveness of our pruning method. Extensive experiments on multiple datasets and network architectures demonstrate that our method consistently outperforms several baseline and state-of-the-art pruning techniques.
A Learning Framework for Bandwidth-Efficient Distributed Inference in Wireless IoT
Mar 17, 2022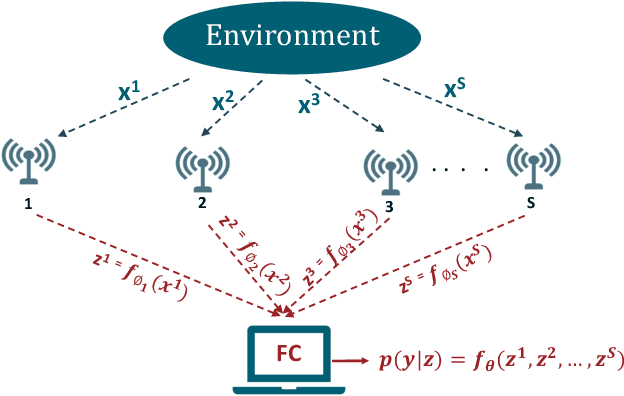
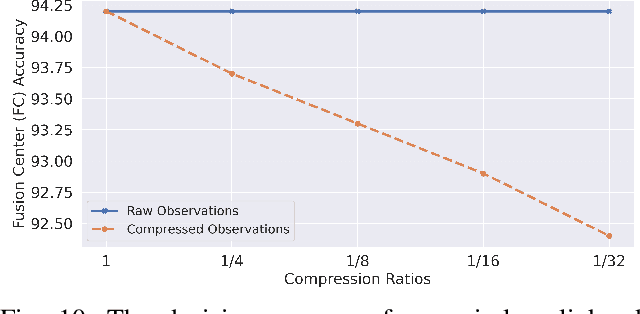
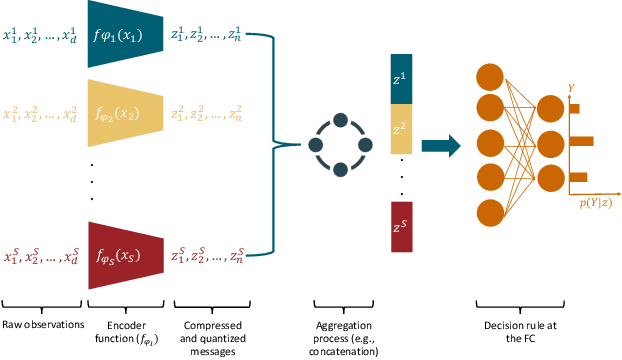

In wireless Internet of things (IoT), the sensors usually have limited bandwidth and power resources. Therefore, in a distributed setup, each sensor should compress and quantize the sensed observations before transmitting them to a fusion center (FC) where a global decision is inferred. Most of the existing compression techniques and entropy quantizers consider only the reconstruction fidelity as a metric, which means they decouple the compression from the sensing goal. In this work, we argue that data compression mechanisms and entropy quantizers should be co-designed with the sensing goal, specifically for machine-consumed data. To this end, we propose a novel deep learning-based framework for compressing and quantizing the observations of correlated sensors. Instead of maximizing the reconstruction fidelity, our objective is to compress the sensor observations in a way that maximizes the accuracy of the inferred decision (i.e., sensing goal) at the FC. Unlike prior work, we do not impose any assumptions about the observations distribution which emphasizes the wide applicability of our framework. We also propose a novel loss function that keeps the model focused on learning complementary features at each sensor. The results show the superior performance of our framework compared to other benchmark models.
CAMS: Color-Aware Multi-Style Transfer
Jun 26, 2021
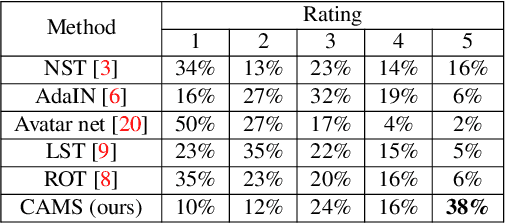

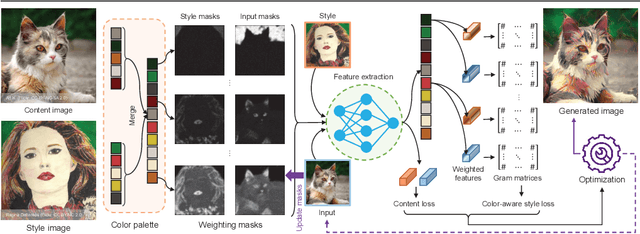
Image style transfer aims to manipulate the appearance of a source image, or "content" image, to share similar texture and colors of a target "style" image. Ideally, the style transfer manipulation should also preserve the semantic content of the source image. A commonly used approach to assist in transferring styles is based on Gram matrix optimization. One problem of Gram matrix-based optimization is that it does not consider the correlation between colors and their styles. Specifically, certain textures or structures should be associated with specific colors. This is particularly challenging when the target style image exhibits multiple style types. In this work, we propose a color-aware multi-style transfer method that generates aesthetically pleasing results while preserving the style-color correlation between style and generated images. We achieve this desired outcome by introducing a simple but efficient modification to classic Gram matrix-based style transfer optimization. A nice feature of our method is that it enables the users to manually select the color associations between the target style and content image for more transfer flexibility. We validated our method with several qualitative comparisons, including a user study conducted with 30 participants. In comparison with prior work, our method is simple, easy to implement, and achieves visually appealing results when targeting images that have multiple styles. Source code is available at https://github.com/mahmoudnafifi/color-aware-style-transfer.
PRVNet: Variational Autoencoders for Massive MIMO CSI Feedback
Nov 09, 2020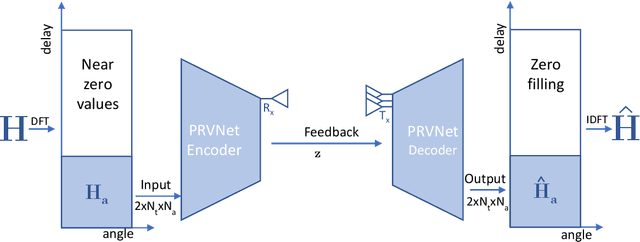
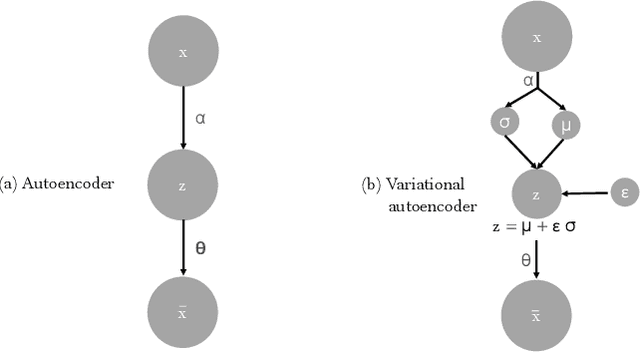
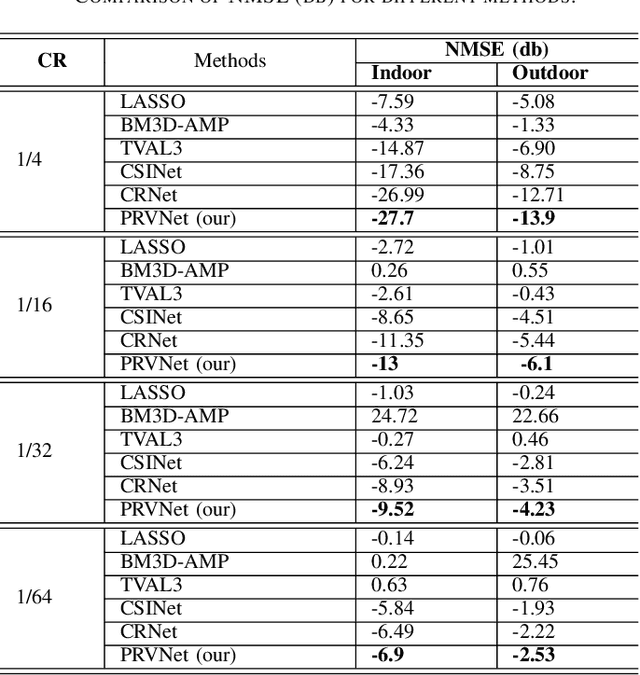

In a frequency division duplexing multiple-input multiple-output (FDD-MIMO) system, the user equipment (UE) send the downlink channel state information (CSI) to the base station for performance improvement. However, with the growing complexity of MIMO systems, this feedback becomes expensive and has a negative impact on the bandwidth. Although this problem has been largely studied in the literature, the noisy nature of the feedback channel is less considered. In this paper, we introduce PRVNet, a neural architecture based on variational autoencoders (VAE). VAE gained large attention in many fields (e.g., image processing, language models, or recommendation system). However, it received less attention in the communication domain generally and in CSI feedback problem specifically. We also introduce a different regularization parameter for the learning objective, which proved to be crucial for achieving competitive performance. In addition, we provide an efficient way to tune this parameter using KL-annealing. Empirically, we show that the proposed model significantly outperforms state-of-the-art, including two neural network approaches. The proposed model is also proved to be more robust against different levels of noise.