 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRawGen: Learning Camera Raw Image Generation
Mar 31, 2026Cameras capture scene-referred linear raw images, which are processed by onboard image signal processors (ISPs) into display-referred 8-bit sRGB outputs. Although raw data is more faithful for low-level vision tasks, collecting large-scale raw datasets remains a major bottleneck, as existing datasets are limited and tied to specific camera hardware. Generative models offer a promising way to address this scarcity -- however, existing diffusion frameworks are designed to synthesize photo-finished sRGB images rather than physically consistent linear representations. This paper presents RawGen, to our knowledge the first diffusion-based framework enabling text-to-raw generation for arbitrary target cameras, alongside sRGB-to-raw inversion. RawGen leverages the generative priors of large-scale sRGB diffusion models to synthesize physically meaningful linear outputs, such as CIE XYZ or camera-specific raw representations, via specialized processing in latent and pixel spaces. To handle unknown and diverse ISP pipelines and photo-finishing effects in diffusion-model training data, we build a many-to-one inverse-ISP dataset where multiple sRGB renditions of the same scene generated using diverse ISP parameters are anchored to a common scene-referred target. Fine-tuning a conditional denoiser and specialized decoder on this dataset allows RawGen to obtain camera-centric linear reconstructions that effectively invert the rendering pipeline. We demonstrate RawGen's superior performance over traditional inverse-ISP methods that assume a fixed ISP. Furthermore, we show that augmenting training pipelines with RawGen's scalable, text-driven synthetic data can benefit downstream low-level vision tasks.
Modular Neural Image Signal Processing
Dec 09, 2025
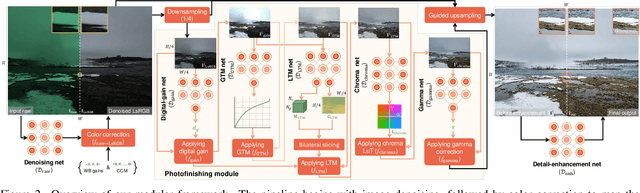
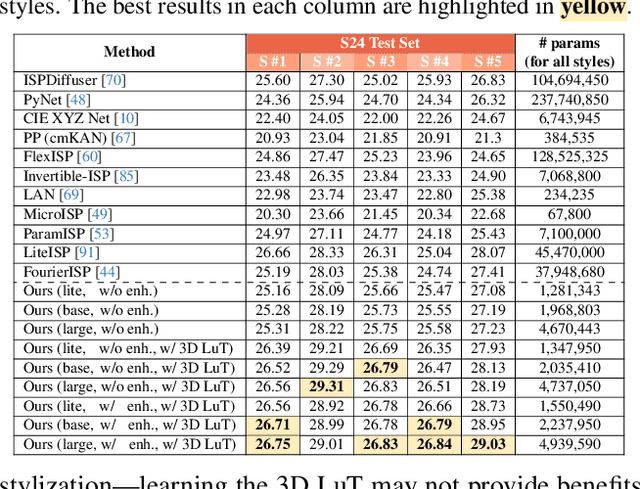
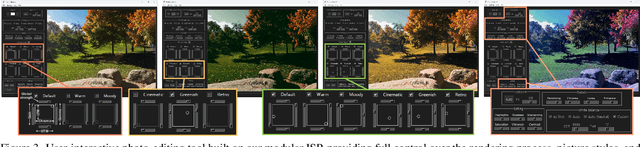
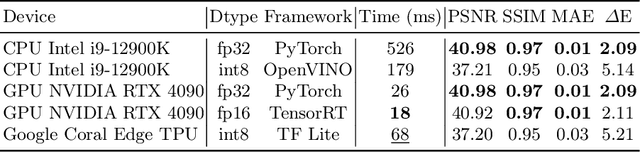
This paper presents a modular neural image signal processing (ISP) framework that processes raw inputs and renders high-quality display-referred images. Unlike prior neural ISP designs, our method introduces a high degree of modularity, providing full control over multiple intermediate stages of the rendering process.~This modular design not only achieves high rendering accuracy but also improves scalability, debuggability, generalization to unseen cameras, and flexibility to match different user-preference styles. To demonstrate the advantages of this design, we built a user-interactive photo-editing tool that leverages our neural ISP to support diverse editing operations and picture styles. The tool is carefully engineered to take advantage of the high-quality rendering of our neural ISP and to enable unlimited post-editable re-rendering. Our method is a fully learning-based framework with variants of different capacities, all of moderate size (ranging from ~0.5 M to ~3.9 M parameters for the entire pipeline), and consistently delivers competitive qualitative and quantitative results across multiple test sets. Watch the supplemental video at: https://youtu.be/ByhQjQSjxVM
Learning Camera-Agnostic White-Balance Preferences
Jul 02, 2025The image signal processor (ISP) pipeline in modern cameras consists of several modules that transform raw sensor data into visually pleasing images in a display color space. Among these, the auto white balance (AWB) module is essential for compensating for scene illumination. However, commercial AWB systems often strive to compute aesthetic white-balance preferences rather than accurate neutral color correction. While learning-based methods have improved AWB accuracy, they typically struggle to generalize across different camera sensors -- an issue for smartphones with multiple cameras. Recent work has explored cross-camera AWB, but most methods remain focused on achieving neutral white balance. In contrast, this paper is the first to address aesthetic consistency by learning a post-illuminant-estimation mapping that transforms neutral illuminant corrections into aesthetically preferred corrections in a camera-agnostic space. Once trained, our mapping can be applied after any neutral AWB module to enable consistent and stylized color rendering across unseen cameras. Our proposed model is lightweight -- containing only $\sim$500 parameters -- and runs in just 0.024 milliseconds on a typical flagship mobile CPU. Evaluated on a dataset of 771 smartphone images from three different cameras, our method achieves state-of-the-art performance while remaining fully compatible with existing cross-camera AWB techniques, introducing minimal computational and memory overhead.
CCMNet: Leveraging Calibrated Color Correction Matrices for Cross-Camera Color Constancy
Apr 10, 2025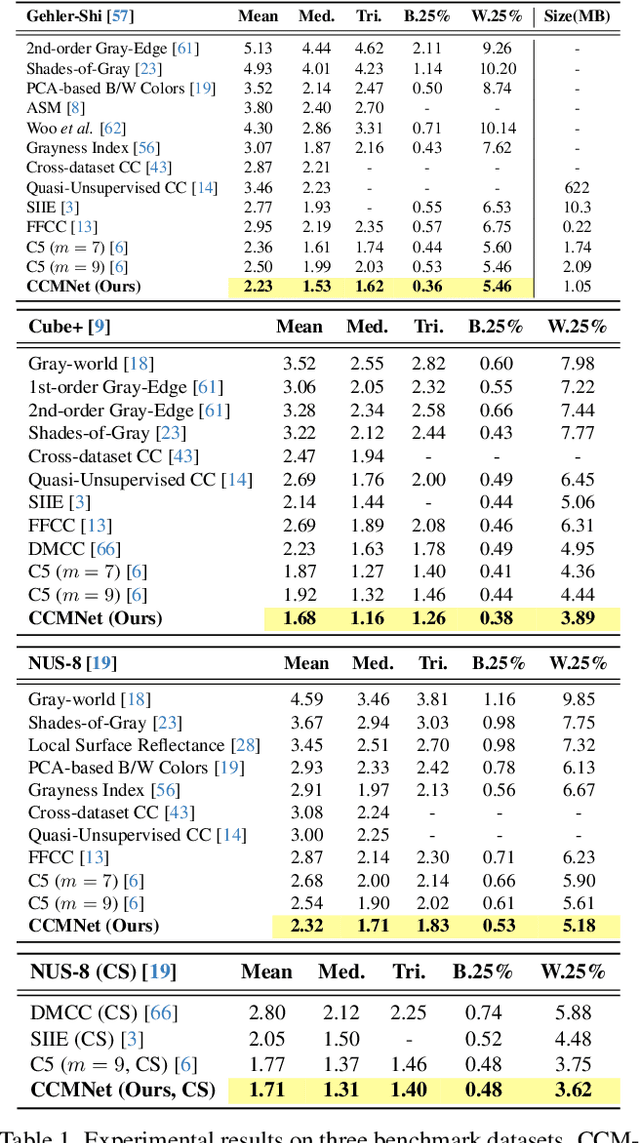
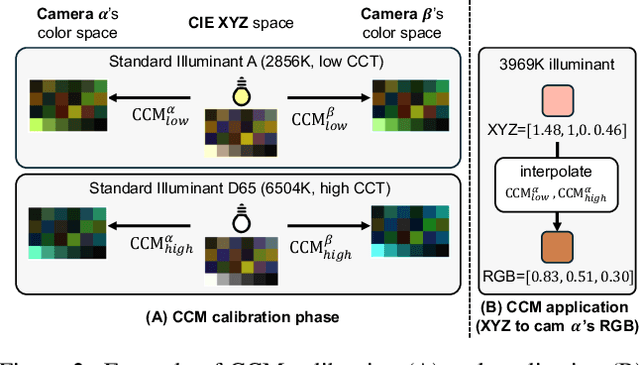
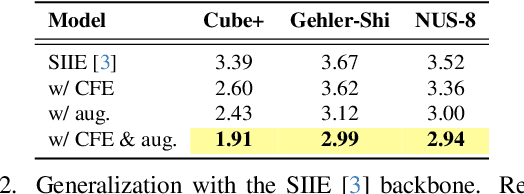
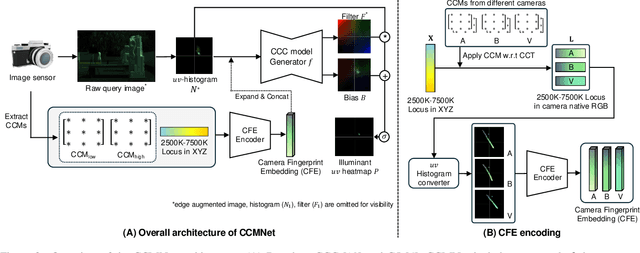
Computational color constancy, or white balancing, is a key module in a camera's image signal processor (ISP) that corrects color casts from scene lighting. Because this operation occurs in the camera-specific raw color space, white balance algorithms must adapt to different cameras. This paper introduces a learning-based method for cross-camera color constancy that generalizes to new cameras without retraining. Our method leverages pre-calibrated color correction matrices (CCMs) available on ISPs that map the camera's raw color space to a standard space (e.g., CIE XYZ). Our method uses these CCMs to transform predefined illumination colors (i.e., along the Planckian locus) into the test camera's raw space. The mapped illuminants are encoded into a compact camera fingerprint embedding (CFE) that enables the network to adapt to unseen cameras. To prevent overfitting due to limited cameras and CCMs during training, we introduce a data augmentation technique that interpolates between cameras and their CCMs. Experimental results across multiple datasets and backbones show that our method achieves state-of-the-art cross-camera color constancy while remaining lightweight and relying only on data readily available in camera ISPs.
Time-Aware Auto White Balance in Mobile Photography
Apr 08, 2025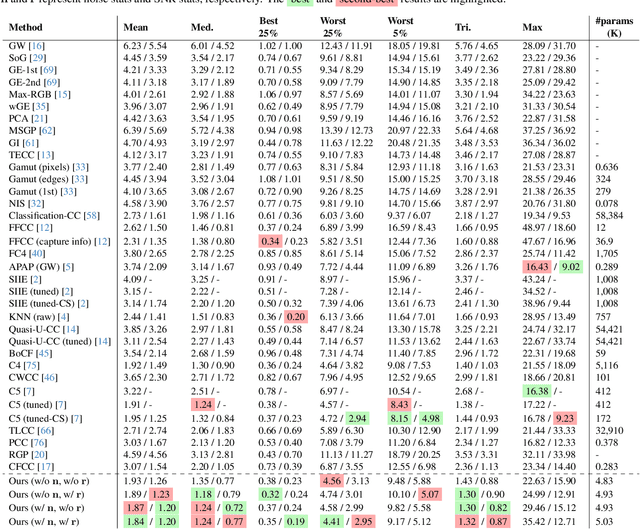
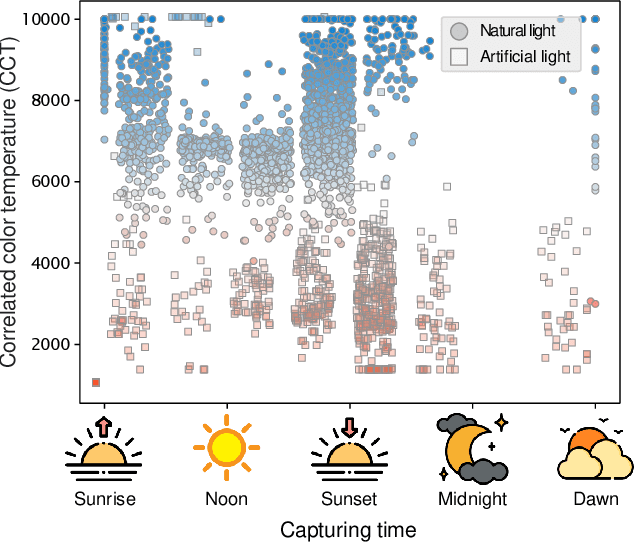
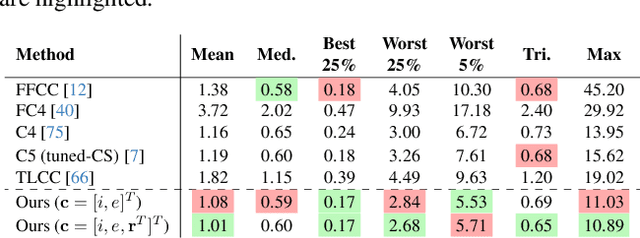
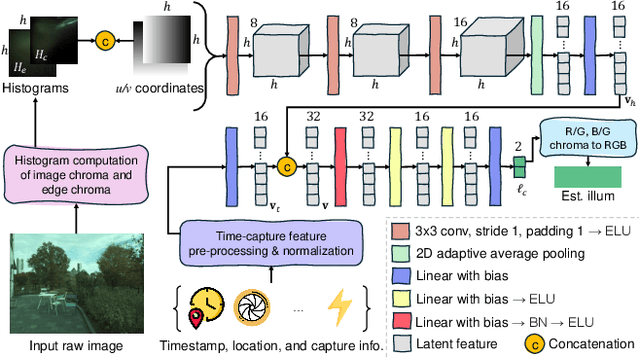
Cameras rely on auto white balance (AWB) to correct undesirable color casts caused by scene illumination and the camera's spectral sensitivity. This is typically achieved using an illuminant estimator that determines the global color cast solely from the color information in the camera's raw sensor image. Mobile devices provide valuable additional metadata-such as capture timestamp and geolocation-that offers strong contextual clues to help narrow down the possible illumination solutions. This paper proposes a lightweight illuminant estimation method that incorporates such contextual metadata, along with additional capture information and image colors, into a compact model (~5K parameters), achieving promising results, matching or surpassing larger models. To validate our method, we introduce a dataset of 3,224 smartphone images with contextual metadata collected at various times of day and under diverse lighting conditions. The dataset includes ground-truth illuminant colors, determined using a color chart, and user-preferred illuminants validated through a user study, providing a comprehensive benchmark for AWB evaluation.
Multispectral Demosaicing via Dual Cameras
Mar 27, 2025



Multispectral (MS) images capture detailed scene information across a wide range of spectral bands, making them invaluable for applications requiring rich spectral data. Integrating MS imaging into multi camera devices, such as smartphones, has the potential to enhance both spectral applications and RGB image quality. A critical step in processing MS data is demosaicing, which reconstructs color information from the mosaic MS images captured by the camera. This paper proposes a method for MS image demosaicing specifically designed for dual-camera setups where both RGB and MS cameras capture the same scene. Our approach leverages co-captured RGB images, which typically have higher spatial fidelity, to guide the demosaicing of lower-fidelity MS images. We introduce the Dual-camera RGB-MS Dataset - a large collection of paired RGB and MS mosaiced images with ground-truth demosaiced outputs - that enables training and evaluation of our method. Experimental results demonstrate that our method achieves state-of-the-art accuracy compared to existing techniques.
Color Matching Using Hypernetwork-Based Kolmogorov-Arnold Networks
Mar 14, 2025We present cmKAN, a versatile framework for color matching. Given an input image with colors from a source color distribution, our method effectively and accurately maps these colors to match a target color distribution in both supervised and unsupervised settings. Our framework leverages the spline capabilities of Kolmogorov-Arnold Networks (KANs) to model the color matching between source and target distributions. Specifically, we developed a hypernetwork that generates spatially varying weight maps to control the nonlinear splines of a KAN, enabling accurate color matching. As part of this work, we introduce a first large-scale dataset of paired images captured by two distinct cameras and evaluate the efficacy of our and existing methods in matching colors. We evaluated our approach across various color-matching tasks, including: (1) raw-to-raw mapping, where the source color distribution is in one camera's raw color space and the target in another camera's raw space; (2) raw-to-sRGB mapping, where the source color distribution is in a camera's raw space and the target is in the display sRGB space, emulating the color rendering of a camera ISP; and (3) sRGB-to-sRGB mapping, where the goal is to transfer colors from a source sRGB space (e.g., produced by a source camera ISP) to a target sRGB space (e.g., from a different camera ISP). The results show that our method outperforms existing approaches by 37.3% on average for supervised and unsupervised cases while remaining lightweight compared to other methods. The codes, dataset, and pre-trained models are available at: https://github.com/gosha20777/cmKAN
Small Contributions, Small Networks: Efficient Neural Network Pruning Based on Relative Importance
Oct 21, 2024
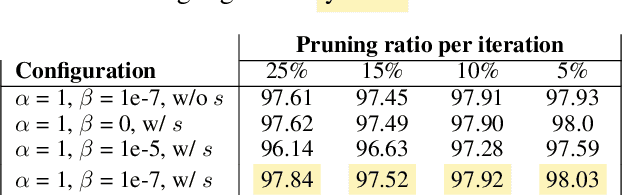

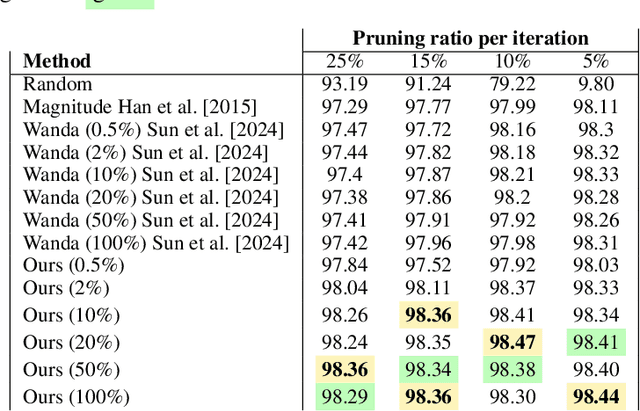
Recent advancements have scaled neural networks to unprecedented sizes, achieving remarkable performance across a wide range of tasks. However, deploying these large-scale models on resource-constrained devices poses significant challenges due to substantial storage and computational requirements. Neural network pruning has emerged as an effective technique to mitigate these limitations by reducing model size and complexity. In this paper, we introduce an intuitive and interpretable pruning method based on activation statistics, rooted in information theory and statistical analysis. Our approach leverages the statistical properties of neuron activations to identify and remove weights with minimal contributions to neuron outputs. Specifically, we build a distribution of weight contributions across the dataset and utilize its parameters to guide the pruning process. Furthermore, we propose a Pruning-aware Training strategy that incorporates an additional regularization term to enhance the effectiveness of our pruning method. Extensive experiments on multiple datasets and network architectures demonstrate that our method consistently outperforms several baseline and state-of-the-art pruning techniques.
What Do You See? Enhancing Zero-Shot Image Classification with Multimodal Large Language Models
May 24, 2024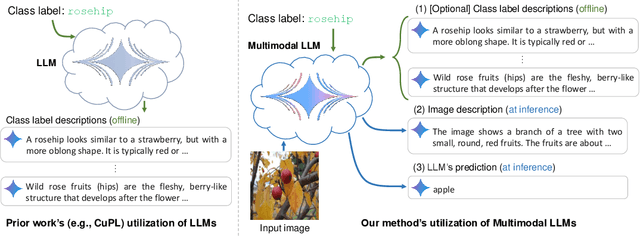
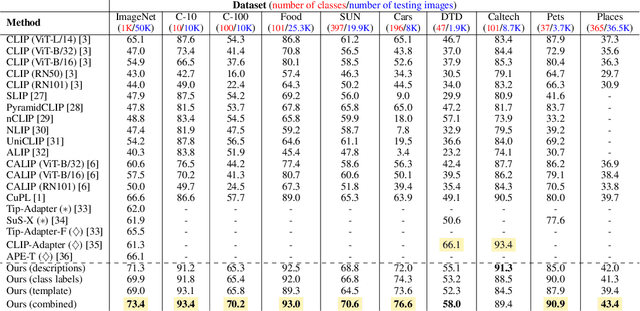
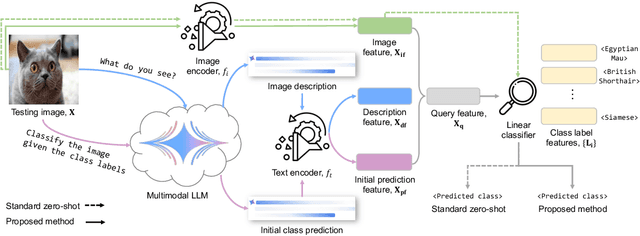
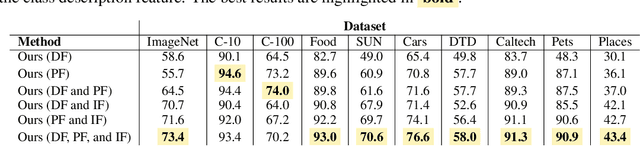
Large language models (LLMs) has been effectively used for many computer vision tasks, including image classification. In this paper, we present a simple yet effective approach for zero-shot image classification using multimodal LLMs. By employing multimodal LLMs, we generate comprehensive textual representations from input images. These textual representations are then utilized to generate fixed-dimensional features in a cross-modal embedding space. Subsequently, these features are fused together to perform zero-shot classification using a linear classifier. Our method does not require prompt engineering for each dataset; instead, we use a single, straightforward, set of prompts across all datasets. We evaluated our method on several datasets, and our results demonstrate its remarkable effectiveness, surpassing benchmark accuracy on multiple datasets. On average over ten benchmarks, our method achieved an accuracy gain of 4.1 percentage points, with an increase of 6.8 percentage points on the ImageNet dataset, compared to prior methods. Our findings highlight the potential of multimodal LLMs to enhance computer vision tasks such as zero-shot image classification, offering a significant improvement over traditional methods.
Rawformer: Unpaired Raw-to-Raw Translation for Learnable Camera ISPs
Apr 16, 2024
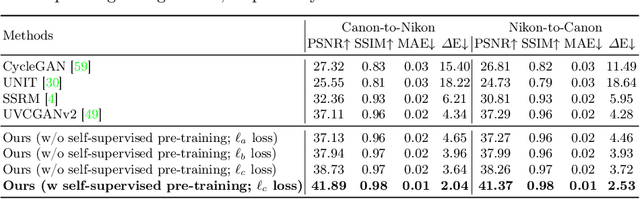
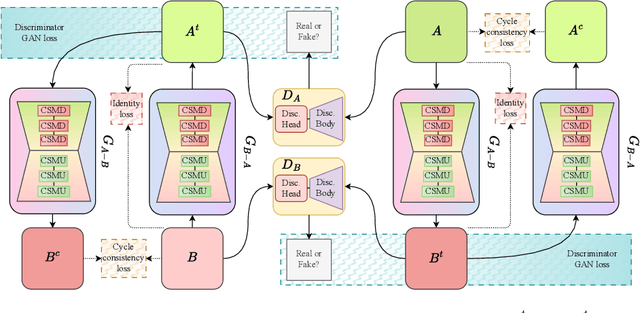
Modern smartphone camera quality heavily relies on the image signal processor (ISP) to enhance captured raw images, utilizing carefully designed modules to produce final output images encoded in a standard color space (e.g., sRGB). Neural-based end-to-end learnable ISPs offer promising advancements, potentially replacing traditional ISPs with their ability to adapt without requiring extensive tuning for each new camera model, as is often the case for nearly every module in traditional ISPs. However, the key challenge with the recent learning-based ISPs is the urge to collect large paired datasets for each distinct camera model due to the influence of intrinsic camera characteristics on the formation of input raw images. This paper tackles this challenge by introducing a novel method for unpaired learning of raw-to-raw translation across diverse cameras. Specifically, we propose Rawformer, an unsupervised Transformer-based encoder-decoder method for raw-to-raw translation. It accurately maps raw images captured by a certain camera to the target camera, facilitating the generalization of learnable ISPs to new unseen cameras. Our method demonstrates superior performance on real camera datasets, achieving higher accuracy compared to previous state-of-the-art techniques, and preserving a more robust correlation between the original and translated raw images.