 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAND: Hierarchical Attention Network for Multi-Scale Handwritten Document Recognition and Layout Analysis
Dec 25, 2024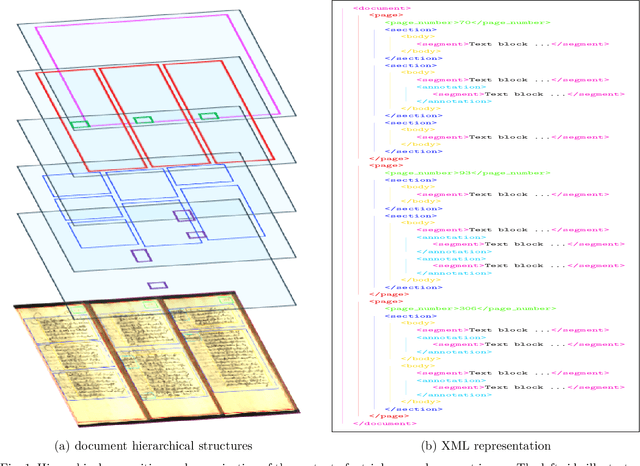

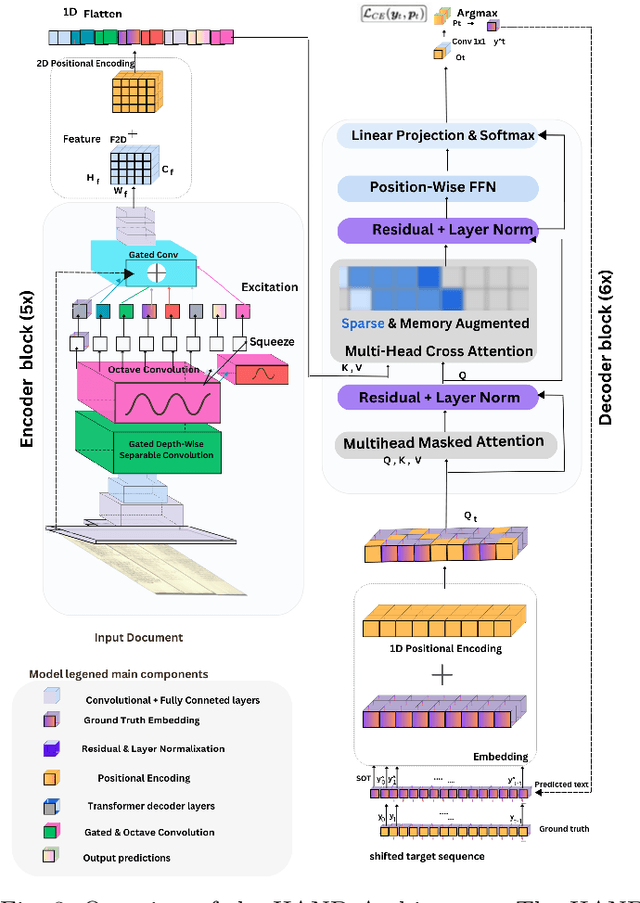

Handwritten document recognition (HDR) is one of the most challenging tasks in the field of computer vision, due to the various writing styles and complex layouts inherent in handwritten texts. Traditionally, this problem has been approached as two separate tasks, handwritten text recognition and layout analysis, and struggled to integrate the two processes effectively. This paper introduces HAND (Hierarchical Attention Network for Multi-Scale Document), a novel end-to-end and segmentation-free architecture for simultaneous text recognition and layout analysis tasks. Our model's key components include an advanced convolutional encoder integrating Gated Depth-wise Separable and Octave Convolutions for robust feature extraction, a Multi-Scale Adaptive Processing (MSAP) framework that dynamically adjusts to document complexity and a hierarchical attention decoder with memory-augmented and sparse attention mechanisms. These components enable our model to scale effectively from single-line to triple-column pages while maintaining computational efficiency. Additionally, HAND adopts curriculum learning across five complexity levels. To improve the recognition accuracy of complex ancient manuscripts, we fine-tune and integrate a Domain-Adaptive Pre-trained mT5 model for post-processing refinement. Extensive evaluations on the READ 2016 dataset demonstrate the superior performance of HAND, achieving up to 59.8% reduction in CER for line-level recognition and 31.2% for page-level recognition compared to state-of-the-art methods. The model also maintains a compact size of 5.60M parameters while establishing new benchmarks in both text recognition and layout analysis. Source code and pre-trained models are available at : https://github.com/MHHamdan/HAND.
HTR-JAND: Handwritten Text Recognition with Joint Attention Network and Knowledge Distillation
Dec 24, 2024
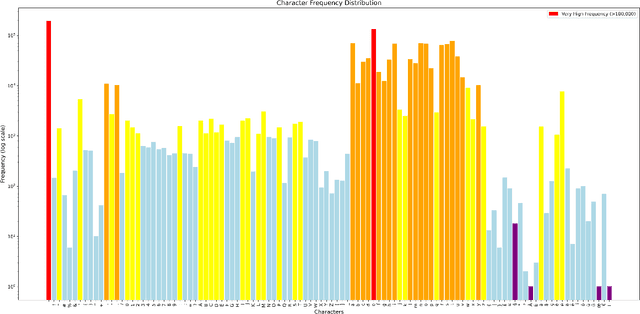
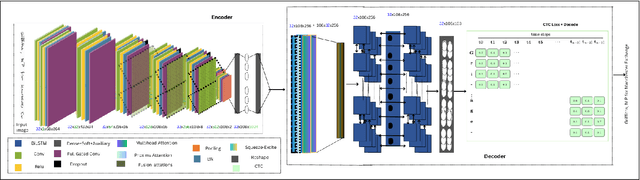
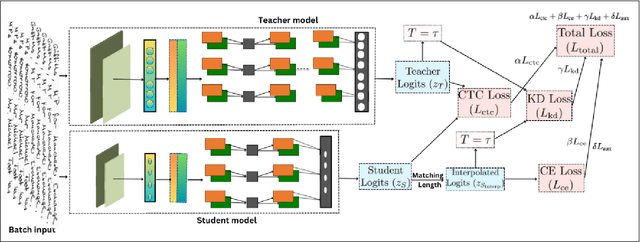
Despite significant advances in deep learning, current Handwritten Text Recognition (HTR) systems struggle with the inherent complexity of historical documents, including diverse writing styles, degraded text quality, and computational efficiency requirements across multiple languages and time periods. This paper introduces HTR-JAND (HTR-JAND: Handwritten Text Recognition with Joint Attention Network and Knowledge Distillation), an efficient HTR framework that combines advanced feature extraction with knowledge distillation. Our architecture incorporates three key components: (1) a CNN architecture integrating FullGatedConv2d layers with Squeeze-and-Excitation blocks for adaptive feature extraction, (2) a Combined Attention mechanism fusing Multi-Head Self-Attention with Proxima Attention for robust sequence modeling, and (3) a Knowledge Distillation framework enabling efficient model compression while preserving accuracy through curriculum-based training. The HTR-JAND framework implements a multi-stage training approach combining curriculum learning, synthetic data generation, and multi-task learning for cross-dataset knowledge transfer. We enhance recognition accuracy through context-aware T5 post-processing, particularly effective for historical documents. Comprehensive evaluations demonstrate HTR-JAND's effectiveness, achieving state-of-the-art Character Error Rates (CER) of 1.23\%, 1.02\%, and 2.02\% on IAM, RIMES, and Bentham datasets respectively. Our Student model achieves a 48\% parameter reduction (0.75M versus 1.5M parameters) while maintaining competitive performance through efficient knowledge transfer. Source code and pre-trained models are available at \href{https://github.com/DocumentRecognitionModels/HTR-JAND}{Github}.
Small Contributions, Small Networks: Efficient Neural Network Pruning Based on Relative Importance
Oct 21, 2024
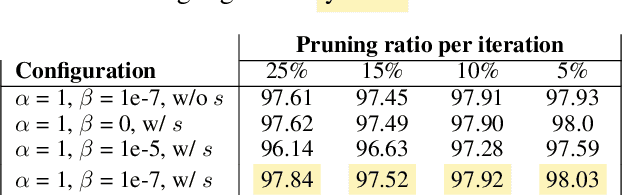

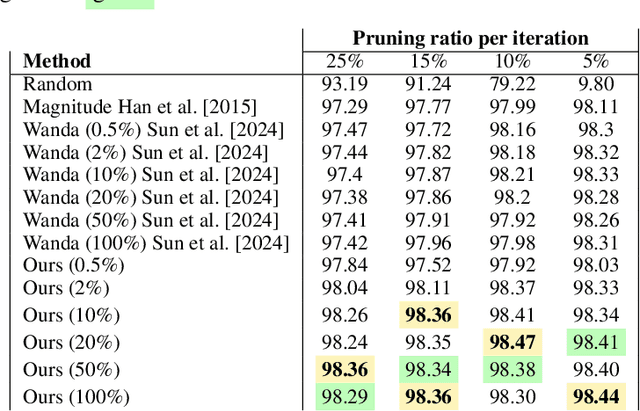
Recent advancements have scaled neural networks to unprecedented sizes, achieving remarkable performance across a wide range of tasks. However, deploying these large-scale models on resource-constrained devices poses significant challenges due to substantial storage and computational requirements. Neural network pruning has emerged as an effective technique to mitigate these limitations by reducing model size and complexity. In this paper, we introduce an intuitive and interpretable pruning method based on activation statistics, rooted in information theory and statistical analysis. Our approach leverages the statistical properties of neuron activations to identify and remove weights with minimal contributions to neuron outputs. Specifically, we build a distribution of weight contributions across the dataset and utilize its parameters to guide the pruning process. Furthermore, we propose a Pruning-aware Training strategy that incorporates an additional regularization term to enhance the effectiveness of our pruning method. Extensive experiments on multiple datasets and network architectures demonstrate that our method consistently outperforms several baseline and state-of-the-art pruning techniques.
Age of Processing-Based Data Offloading for Autonomous Vehicles in Multi-RATs Open RAN
Aug 14, 2023



Today, vehicles use smart sensors to collect data from the road environment. This data is often processed onboard of the vehicles, using expensive hardware. Such onboard processing increases the vehicle's cost, quickly drains its battery, and exhausts its computing resources. Therefore, offloading tasks onto the cloud is required. Still, data offloading is challenging due to low latency requirements for safe and reliable vehicle driving decisions. Moreover, age of processing was not considered in prior research dealing with low-latency offloading for autonomous vehicles. This paper proposes an age of processing-based offloading approach for autonomous vehicles using unsupervised machine learning, Multi-Radio Access Technologies (multi-RATs), and Edge Computing in Open Radio Access Network (O-RAN). We design a collaboration space of edge clouds to process data in proximity to autonomous vehicles. To reduce the variation in offloading delay, we propose a new communication planning approach that enables the vehicle to optimally preselect the available RATs such as Wi-Fi, LTE, or 5G to offload tasks to edge clouds when its local resources are insufficient. We formulate an optimization problem for age-based offloading that minimizes elapsed time from generating tasks and receiving computation output. To handle this non-convex problem, we develop a surrogate problem. Then, we use the Lagrangian method to transform the surrogate problem to unconstrained optimization problem and apply the dual decomposition method. The simulation results show that our approach significantly minimizes the age of processing in data offloading with 90.34 % improvement over similar method.
Non-Negative Matrix Factorization with Scale Data Structure Preservation
Sep 22, 2022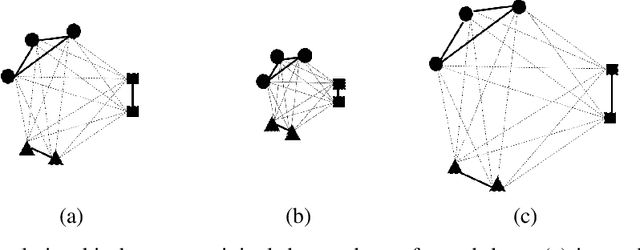
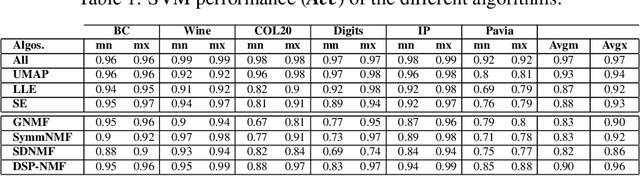
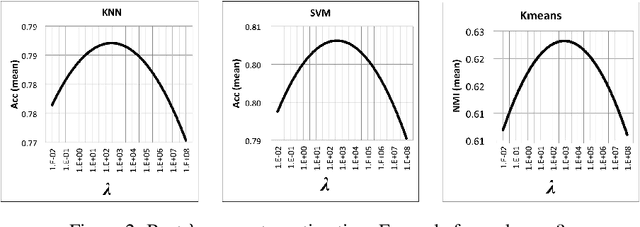
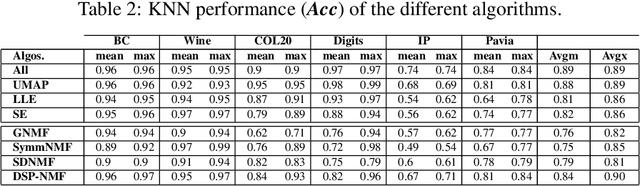
The model described in this paper belongs to the family of non-negative matrix factorization methods designed for data representation and dimension reduction. In addition to preserving the data positivity property, it aims also to preserve the structure of data during matrix factorization. The idea is to add, to the NMF cost function, a penalty term to impose a scale relationship between the pairwise similarity matrices of the original and transformed data points. The solution of the new model involves deriving a new parametrized update scheme for the coefficient matrix, which makes it possible to improve the quality of reduced data when used for clustering and classification. The proposed clustering algorithm is compared to some existing NMF-based algorithms and to some manifold learning-based algorithms when applied to some real-life datasets. The obtained results show the effectiveness of the proposed algorithm.
Leveraging Centric Data Federated Learning Using Blockchain For Integrity Assurance
Jun 09, 2022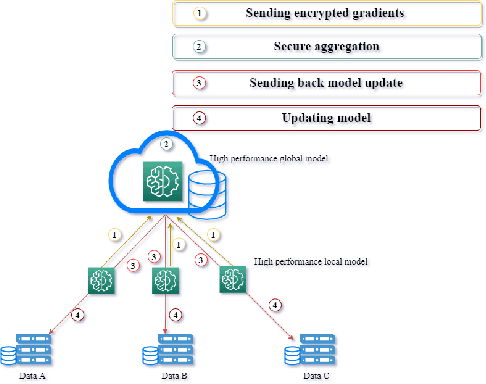
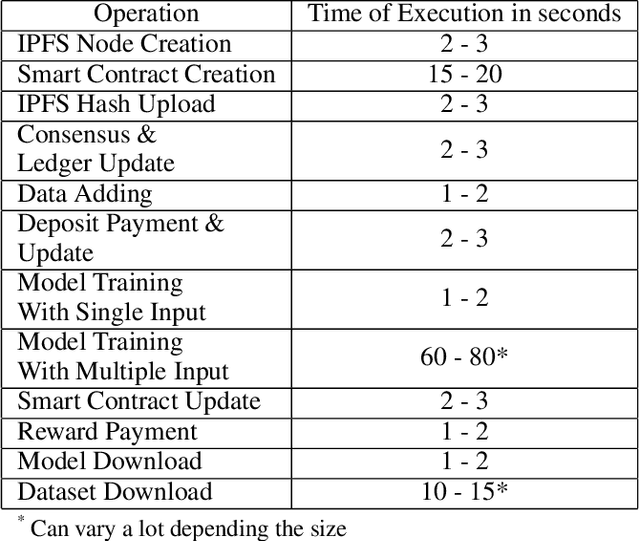
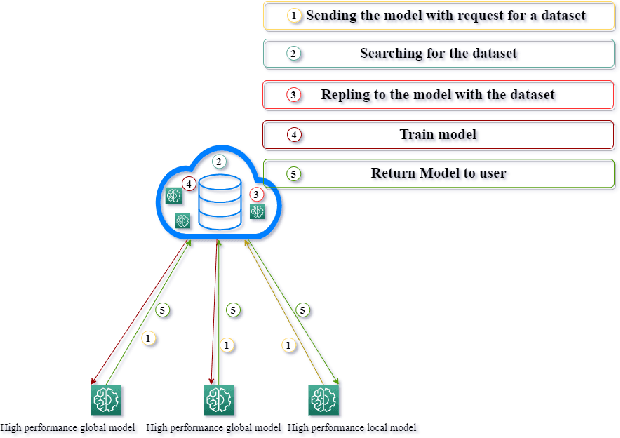
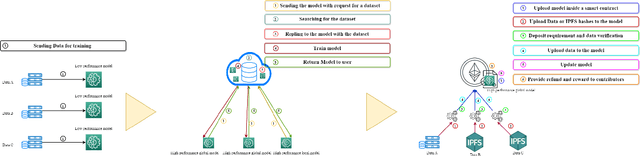
Machine learning abilities have become a vital component for various solutions across industries, applications, and sectors. Many organizations seek to leverage AI-based solutions across their business services to unlock better efficiency and increase productivity. Problems, however, can arise if there is a lack of quality data for AI-model training, scalability, and maintenance. We propose a data-centric federated learning architecture leveraged by a public blockchain and smart contracts to overcome this significant issue. Our proposed solution provides a virtual public marketplace where developers, data scientists, and AI-engineer can publish their models and collaboratively create and access quality data for training. We enhance data quality and integrity through an incentive mechanism that rewards contributors for data contribution and verification. Those combined with the proposed framework helped increase with only one user simulation the training dataset with an average of 100 input daily and the model accuracy by approximately 4\%.
A Learning Framework for Bandwidth-Efficient Distributed Inference in Wireless IoT
Mar 17, 2022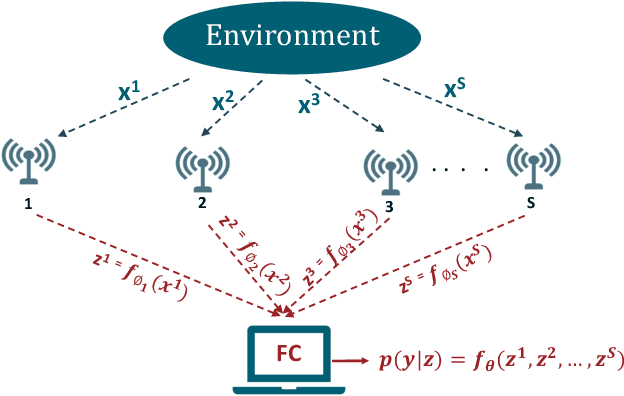
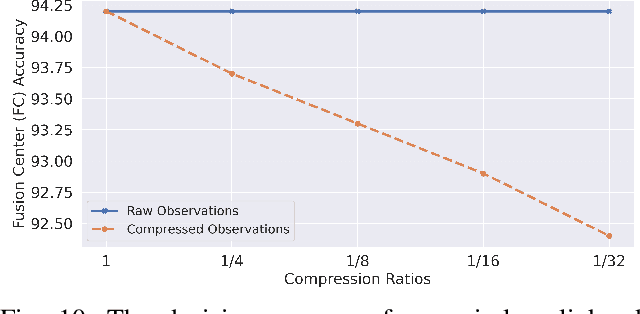
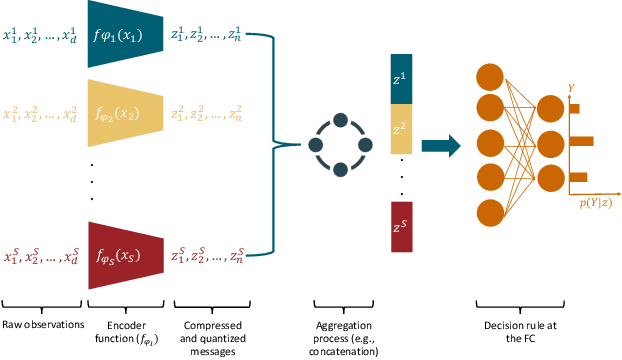

In wireless Internet of things (IoT), the sensors usually have limited bandwidth and power resources. Therefore, in a distributed setup, each sensor should compress and quantize the sensed observations before transmitting them to a fusion center (FC) where a global decision is inferred. Most of the existing compression techniques and entropy quantizers consider only the reconstruction fidelity as a metric, which means they decouple the compression from the sensing goal. In this work, we argue that data compression mechanisms and entropy quantizers should be co-designed with the sensing goal, specifically for machine-consumed data. To this end, we propose a novel deep learning-based framework for compressing and quantizing the observations of correlated sensors. Instead of maximizing the reconstruction fidelity, our objective is to compress the sensor observations in a way that maximizes the accuracy of the inferred decision (i.e., sensing goal) at the FC. Unlike prior work, we do not impose any assumptions about the observations distribution which emphasizes the wide applicability of our framework. We also propose a novel loss function that keeps the model focused on learning complementary features at each sensor. The results show the superior performance of our framework compared to other benchmark models.
Energy Disaggregation using Variational Autoencoders
Mar 22, 2021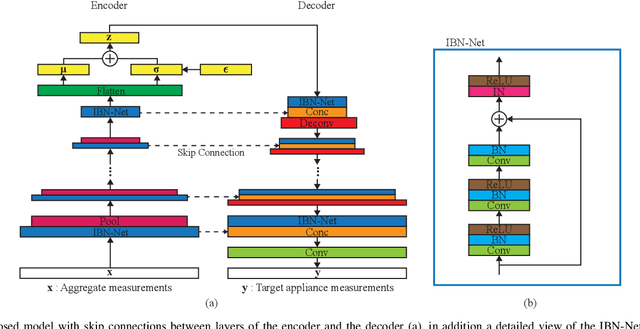
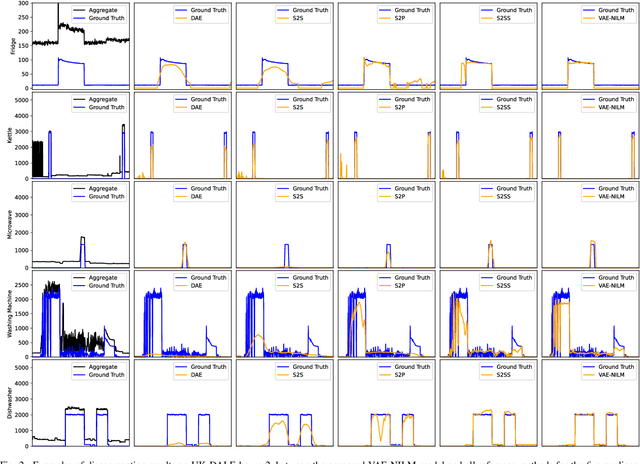
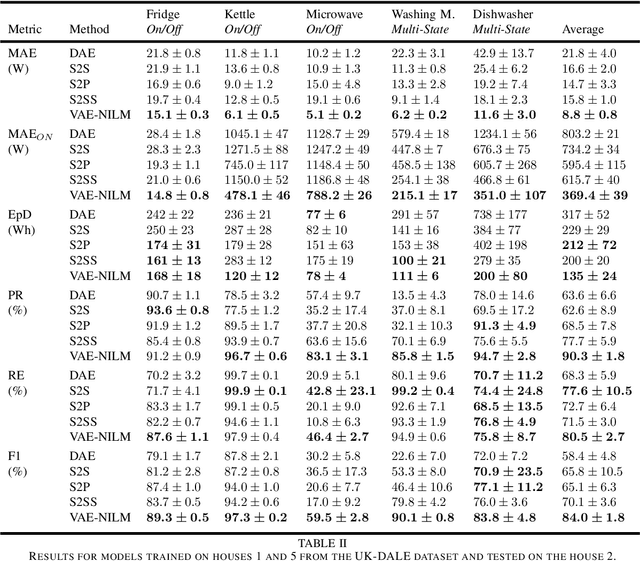
Non-intrusive load monitoring (NILM) is a technique that uses a single sensor to measure the total power consumption of a building. Using an energy disaggregation method, the consumption of individual appliances can be estimated from the aggregate measurement. Recent disaggregation algorithms have significantly improved the performance of NILM systems. However, the generalization capability of these methods to different houses as well as the disaggregation of multi-state appliances are still major challenges. In this paper we address these issues and propose an energy disaggregation approach based on the variational autoencoders (VAE) framework. The probabilistic encoder makes this approach an efficient model for encoding information relevant to the reconstruction of the target appliance consumption. In particular, the proposed model accurately generates more complex load profiles, thus improving the power signal reconstruction of multi-state appliances. Moreover, its regularized latent space improves the generalization capabilities of the model across different houses. The proposed model is compared to state-of-the-art NILM approaches on the UK-DALE dataset, and yields competitive results. The mean absolute error reduces by 18% on average across all appliances compared to the state-of-the-art. The F1-Score increases by more than 11%, showing improvements for the detection of the target appliance in the aggregate measurement.
PRVNet: Variational Autoencoders for Massive MIMO CSI Feedback
Nov 09, 2020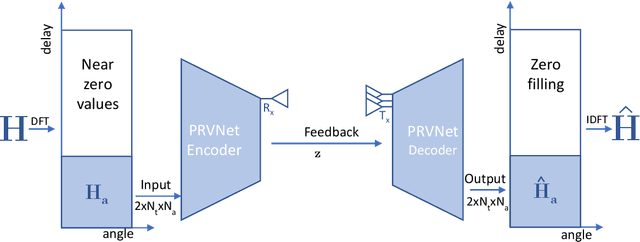
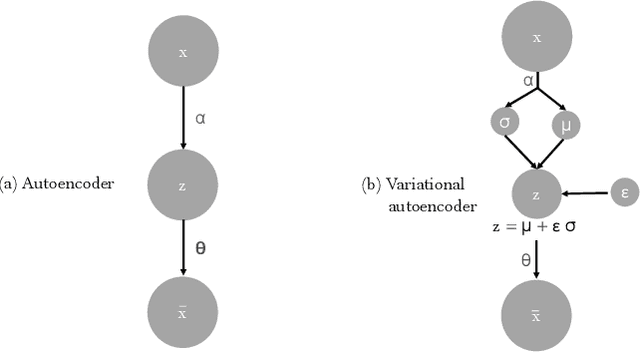
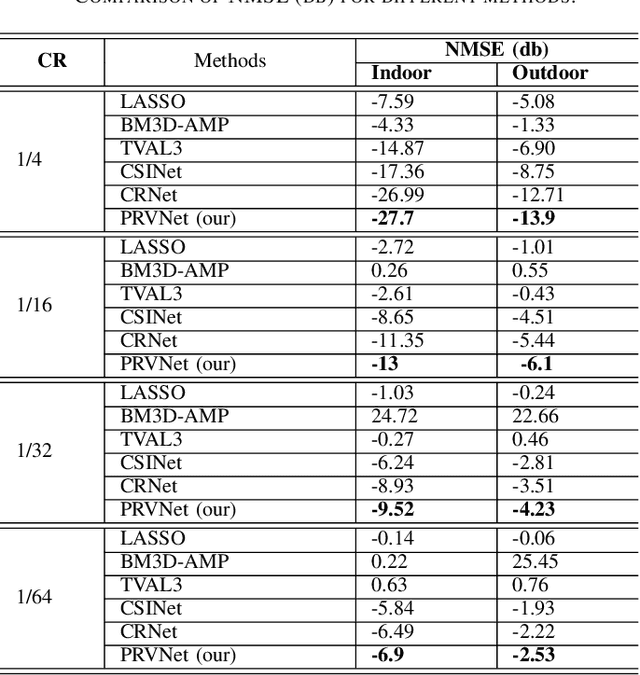

In a frequency division duplexing multiple-input multiple-output (FDD-MIMO) system, the user equipment (UE) send the downlink channel state information (CSI) to the base station for performance improvement. However, with the growing complexity of MIMO systems, this feedback becomes expensive and has a negative impact on the bandwidth. Although this problem has been largely studied in the literature, the noisy nature of the feedback channel is less considered. In this paper, we introduce PRVNet, a neural architecture based on variational autoencoders (VAE). VAE gained large attention in many fields (e.g., image processing, language models, or recommendation system). However, it received less attention in the communication domain generally and in CSI feedback problem specifically. We also introduce a different regularization parameter for the learning objective, which proved to be crucial for achieving competitive performance. In addition, we provide an efficient way to tune this parameter using KL-annealing. Empirically, we show that the proposed model significantly outperforms state-of-the-art, including two neural network approaches. The proposed model is also proved to be more robust against different levels of noise.
BLCS: Brain-Like based Distributed Control Security in Cyber Physical Systems
Feb 08, 2020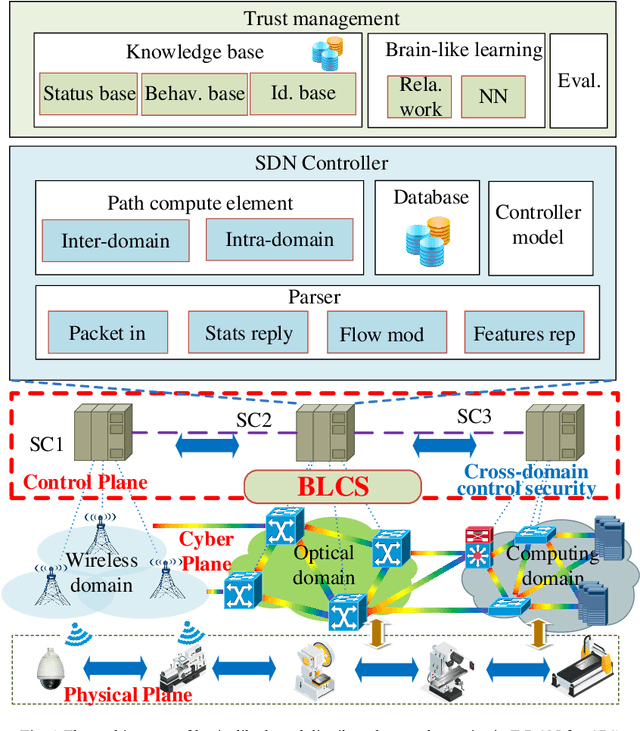
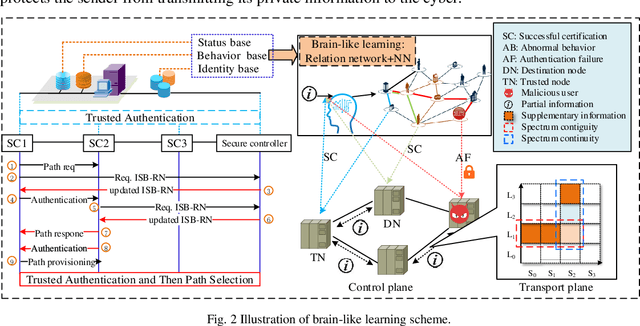
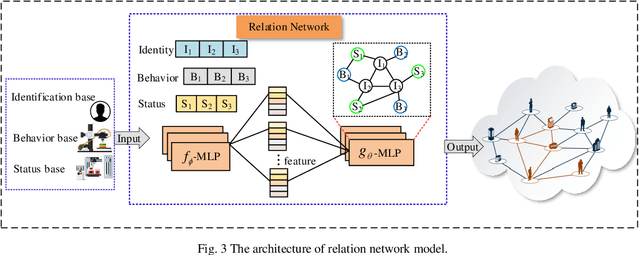
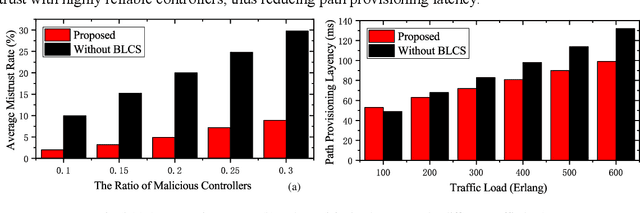
Cyber-physical system (CPS) has operated, controlled and coordinated the physical systems integrated by a computing and communication core applied in industry 4.0. To accommodate CPS services, fog radio and optical networks (F-RON) has become an important supporting physical cyber infrastructure taking advantage of both the inherent ubiquity of wireless technology and the large capacity of optical networks. However, cyber security is the biggest issue in CPS scenario as there is a tradeoff between security control and privacy exposure in F-RON. To deal with this issue, we propose a brain-like based distributed control security (BLCS) architecture for F-RON in CPS, by introducing a brain-like security (BLS) scheme. BLCS can accomplish the secure cross-domain control among tripartite controllers verification in the scenario of decentralized F-RON for distributed computing and communications, which has no need to disclose the private information of each domain against cyber-attacks. BLS utilizes parts of information to perform control identification through relation network and deep learning of behavior library. The functional modules of BLCS architecture are illustrated including various controllers and brain-like knowledge base. The interworking procedures in distributed control security modes based on BLS are described. The overall feasibility and efficiency of architecture are experimentally verified on the software defined network testbed in terms of average mistrust rate, path provisioning latency, packet loss probability and blocking probability. The emulation results are obtained and dissected based on the testbed.