 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Class-pairwise NMF for Data Representation and Classification
Sep 28, 2022



Various Non-negative Matrix factorization (NMF) based methods add new terms to the cost function to adapt the model to specific tasks, such as clustering, or to preserve some structural properties in the reduced space (e.g., local invariance). The added term is mainly weighted by a hyper-parameter to control the balance of the overall formula to guide the optimization process towards the objective. The result is a parameterized NMF method. However, NMF method adopts unsupervised approaches to estimate the factorizing matrices. Thus, the ability to perform prediction (e.g. classification) using the new obtained features is not guaranteed. The objective of this work is to design an evolutionary framework to learn the hyper-parameter of the parameterized NMF and estimate the factorizing matrices in a supervised way to be more suitable for classification problems. Moreover, we claim that applying NMF-based algorithms separately to different class-pairs instead of applying it once to the whole dataset improves the effectiveness of the matrix factorization process. This results in training multiple parameterized NMF algorithms with different balancing parameter values. A cross-validation combination learning framework is adopted and a Genetic Algorithm is used to identify the optimal set of hyper-parameter values. The experiments we conducted on both real and synthetic datasets demonstrated the effectiveness of the proposed approach.
Non-Negative Matrix Factorization with Scale Data Structure Preservation
Sep 22, 2022
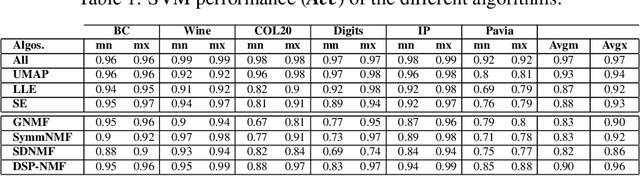
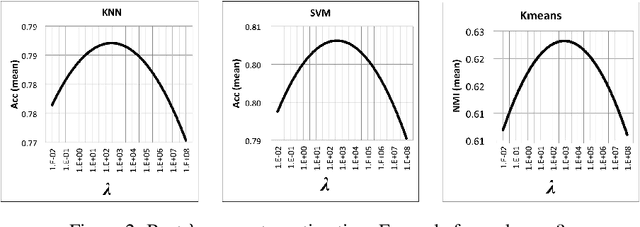
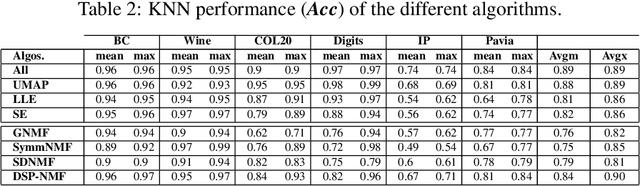
The model described in this paper belongs to the family of non-negative matrix factorization methods designed for data representation and dimension reduction. In addition to preserving the data positivity property, it aims also to preserve the structure of data during matrix factorization. The idea is to add, to the NMF cost function, a penalty term to impose a scale relationship between the pairwise similarity matrices of the original and transformed data points. The solution of the new model involves deriving a new parametrized update scheme for the coefficient matrix, which makes it possible to improve the quality of reduced data when used for clustering and classification. The proposed clustering algorithm is compared to some existing NMF-based algorithms and to some manifold learning-based algorithms when applied to some real-life datasets. The obtained results show the effectiveness of the proposed algorithm.