 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Class-pairwise NMF for Data Representation and Classification
Sep 28, 2022



Various Non-negative Matrix factorization (NMF) based methods add new terms to the cost function to adapt the model to specific tasks, such as clustering, or to preserve some structural properties in the reduced space (e.g., local invariance). The added term is mainly weighted by a hyper-parameter to control the balance of the overall formula to guide the optimization process towards the objective. The result is a parameterized NMF method. However, NMF method adopts unsupervised approaches to estimate the factorizing matrices. Thus, the ability to perform prediction (e.g. classification) using the new obtained features is not guaranteed. The objective of this work is to design an evolutionary framework to learn the hyper-parameter of the parameterized NMF and estimate the factorizing matrices in a supervised way to be more suitable for classification problems. Moreover, we claim that applying NMF-based algorithms separately to different class-pairs instead of applying it once to the whole dataset improves the effectiveness of the matrix factorization process. This results in training multiple parameterized NMF algorithms with different balancing parameter values. A cross-validation combination learning framework is adopted and a Genetic Algorithm is used to identify the optimal set of hyper-parameter values. The experiments we conducted on both real and synthetic datasets demonstrated the effectiveness of the proposed approach.
Non-Negative Matrix Factorization with Scale Data Structure Preservation
Sep 22, 2022
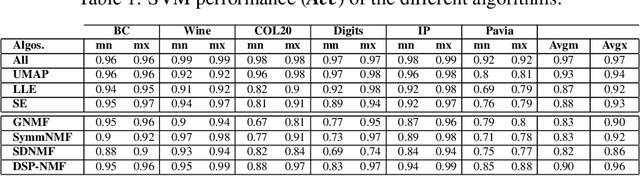
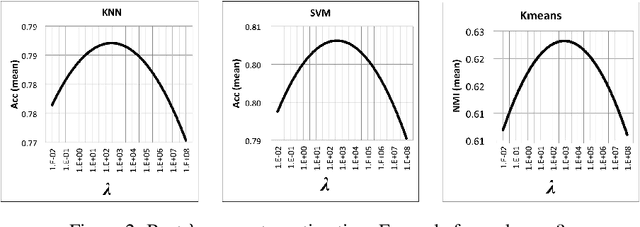
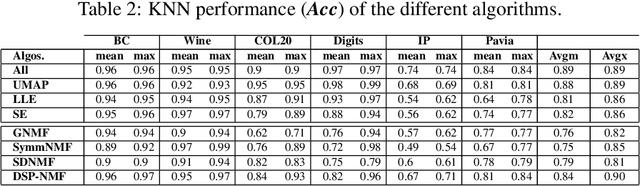
The model described in this paper belongs to the family of non-negative matrix factorization methods designed for data representation and dimension reduction. In addition to preserving the data positivity property, it aims also to preserve the structure of data during matrix factorization. The idea is to add, to the NMF cost function, a penalty term to impose a scale relationship between the pairwise similarity matrices of the original and transformed data points. The solution of the new model involves deriving a new parametrized update scheme for the coefficient matrix, which makes it possible to improve the quality of reduced data when used for clustering and classification. The proposed clustering algorithm is compared to some existing NMF-based algorithms and to some manifold learning-based algorithms when applied to some real-life datasets. The obtained results show the effectiveness of the proposed algorithm.
Mean Deviation Similarity Index: Efficient and Reliable Full-Reference Image Quality Evaluator
Apr 19, 2017



Applications of perceptual image quality assessment (IQA) in image and video processing, such as image acquisition, image compression, image restoration and multimedia communication, have led to the development of many IQA metrics. In this paper, a reliable full reference IQA model is proposed that utilize gradient similarity (GS), chromaticity similarity (CS), and deviation pooling (DP). By considering the shortcomings of the commonly used GS to model human visual system (HVS), a new GS is proposed through a fusion technique that is more likely to follow HVS. We propose an efficient and effective formulation to calculate the joint similarity map of two chromatic channels for the purpose of measuring color changes. In comparison with a commonly used formulation in the literature, the proposed CS map is shown to be more efficient and provide comparable or better quality predictions. Motivated by a recent work that utilizes the standard deviation pooling, a general formulation of the DP is presented in this paper and used to compute a final score from the proposed GS and CS maps. This proposed formulation of DP benefits from the Minkowski pooling and a proposed power pooling as well. The experimental results on six datasets of natural images, a synthetic dataset, and a digitally retouched dataset show that the proposed index provides comparable or better quality predictions than the most recent and competing state-of-the-art IQA metrics in the literature, it is reliable and has low complexity. The MATLAB source code of the proposed metric is available at https://www.mathworks.com/matlabcentral/fileexchange/59809.
MUG: A Parameterless No-Reference JPEG Quality Evaluator Robust to Block Size and Misalignment
Sep 19, 2016



In this letter, a very simple no-reference image quality assessment (NR-IQA) model for JPEG compressed images is proposed. The proposed metric called median of unique gradients (MUG) is based on the very simple facts of unique gradient magnitudes of JPEG compressed images. MUG is a parameterless metric and does not need training. Unlike other NR-IQAs, MUG is independent to block size and cropping. A more stable index called MUG+ is also introduced. The experimental results on six benchmark datasets of natural images and a benchmark dataset of synthetic images show that MUG is comparable to the state-of-the-art indices in literature. In addition, its performance remains unchanged for the case of the cropped images in which block boundaries are not known. The MATLAB source code of the proposed metrics is available at https://dl.dropboxusercontent.com/u/74505502/MUG.m and https://dl.dropboxusercontent.com/u/74505502/MUGplus.m.
Deviation Based Pooling Strategies For Full Reference Image Quality Assessment
May 06, 2015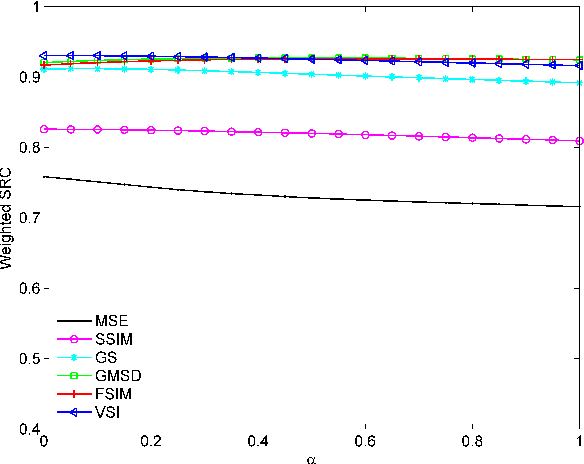
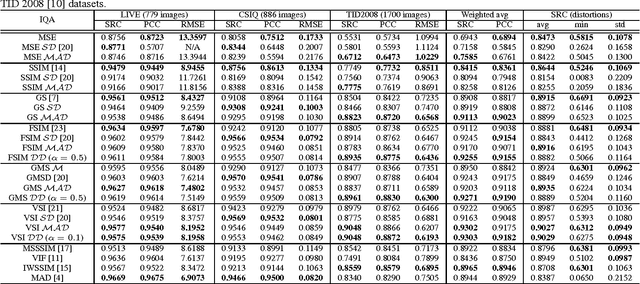

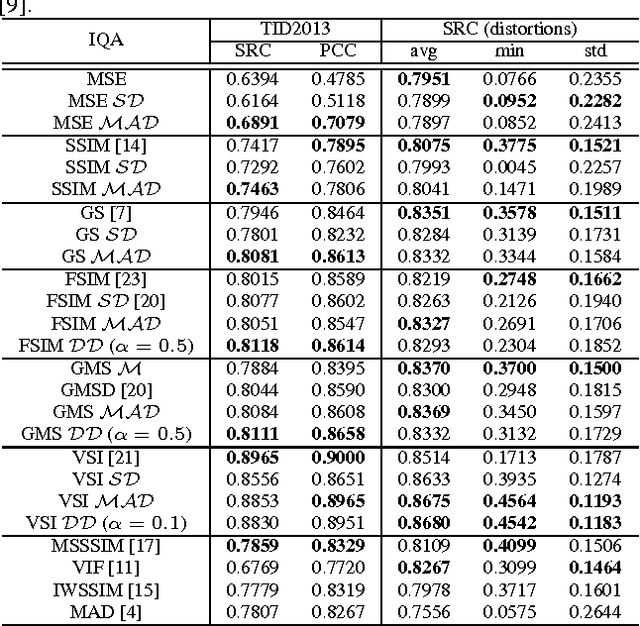
The state-of-the-art pooling strategies for perceptual image quality assessment (IQA) are based on the mean and the weighted mean. They are robust pooling strategies which usually provide a moderate to high performance for different IQAs. Recently, standard deviation (SD) pooling was also proposed. Although, this deviation pooling provides a very high performance for a few IQAs, its performance is lower than mean poolings for many other IQAs. In this paper, we propose to use the mean absolute deviation (MAD) and show that it is a more robust and accurate pooling strategy for a wider range of IQAs. In fact, MAD pooling has the advantages of both mean pooling and SD pooling. The joint computation and use of the MAD and SD pooling strategies is also considered in this paper. Experimental results provide useful information on the choice of the proper deviation pooling strategy for different IQA models.
A maximal-information color to gray conversion method for document images: Toward an optimal grayscale representation for document image binarization
Jun 26, 2013



A novel method to convert color/multi-spectral images to gray-level images is introduced to increase the performance of document binarization methods. The method uses the distribution of the pixel data of the input document image in a color space to find a transformation, called the dual transform, which balances the amount of information on all color channels. Furthermore, in order to reduce the intensity variations on the gray output, a color reduction preprocessing step is applied. Then, a channel is selected as the gray value representation of the document image based on the homogeneity criterion on the text regions. In this way, the proposed method can provide a luminance-independent contrast enhancement. The performance of the method is evaluated against various images from two databases, the ICDAR'03 Robust Reading, the KAIST and the DIBCO'09 datasets, subjectively and objectively with promising results. The ground truth images for the images from the ICDAR'03 Robust Reading dataset have been created manually by the authors.