 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRole-Aware Multi-modal federated learning system for detecting phishing webpages
Sep 26, 2025We present a federated, multi-modal phishing website detector that supports URL, HTML, and IMAGE inputs without binding clients to a fixed modality at inference: any client can invoke any modality head trained elsewhere. Methodologically, we propose role-aware bucket aggregation on top of FedProx, inspired by Mixture-of-Experts and FedMM. We drop learnable routing and use hard gating (selecting the IMAGE/HTML/URL expert by sample modality), enabling separate aggregation of modality-specific parameters to isolate cross-embedding conflicts and stabilize convergence. On TR-OP, the Fusion head reaches Acc 97.5% with FPR 2.4% across two data types; on the image subset (ablation) it attains Acc 95.5% with FPR 5.9%. For text, we use GraphCodeBERT for URLs and an early three-way embedding for raw, noisy HTML. On WebPhish (HTML) we obtain Acc 96.5% / FPR 1.8%; on TR-OP (raw HTML) we obtain Acc 95.1% / FPR 4.6%. Results indicate that bucket aggregation with hard-gated experts enables stable federated training under strict privacy, while improving the usability and flexibility of multi-modal phishing detection.
Human-Robot Mutual Learning through Affective-Linguistic Interaction and Differential Outcomes Training [Pre-Print]
Jul 01, 2024Owing to the recent success of Large Language Models, Modern A.I has been much focused on linguistic interactions with humans but less focused on non-linguistic forms of communication between man and machine. In the present paper, we test how affective-linguistic communication, in combination with differential outcomes training, affects mutual learning in a human-robot context. Taking inspiration from child-caregiver dynamics, our human-robot interaction setup consists of a (simulated) robot attempting to learn how best to communicate internal, homeostatically-controlled needs; while a human "caregiver" attempts to learn the correct object to satisfy the robot's present communicated need. We studied the effects of i) human training type, and ii) robot reinforcement learning type, to assess mutual learning terminal accuracy and rate of learning (as measured by the average reward achieved by the robot). Our results find mutual learning between a human and a robot is significantly improved with Differential Outcomes Training (DOT) compared to Non-DOT (control) conditions. We find further improvements when the robot uses an exploration-exploitation policy selection, compared to purely exploitation policy selection. These findings have implications for utilizing socially assistive robots (SAR) in therapeutic contexts, e.g. for cognitive interventions, and educational applications.
Surprise! Using Physiological Stress for Allostatic Regulation Under the Active Inference Framework [Pre-Print]
Jun 12, 2024Allostasis proposes that long-term viability of a living system is achieved through anticipatory adjustments of its physiology and behaviour: emphasising physiological and affective stress as an adaptive state of adaptation that minimizes long-term prediction errors. More recently, the active inference framework (AIF) has also sought to explain action and long-term adaptation through the minimization of future errors (free energy), through the learning of statistical contingencies of the world, offering a formalism for allostatic regulation. We suggest that framing prediction errors through the lens of biological hormonal dynamics proposed by allostasis offers a way to integrate these two models together in a biologically-plausible manner. In this paper, we describe our initial work in developing a model that grounds prediction errors (surprisal) into the secretion of a physiological stress hormone (cortisol) acting as an adaptive, allostatic mediator on a homeostatically-controlled physiology. We evaluate this using a computational model in simulations using an active inference agent endowed with an artificial physiology, regulated through homeostatic and allostatic control in a stochastic environment. Our results find that allostatic functions of cortisol (stress), secreted as a function of prediction errors, provide adaptive advantages to the agent's long-term physiological regulation. We argue that the coupling of information-theoretic prediction errors to low-level, biological hormonal dynamics of stress can provide a computationally efficient model to long-term regulation for embodied intelligent systems.
Social Media and Artificial Intelligence for Sustainable Cities and Societies: A Water Quality Analysis Use-case
Apr 23, 2024

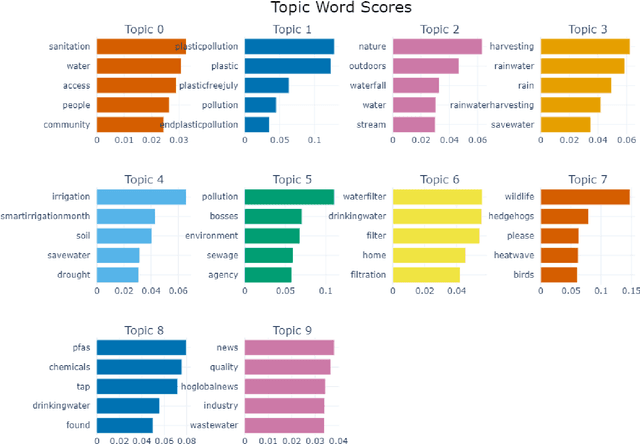

This paper focuses on a very important societal challenge of water quality analysis. Being one of the key factors in the economic and social development of society, the provision of water and ensuring its quality has always remained one of the top priorities of public authorities. To ensure the quality of water, different methods for monitoring and assessing the water networks, such as offline and online surveys, are used. However, these surveys have several limitations, such as the limited number of participants and low frequency due to the labor involved in conducting such surveys. In this paper, we propose a Natural Language Processing (NLP) framework to automatically collect and analyze water-related posts from social media for data-driven decisions. The proposed framework is composed of two components, namely (i) text classification, and (ii) topic modeling. For text classification, we propose a merit-fusion-based framework incorporating several Large Language Models (LLMs) where different weight selection and optimization methods are employed to assign weights to the LLMs. In topic modeling, we employed the BERTopic library to discover the hidden topic patterns in the water-related tweets. We also analyzed relevant tweets originating from different regions and countries to explore global, regional, and country-specific issues and water-related concerns. We also collected and manually annotated a large-scale dataset, which is expected to facilitate future research on the topic.
Towards Operationalizing Social Bonding in Human-Robot Dyads
Oct 17, 2023With momentum increasing in the use of social robots as long-term assistive and collaborative partners, humans developing social bonds with these artificial agents appears to be inevitable. In human-human dyads, social bonding plays a powerful role in regulating behaviours, emotions, and even health. If this is to extend to human-robot dyads, the phenomenology of such relationships (including their emergence and stability) must be better understood. In this paper, we discuss potential approaches towards operationalizing the phenomenon of social bonding between human-robot dyads. We will discuss a number of biobehavioural proxies of social bonding, moving away from existing approaches that use subjective, psychological measures, and instead grounding our approach in some of the evolutionary, neurobiological and physiological correlates of social bond formation in natural systems: (a) reductions in physiological stress (the ''social buffering'' phenomenon), (b) narrowing of spatial proximity between dyads, and (c) inter-dyad behavioural synchrony. We provide relevant evolutionary support for each proposed component, with suggestions and considerations for how they can be recorded in (real-time) human-robot interaction scenarios. With this, we aim to inspire more robust operationalisation of ''social bonding'' between human and artificial (robotic) agents.
Analyzing Compression Techniques for Computer Vision
May 14, 2023Compressing deep networks is highly desirable for practical use-cases in computer vision applications. Several techniques have been explored in the literature, and research has been done in finding efficient strategies for combining them. For this project, we aimed to explore three different basic compression techniques - knowledge distillation, pruning, and quantization for small-scale recognition tasks. Along with the basic methods, we also test the efficacy of combining them in a sequential manner. We analyze them using MNIST and CIFAR-10 datasets and present the results along with few observations inferred from them.
Supervised Class-pairwise NMF for Data Representation and Classification
Sep 28, 2022



Various Non-negative Matrix factorization (NMF) based methods add new terms to the cost function to adapt the model to specific tasks, such as clustering, or to preserve some structural properties in the reduced space (e.g., local invariance). The added term is mainly weighted by a hyper-parameter to control the balance of the overall formula to guide the optimization process towards the objective. The result is a parameterized NMF method. However, NMF method adopts unsupervised approaches to estimate the factorizing matrices. Thus, the ability to perform prediction (e.g. classification) using the new obtained features is not guaranteed. The objective of this work is to design an evolutionary framework to learn the hyper-parameter of the parameterized NMF and estimate the factorizing matrices in a supervised way to be more suitable for classification problems. Moreover, we claim that applying NMF-based algorithms separately to different class-pairs instead of applying it once to the whole dataset improves the effectiveness of the matrix factorization process. This results in training multiple parameterized NMF algorithms with different balancing parameter values. A cross-validation combination learning framework is adopted and a Genetic Algorithm is used to identify the optimal set of hyper-parameter values. The experiments we conducted on both real and synthetic datasets demonstrated the effectiveness of the proposed approach.
An Explainable Regression Framework for Predicting Remaining Useful Life of Machines
Apr 30, 2022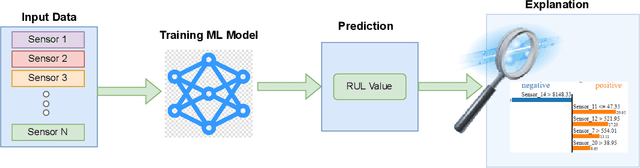
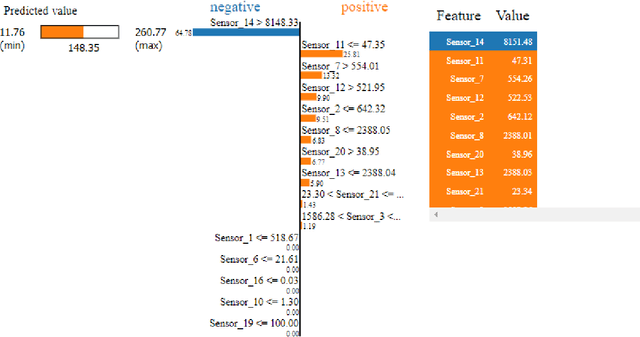

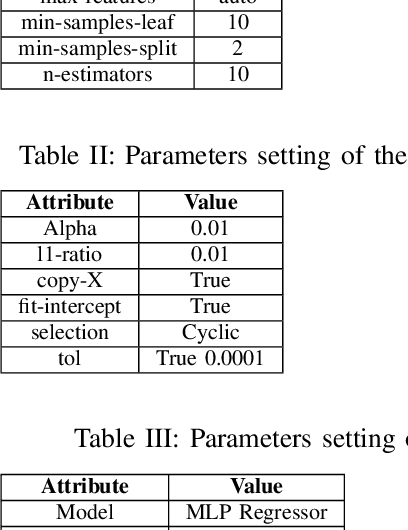
Prediction of a machine's Remaining Useful Life (RUL) is one of the key tasks in predictive maintenance. The task is treated as a regression problem where Machine Learning (ML) algorithms are used to predict the RUL of machine components. These ML algorithms are generally used as a black box with a total focus on the performance without identifying the potential causes behind the algorithms' decisions and their working mechanism. We believe, the performance (in terms of Mean Squared Error (MSE), etc.,) alone is not enough to build the trust of the stakeholders in ML prediction rather more insights on the causes behind the predictions are needed. To this aim, in this paper, we explore the potential of Explainable AI (XAI) techniques by proposing an explainable regression framework for the prediction of machines' RUL. We also evaluate several ML algorithms including classical and Neural Networks (NNs) based solutions for the task. For the explanations, we rely on two model agnostic XAI methods namely Local Interpretable Model-Agnostic Explanations (LIME) and Shapley Additive Explanations (SHAP). We believe, this work will provide a baseline for future research in the domain.
Explainable Event Recognition
Oct 10, 2021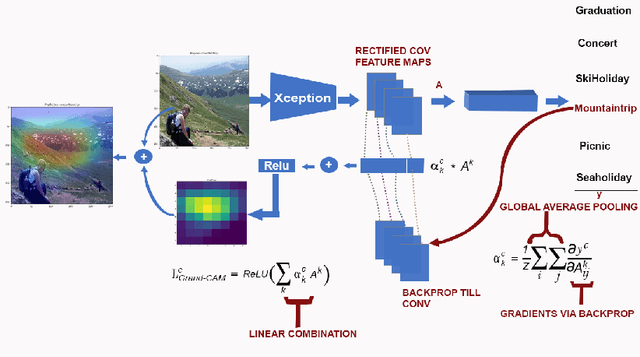
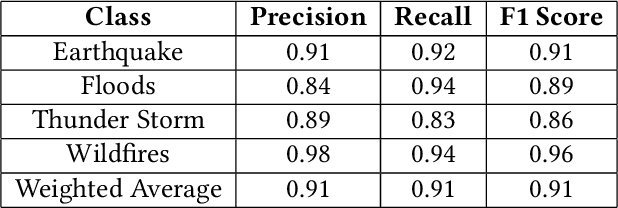


The literature shows outstanding capabilities for CNNs in event recognition in images. However, fewer attempts are made to analyze the potential causes behind the decisions of the models and exploring whether the predictions are based on event-salient objects or regions? To explore this important aspect of event recognition, in this work, we propose an explainable event recognition framework relying on Grad-CAM and an Xception architecture-based CNN model. Experiments are conducted on three large-scale datasets covering a diversified set of natural disasters, social, and sports events. Overall, the model showed outstanding generalization capabilities obtaining overall F1-scores of 0.91, 0.94, and 0.97 on natural disasters, social, and sports events, respectively. Moreover, for subjective analysis of activation maps generated through Grad-CAM for the predicted samples of the model, a crowdsourcing study is conducted to analyze whether the model's predictions are based on event-related objects/regions or not? The results of the study indicate that 78%, 84%, and 78% of the model decisions on natural disasters, sports, and social events datasets, respectively, are based onevent-related objects or regions.
Sentiment Analysis of Users' Reviews on COVID-19 Contact Tracing Apps with a Benchmark Dataset
Mar 01, 2021
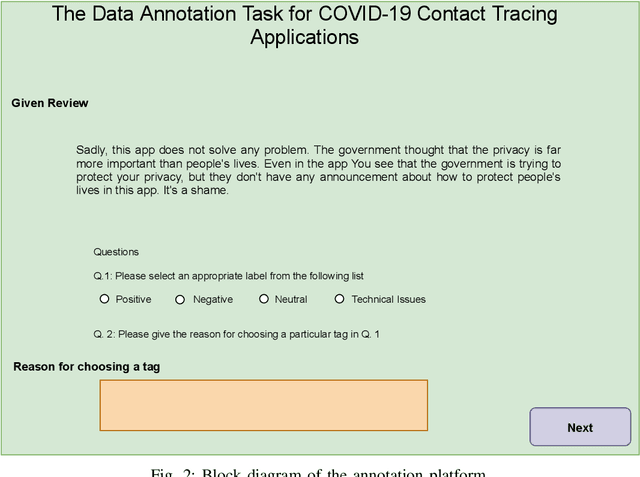
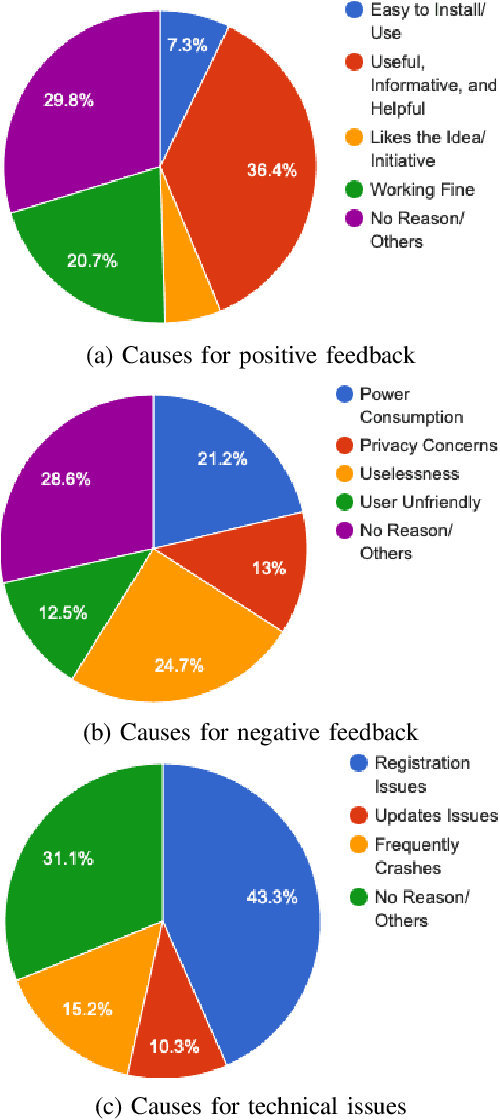
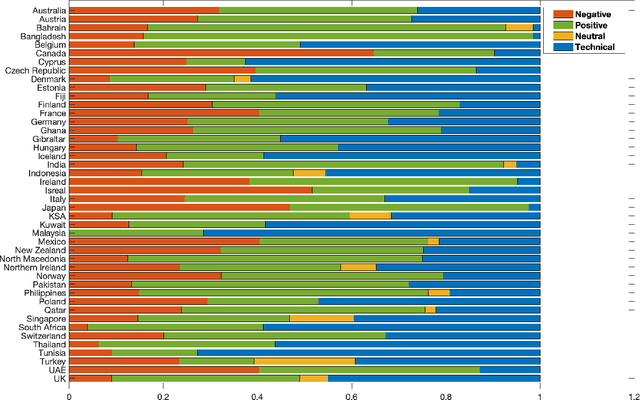
Contact tracing has been globally adopted in the fight to control the infection rate of COVID-19. Thanks to digital technologies, such as smartphones and wearable devices, contacts of COVID-19 patients can be easily traced and informed about their potential exposure to the virus. To this aim, several interesting mobile applications have been developed. However, there are ever-growing concerns over the working mechanism and performance of these applications. The literature already provides some interesting exploratory studies on the community's response to the applications by analyzing information from different sources, such as news and users' reviews of the applications. However, to the best of our knowledge, there is no existing solution that automatically analyzes users' reviews and extracts the evoked sentiments. In this work, we propose a pipeline starting from manual annotation via a crowd-sourcing study and concluding on the development and training of AI models for automatic sentiment analysis of users' reviews. In total, we employ eight different methods achieving up to an average F1-Scores 94.8% indicating the feasibility of automatic sentiment analysis of users' reviews on the COVID-19 contact tracing applications. We also highlight the key advantages, drawbacks, and users' concerns over the applications. Moreover, we also collect and annotate a large-scale dataset composed of 34,534 reviews manually annotated from the contract tracing applications of 46 distinct countries. The presented analysis and the dataset are expected to provide a baseline/benchmark for future research in the domain.