 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Explainable Regression Framework for Predicting Remaining Useful Life of Machines
Apr 30, 2022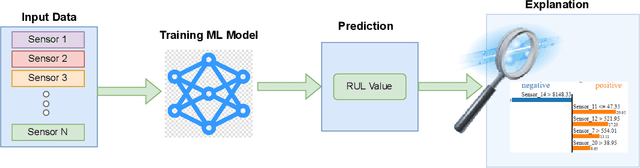
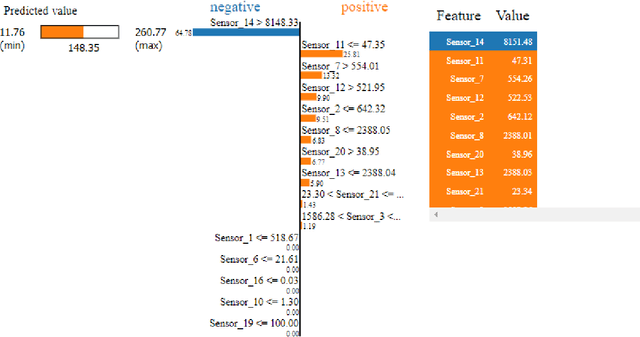

Prediction of a machine's Remaining Useful Life (RUL) is one of the key tasks in predictive maintenance. The task is treated as a regression problem where Machine Learning (ML) algorithms are used to predict the RUL of machine components. These ML algorithms are generally used as a black box with a total focus on the performance without identifying the potential causes behind the algorithms' decisions and their working mechanism. We believe, the performance (in terms of Mean Squared Error (MSE), etc.,) alone is not enough to build the trust of the stakeholders in ML prediction rather more insights on the causes behind the predictions are needed. To this aim, in this paper, we explore the potential of Explainable AI (XAI) techniques by proposing an explainable regression framework for the prediction of machines' RUL. We also evaluate several ML algorithms including classical and Neural Networks (NNs) based solutions for the task. For the explanations, we rely on two model agnostic XAI methods namely Local Interpretable Model-Agnostic Explanations (LIME) and Shapley Additive Explanations (SHAP). We believe, this work will provide a baseline for future research in the domain.
Explainable Event Recognition
Oct 10, 2021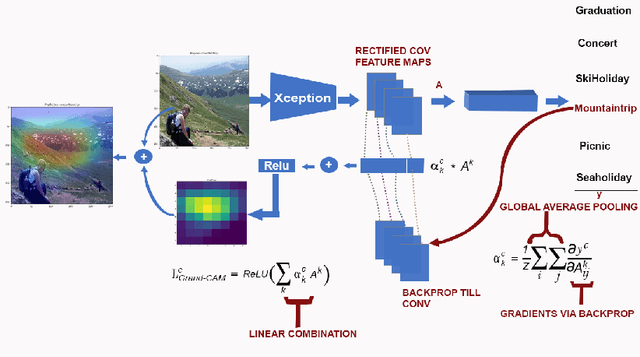
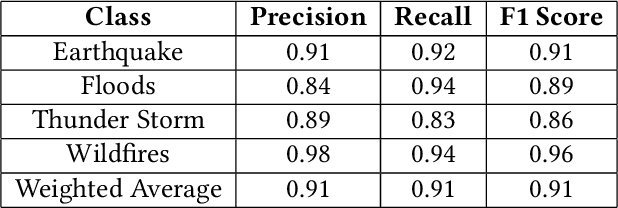


The literature shows outstanding capabilities for CNNs in event recognition in images. However, fewer attempts are made to analyze the potential causes behind the decisions of the models and exploring whether the predictions are based on event-salient objects or regions? To explore this important aspect of event recognition, in this work, we propose an explainable event recognition framework relying on Grad-CAM and an Xception architecture-based CNN model. Experiments are conducted on three large-scale datasets covering a diversified set of natural disasters, social, and sports events. Overall, the model showed outstanding generalization capabilities obtaining overall F1-scores of 0.91, 0.94, and 0.97 on natural disasters, social, and sports events, respectively. Moreover, for subjective analysis of activation maps generated through Grad-CAM for the predicted samples of the model, a crowdsourcing study is conducted to analyze whether the model's predictions are based on event-related objects/regions or not? The results of the study indicate that 78%, 84%, and 78% of the model decisions on natural disasters, sports, and social events datasets, respectively, are based onevent-related objects or regions.
Sentiment Analysis of Users' Reviews on COVID-19 Contact Tracing Apps with a Benchmark Dataset
Mar 01, 2021
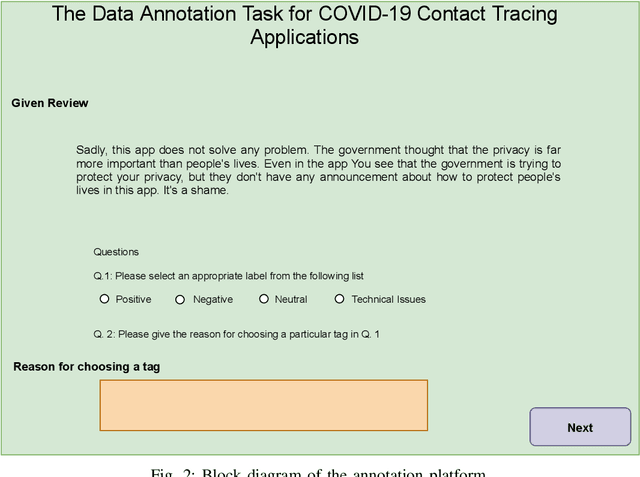
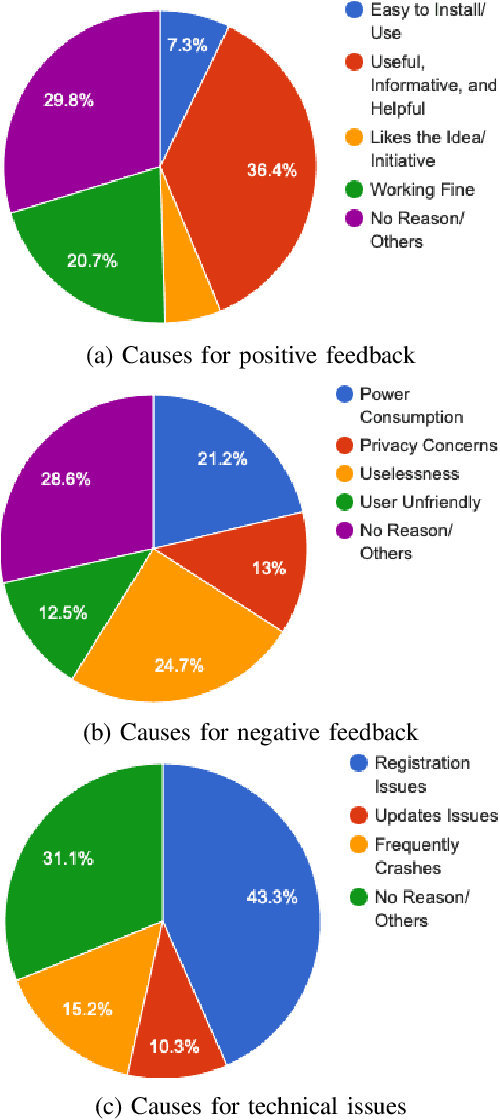
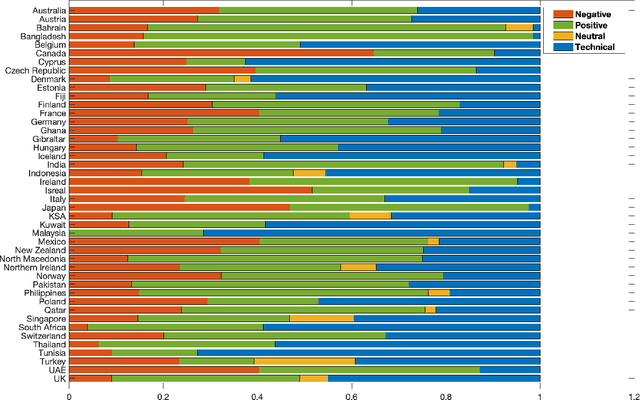
Contact tracing has been globally adopted in the fight to control the infection rate of COVID-19. Thanks to digital technologies, such as smartphones and wearable devices, contacts of COVID-19 patients can be easily traced and informed about their potential exposure to the virus. To this aim, several interesting mobile applications have been developed. However, there are ever-growing concerns over the working mechanism and performance of these applications. The literature already provides some interesting exploratory studies on the community's response to the applications by analyzing information from different sources, such as news and users' reviews of the applications. However, to the best of our knowledge, there is no existing solution that automatically analyzes users' reviews and extracts the evoked sentiments. In this work, we propose a pipeline starting from manual annotation via a crowd-sourcing study and concluding on the development and training of AI models for automatic sentiment analysis of users' reviews. In total, we employ eight different methods achieving up to an average F1-Scores 94.8% indicating the feasibility of automatic sentiment analysis of users' reviews on the COVID-19 contact tracing applications. We also highlight the key advantages, drawbacks, and users' concerns over the applications. Moreover, we also collect and annotate a large-scale dataset composed of 34,534 reviews manually annotated from the contract tracing applications of 46 distinct countries. The presented analysis and the dataset are expected to provide a baseline/benchmark for future research in the domain.