 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Late Fusion Framework with Multiple Optimization Methods for Media Interestingness
Jul 11, 2022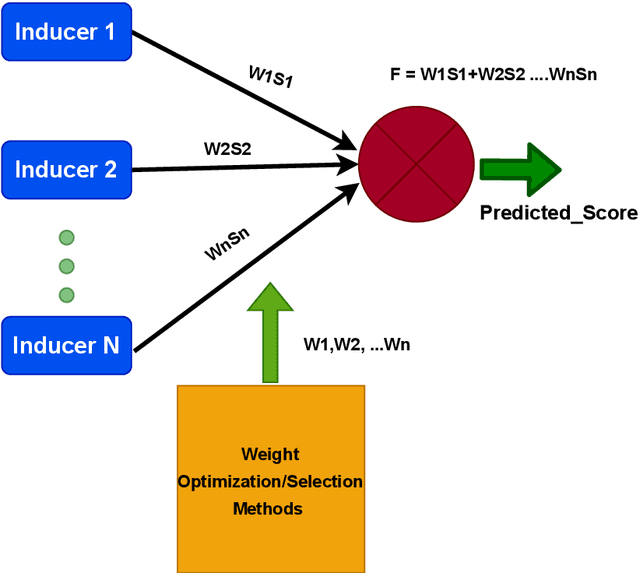
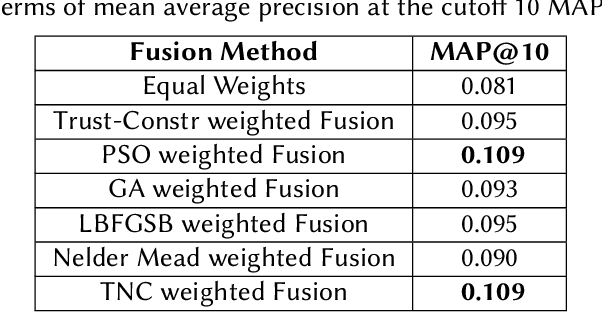
The recent advancement in Multimedia Analytical, Computer Vision (CV), and Artificial Intelligence (AI) algorithms resulted in several interesting tools allowing an automatic analysis and retrieval of multimedia content of users' interests. However, retrieving the content of interest generally involves analysis and extraction of semantic features, such as emotions and interestingness-level. The extraction of such meaningful information is a complex task and generally, the performance of individual algorithms is very low. One way to enhance the performance of the individual algorithms is to combine the predictive capabilities of multiple algorithms using fusion schemes. This allows the individual algorithms to complement each other, leading to improved performance. This paper proposes several fusion methods for the media interestingness score prediction task introduced in CLEF Fusion 2022. The proposed methods include both a naive fusion scheme, where all the inducers are treated equally and a merit-based fusion scheme where multiple weight optimization methods are employed to assign weights to the individual inducers. In total, we used six optimization methods including a Particle Swarm Optimization (PSO), a Genetic Algorithm (GA), Nelder Mead, Trust Region Constrained (TRC), and Limited-memory Broyden Fletcher Goldfarb Shanno Algorithm (LBFGSA), and Truncated Newton Algorithm (TNA). Overall better results are obtained with PSO and TNA achieving 0.109 mean average precision at 10. The task is complex and generally, scores are low. We believe the presented analysis will provide a baseline for future research in the domain.
Sentiment Analysis of Users' Reviews on COVID-19 Contact Tracing Apps with a Benchmark Dataset
Mar 01, 2021
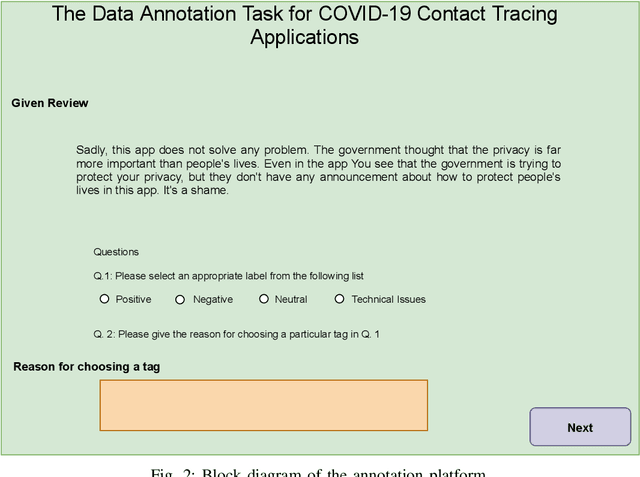
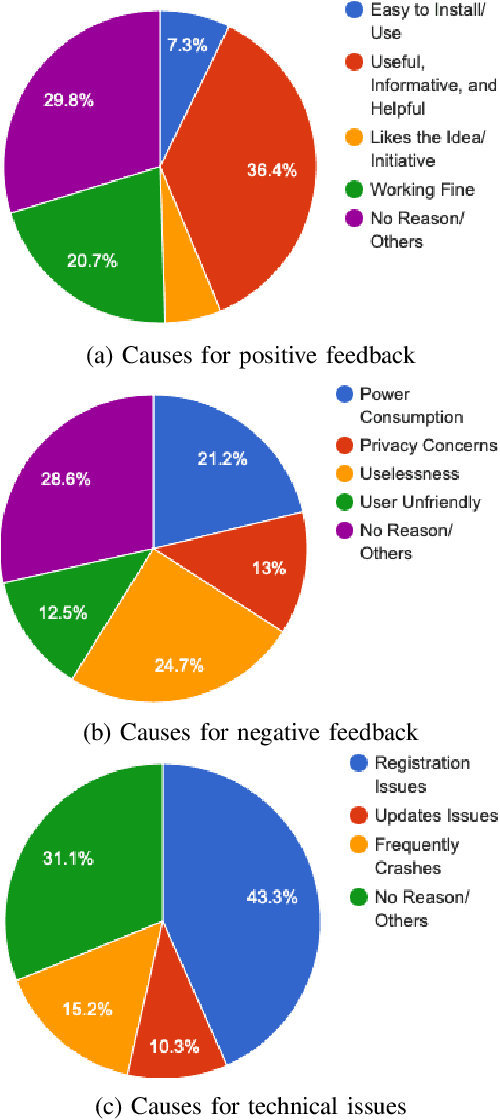
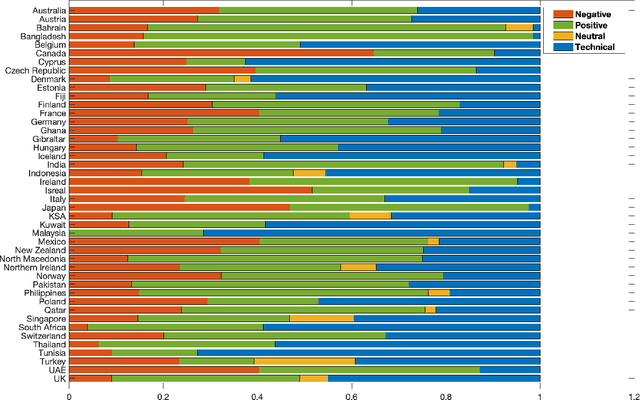
Contact tracing has been globally adopted in the fight to control the infection rate of COVID-19. Thanks to digital technologies, such as smartphones and wearable devices, contacts of COVID-19 patients can be easily traced and informed about their potential exposure to the virus. To this aim, several interesting mobile applications have been developed. However, there are ever-growing concerns over the working mechanism and performance of these applications. The literature already provides some interesting exploratory studies on the community's response to the applications by analyzing information from different sources, such as news and users' reviews of the applications. However, to the best of our knowledge, there is no existing solution that automatically analyzes users' reviews and extracts the evoked sentiments. In this work, we propose a pipeline starting from manual annotation via a crowd-sourcing study and concluding on the development and training of AI models for automatic sentiment analysis of users' reviews. In total, we employ eight different methods achieving up to an average F1-Scores 94.8% indicating the feasibility of automatic sentiment analysis of users' reviews on the COVID-19 contact tracing applications. We also highlight the key advantages, drawbacks, and users' concerns over the applications. Moreover, we also collect and annotate a large-scale dataset composed of 34,534 reviews manually annotated from the contract tracing applications of 46 distinct countries. The presented analysis and the dataset are expected to provide a baseline/benchmark for future research in the domain.
Fake News Detection in Social Media using Graph Neural Networks and NLP Techniques: A COVID-19 Use-case
Nov 30, 2020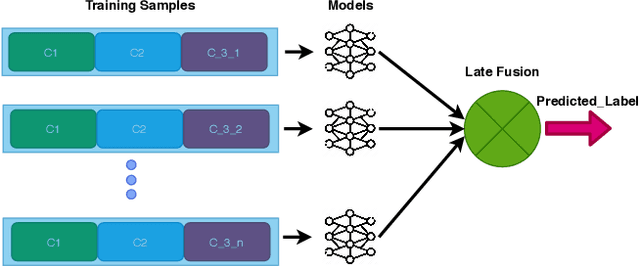
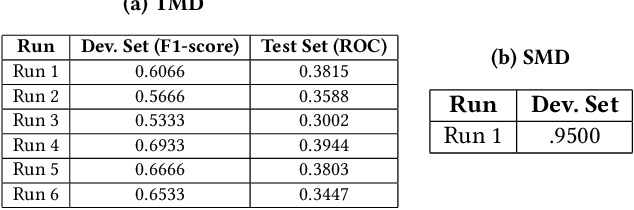
The paper presents our solutions for the MediaEval 2020 task namely FakeNews: Corona Virus and 5G Conspiracy Multimedia Twitter-Data-Based Analysis. The task aims to analyze tweets related to COVID-19 and 5G conspiracy theories to detect misinformation spreaders. The task is composed of two sub-tasks namely (i) text-based, and (ii) structure-based fake news detection. For the first task, we propose six different solutions relying on Bag of Words (BoW) and BERT embedding. Three of the methods aim at binary classification task by differentiating in 5G conspiracy and the rest of the COVID-19 related tweets while the rest of them treat the task as ternary classification problem. In the ternary classification task, our BoW and BERT based methods obtained an F1-score of .606% and .566% on the development set, respectively. On the binary classification, the BoW and BERT based solutions obtained an average F1-score of .666% and .693%, respectively. On the other hand, for structure-based fake news detection, we rely on Graph Neural Networks (GNNs) achieving an average ROC of .95% on the development set.
Floods Detection in Twitter Text and Images
Nov 30, 2020
In this paper, we present our methods for the MediaEval 2020 Flood Related Multimedia task, which aims to analyze and combine textual and visual content from social media for the detection of real-world flooding events. The task mainly focuses on identifying floods related tweets relevant to a specific area. We propose several schemes to address the challenge. For text-based flood events detection, we use three different methods, relying on Bog of Words (BOW) and an Italian Version of Bert individually and in combination, achieving an F1-score of 0.77%, 0.68%, and 0.70% on the development set, respectively. For the visual analysis, we rely on features extracted via multiple state-of-the-art deep models pre-trained on ImageNet. The extracted features are then used to train multiple individual classifiers whose scores are then combined in a late fusion manner achieving an F1-score of 0.75%. For our mandatory multi-modal run, we combine the classification scores obtained with the best textual and visual schemes in a late fusion manner. Overall, better results are obtained with the multimodal scheme achieving an F1-score of 0.80% on the development set.
Active Learning for Event Detection in Support of Disaster Analysis Applications
Sep 27, 2019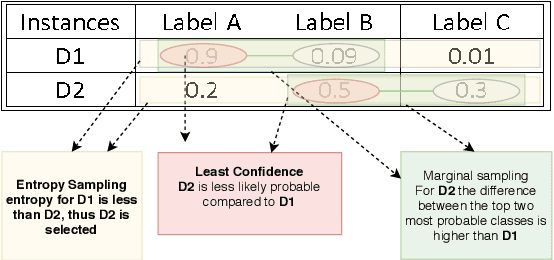
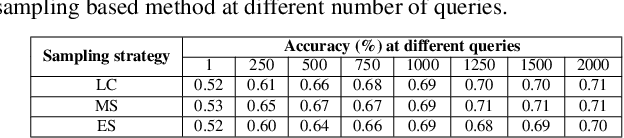
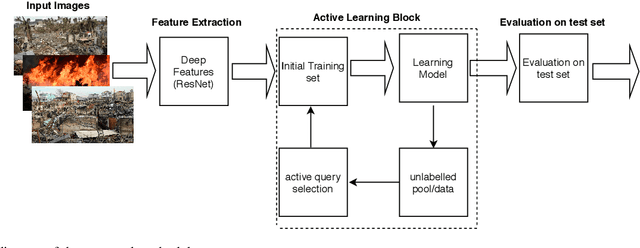

Disaster analysis in social media content is one of the interesting research domains having abundance of data. However, there is a lack of labeled data that can be used to train machine learning models for disaster analysis applications. Active learning is one of the possible solutions to such problem. To this aim, in this paper we propose and assess the efficacy of an active learning based framework for disaster analysis using images shared on social media outlets. Specifically, we analyze the performance of different active learning techniques employing several sampling and disagreement strategies. Moreover, we collect a large-scale dataset covering images from eight common types of natural disasters. The experimental results show that the use of active learning techniques for disaster analysis using images results in a performance comparable to that obtained using human annotated images, and could be used in frameworks for disaster analysis in images without tedious job of manual annotation.