 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDFoam: Signed-Distance Foam for explicit surface reconstruction
Dec 18, 2025Neural radiance fields (NeRF) have driven impressive progress in view synthesis by using ray-traced volumetric rendering. Splatting-based methods such as 3D Gaussian Splatting (3DGS) provide faster rendering by rasterizing 3D primitives. RadiantFoam (RF) brought ray tracing back, achieving throughput comparable to Gaussian Splatting by organizing radiance with an explicit Voronoi Diagram (VD). Yet, all the mentioned methods still struggle with precise mesh reconstruction. We address this gap by jointly learning an explicit VD with an implicit Signed Distance Field (SDF). The scene is optimized via ray tracing and regularized by an Eikonal objective. The SDF introduces metric-consistent isosurfaces, which, in turn, bias near-surface Voronoi cell faces to align with the zero level set. The resulting model produces crisper, view-consistent surfaces with fewer floaters and improved topology, while preserving photometric quality and maintaining training speed on par with RadiantFoam. Across diverse scenes, our hybrid implicit-explicit formulation, which we name SDFoam, substantially improves mesh reconstruction accuracy (Chamfer distance) with comparable appearance (PSNR, SSIM), without sacrificing efficiency.
Lagrangian Hashing for Compressed Neural Field Representations
Sep 09, 2024



We present Lagrangian Hashing, a representation for neural fields combining the characteristics of fast training NeRF methods that rely on Eulerian grids (i.e.~InstantNGP), with those that employ points equipped with features as a way to represent information (e.g. 3D Gaussian Splatting or PointNeRF). We achieve this by incorporating a point-based representation into the high-resolution layers of the hierarchical hash tables of an InstantNGP representation. As our points are equipped with a field of influence, our representation can be interpreted as a mixture of Gaussians stored within the hash table. We propose a loss that encourages the movement of our Gaussians towards regions that require more representation budget to be sufficiently well represented. Our main finding is that our representation allows the reconstruction of signals using a more compact representation without compromising quality.
A Unified Simulation Framework for Visual and Behavioral Fidelity in Crowd Analysis
Dec 05, 2023


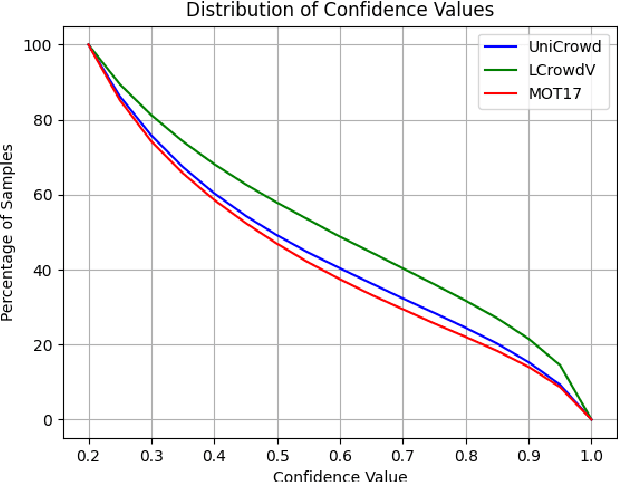
Simulation is a powerful tool to easily generate annotated data, and a highly desirable feature, especially in those domains where learning models need large training datasets. Machine learning and deep learning solutions, have proven to be extremely data-hungry and sometimes, the available real-world data are not sufficient to effectively model the given task. Despite the initial skepticism of a portion of the scientific community, the potential of simulation has been largely confirmed in many application areas, and the recent developments in terms of rendering and virtualization engines, have shown a good ability also in representing complex scenes. This includes environmental factors, such as weather conditions and surface reflectance, as well as human-related events, like human actions and behaviors. We present a human crowd simulator, called UniCrowd, and its associated validation pipeline. We show how the simulator can generate annotated data, suitable for computer vision tasks, in particular for detection and segmentation, as well as the related applications, as crowd counting, human pose estimation, trajectory analysis and prediction, and anomaly detection.
Capsules as viewpoint learners for human pose estimation
Feb 13, 2023The task of human pose estimation (HPE) deals with the ill-posed problem of estimating the 3D position of human joints directly from images and videos. In recent literature, most of the works tackle the problem mostly by using convolutional neural networks (CNNs), which are capable of achieving state-of-the-art results in most datasets. We show how most neural networks are not able to generalize well when the camera is subject to significant viewpoint changes. This behaviour emerges because CNNs lack the capability of modelling viewpoint equivariance, while they rather rely on viewpoint invariance, resulting in high data dependency. Recently, capsule networks (CapsNets) have been proposed in the multi-class classification field as a solution to the viewpoint equivariance issue, reducing both the size and complexity of both the training datasets and the network itself. In this work, we show how capsule networks can be adopted to achieve viewpoint equivariance in human pose estimation. We propose a novel end-to-end viewpoint-equivariant capsule autoencoder that employs a fast Variational Bayes routing and matrix capsules. We achieve state-of-the-art results for multiple tasks and datasets while retaining other desirable properties, such as greater generalization capabilities when changing viewpoints, lower data dependency and fast inference. Additionally, by modelling each joint as a capsule, the hierarchical and geometrical structure of the overall pose is retained in the feature space, independently from the viewpoint. We further test our network on multiple datasets, both in the RGB and depth domain, from seen and unseen viewpoints and in the viewpoint transfer task.
Interpretable part-whole hierarchies and conceptual-semantic relationships in neural networks
Mar 07, 2022
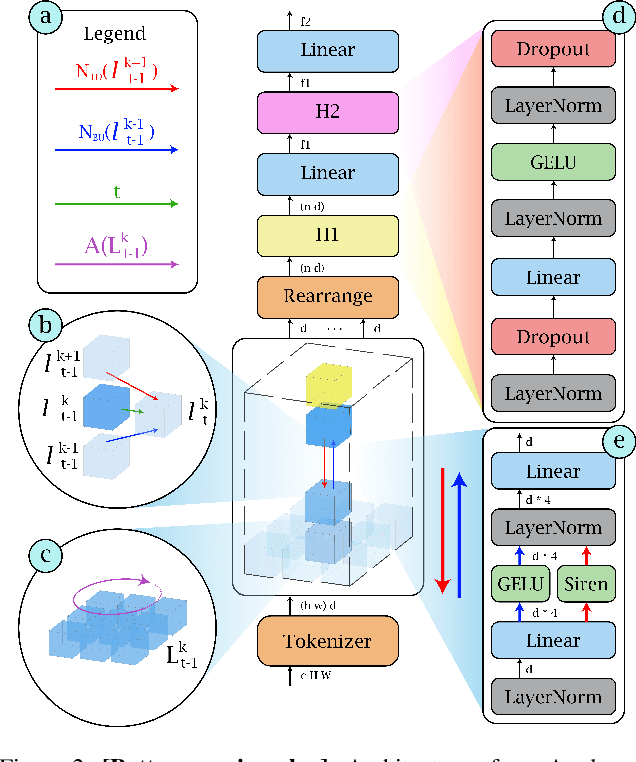
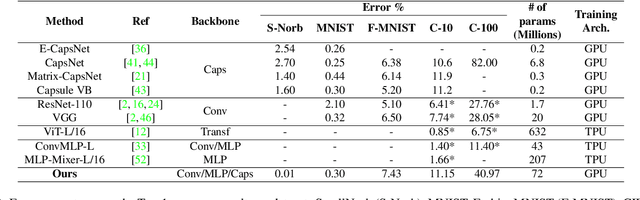
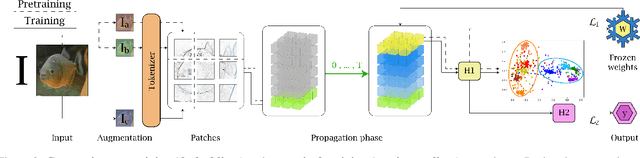
Deep neural networks achieve outstanding results in a large variety of tasks, often outperforming human experts. However, a known limitation of current neural architectures is the poor accessibility to understand and interpret the network response to a given input. This is directly related to the huge number of variables and the associated non-linearities of neural models, which are often used as black boxes. When it comes to critical applications as autonomous driving, security and safety, medicine and health, the lack of interpretability of the network behavior tends to induce skepticism and limited trustworthiness, despite the accurate performance of such systems in the given task. Furthermore, a single metric, such as the classification accuracy, provides a non-exhaustive evaluation of most real-world scenarios. In this paper, we want to make a step forward towards interpretability in neural networks, providing new tools to interpret their behavior. We present Agglomerator, a framework capable of providing a representation of part-whole hierarchies from visual cues and organizing the input distribution matching the conceptual-semantic hierarchical structure between classes. We evaluate our method on common datasets, such as SmallNORB, MNIST, FashionMNIST, CIFAR-10, and CIFAR-100, providing a more interpretable model than other state-of-the-art approaches.
Visual Sentiment Analysis: A Natural DisasterUse-case Task at MediaEval 2021
Nov 22, 2021The Visual Sentiment Analysis task is being offered for the first time at MediaEval. The main purpose of the task is to predict the emotional response to images of natural disasters shared on social media. Disaster-related images are generally complex and often evoke an emotional response, making them an ideal use case of visual sentiment analysis. We believe being able to perform meaningful analysis of natural disaster-related data could be of great societal importance, and a joint effort in this regard can open several interesting directions for future research. The task is composed of three sub-tasks, each aiming to explore a different aspect of the challenge. In this paper, we provide a detailed overview of the task, the general motivation of the task, and an overview of the dataset and the metrics to be used for the evaluation of the proposed solutions.
DECA: Deep viewpoint-Equivariant human pose estimation using Capsule Autoencoders
Aug 19, 2021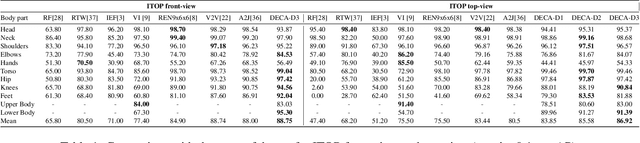
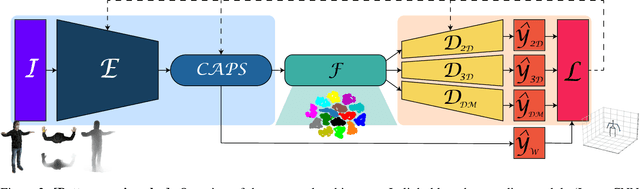
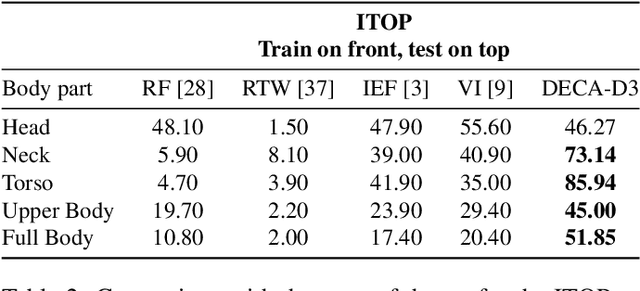
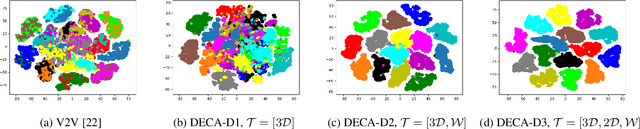
Human Pose Estimation (HPE) aims at retrieving the 3D position of human joints from images or videos. We show that current 3D HPE methods suffer a lack of viewpoint equivariance, namely they tend to fail or perform poorly when dealing with viewpoints unseen at training time. Deep learning methods often rely on either scale-invariant, translation-invariant, or rotation-invariant operations, such as max-pooling. However, the adoption of such procedures does not necessarily improve viewpoint generalization, rather leading to more data-dependent methods. To tackle this issue, we propose a novel capsule autoencoder network with fast Variational Bayes capsule routing, named DECA. By modeling each joint as a capsule entity, combined with the routing algorithm, our approach can preserve the joints' hierarchical and geometrical structure in the feature space, independently from the viewpoint. By achieving viewpoint equivariance, we drastically reduce the network data dependency at training time, resulting in an improved ability to generalize for unseen viewpoints. In the experimental validation, we outperform other methods on depth images from both seen and unseen viewpoints, both top-view, and front-view. In the RGB domain, the same network gives state-of-the-art results on the challenging viewpoint transfer task, also establishing a new framework for top-view HPE. The code can be found at https://github.com/mmlab-cv/DECA.
Flood Detection via Twitter Streams using Textual and Visual Features
Nov 30, 2020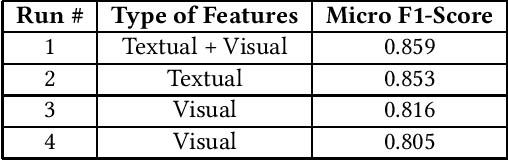
The paper presents our proposed solutions for the MediaEval 2020 Flood-Related Multimedia Task, which aims to analyze and detect flooding events in multimedia content shared over Twitter. In total, we proposed four different solutions including a multi-modal solution combining textual and visual information for the mandatory run, and three single modal image and text-based solutions as optional runs. In the multimodal method, we rely on a supervised multimodal bitransformer model that combines textual and visual features in an early fusion, achieving a micro F1-score of .859 on the development data set. For the text-based flood events detection, we use a transformer network (i.e., pretrained Italian BERT model) achieving an F1-score of .853. For image-based solutions, we employed multiple deep models, pre-trained on both, the ImageNet and places data sets, individually and combined in an early fusion achieving F1-scores of .816 and .805 on the development set, respectively.
Visual Sentiment Analysis from Disaster Images in Social Media
Sep 04, 2020


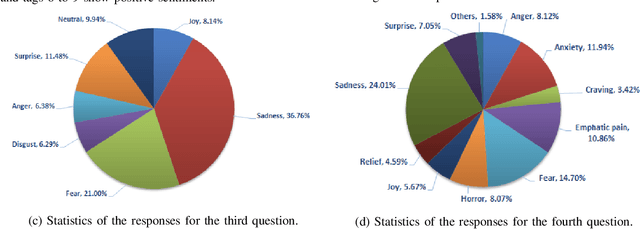
The increasing popularity of social networks and users' tendency towards sharing their feelings, expressions, and opinions in text, visual, and audio content, have opened new opportunities and challenges in sentiment analysis. While sentiment analysis of text streams has been widely explored in literature, sentiment analysis from images and videos is relatively new. This article focuses on visual sentiment analysis in a societal important domain, namely disaster analysis in social media. To this aim, we propose a deep visual sentiment analyzer for disaster related images, covering different aspects of visual sentiment analysis starting from data collection, annotation, model selection, implementation, and evaluations. For data annotation, and analyzing peoples' sentiments towards natural disasters and associated images in social media, a crowd-sourcing study has been conducted with a large number of participants worldwide. The crowd-sourcing study resulted in a large-scale benchmark dataset with four different sets of annotations, each aiming a separate task. The presented analysis and the associated dataset will provide a baseline/benchmark for future research in the domain. We believe the proposed system can contribute toward more livable communities by helping different stakeholders, such as news broadcasters, humanitarian organizations, as well as the general public.
Deriving Emotions and Sentiments from Visual Content: A Disaster Analysis Use Case
Feb 03, 2020
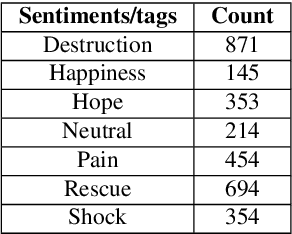


Sentiment analysis aims to extract and express a person's perception, opinions and emotions towards an entity, object, product and a service, enabling businesses to obtain feedback from the consumers. The increasing popularity of the social networks and users' tendency towards sharing their feelings, expressions and opinions in text, visual and audio content has opened new opportunities and challenges in sentiment analysis. While sentiment analysis of text streams has been widely explored in the literature, sentiment analysis of images and videos is relatively new. This article introduces visual sentiment analysis and contrasts it with textual sentiment analysis with emphasis on the opportunities and challenges in this nascent research area. We also propose a deep visual sentiment analyzer for disaster-related images as a use-case, covering different aspects of visual sentiment analysis starting from data collection, annotation, model selection, implementation and evaluations. We believe such rigorous analysis will provide a baseline for future research in the domain.