 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Graph Foundation Models for Dynamics in Complex Networked Systems: Lessons from Super-Spreader Identification in Multilayer Networks
Jun 06, 2026Network dynamics - including spreading, influence maximisation, and epidemic modelling - remain largely confined to the transductive paradigm, where models are trained on a single network and cannot be reused on unseen graphs without retraining. We argue that inductive cross-network generalisation is a necessary prerequisite for Graph Foundation Models (GFMs) in this domain and propose four design properties towards this goal. As a proof of concept, ts-net (TopSpreadersNetwork), trained solely on synthetic multilayer networks (MLNs), demonstrates zero-shot generalisation to real-world MLNs of varying size and layer count, outperforming classical heuristics and transductive baselines on three of four metrics. Based on ts-net's performance, we further outline five open challenges towards building GFMs for network dynamics: scale, many-layer generalisation, self-supervised pretraining, cross-task transfer, and node-attribute integration.
Twinning Complex Networked Systems: Data-Driven Calibration of the mABCD Synthetic Graph Generator
Feb 02, 2026The increasing availability of relational data has contributed to a growing reliance on network-based representations of complex systems. Over time, these models have evolved to capture more nuanced properties, such as the heterogeneity of relationships, leading to the concept of multilayer networks. However, the analysis and evaluation of methods for these structures is often hindered by the limited availability of large-scale empirical data. As a result, graph generators are commonly used as a workaround, albeit at the cost of introducing systematic biases. In this paper, we address the inverse-generator problem by inferring the configuration parameters of a multilayer network generator, mABCD, from a real-world system. Our goal is to identify parameter settings that enable the generator to produce synthetic networks that act as digital twins of the original structure. We propose a method for estimating matching configurations and for quantifying the associated error. Our results demonstrate that this task is non-trivial, as strong interdependencies between configuration parameters weaken independent estimation and instead favour a joint-prediction approach.
Identifying Super Spreaders in Multilayer Networks
May 27, 2025
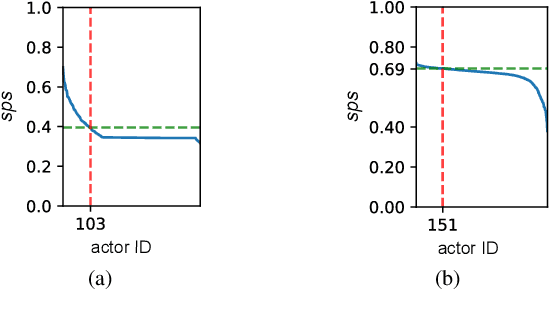

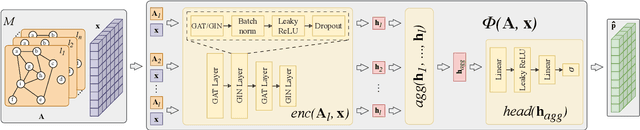
Identifying super-spreaders can be framed as a subtask of the influence maximisation problem. It seeks to pinpoint agents within a network that, if selected as single diffusion seeds, disseminate information most effectively. Multilayer networks, a specific class of heterogeneous graphs, can capture diverse types of interactions (e.g., physical-virtual or professional-social), and thus offer a more accurate representation of complex relational structures. In this work, we introduce a novel approach to identifying super-spreaders in such networks by leveraging graph neural networks. To this end, we construct a dataset by simulating information diffusion across hundreds of networks - to the best of our knowledge, the first of its kind tailored specifically to multilayer networks. We further formulate the task as a variation of the ranking prediction problem based on a four-dimensional vector that quantifies each agent's spreading potential: (i) the number of activations; (ii) the duration of the diffusion process; (iii) the peak number of activations; and (iv) the simulation step at which this peak occurs. Our model, TopSpreadersNetwork, comprises a relationship-agnostic encoder and a custom aggregation layer. This design enables generalisation to previously unseen data and adapts to varying graph sizes. In an extensive evaluation, we compare our model against classic centrality-based heuristics and competitive deep learning methods. The results, obtained across a broad spectrum of real-world and synthetic multilayer networks, demonstrate that TopSpreadersNetwork achieves superior performance in identifying high-impact nodes, while also offering improved interpretability through its structured output.
Identifying Key Nodes for the Influence Spread using a Machine Learning Approach
Dec 02, 2024The identification of key nodes in complex networks is an important topic in many network science areas. It is vital to a variety of real-world applications, including viral marketing, epidemic spreading and influence maximization. In recent years, machine learning algorithms have proven to outperform the conventional, centrality-based methods in accuracy and consistency, but this approach still requires further refinement. What information about the influencers can be extracted from the network? How can we precisely obtain the labels required for training? Can these models generalize well? In this paper, we answer these questions by presenting an enhanced machine learning-based framework for the influence spread problem. We focus on identifying key nodes for the Independent Cascade model, which is a popular reference method. Our main contribution is an improved process of obtaining the labels required for training by introducing 'Smart Bins' and proving their advantage over known methods. Next, we show that our methodology allows ML models to not only predict the influence of a given node, but to also determine other characteristics of the spreading process-which is another novelty to the relevant literature. Finally, we extensively test our framework and its ability to generalize beyond complex networks of different types and sizes, gaining important insight into the properties of these methods.
DECA: Deep viewpoint-Equivariant human pose estimation using Capsule Autoencoders
Aug 19, 2021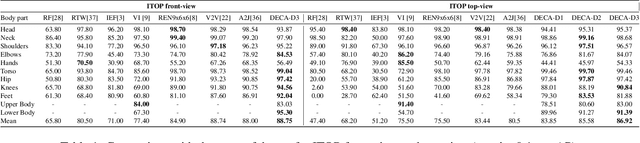
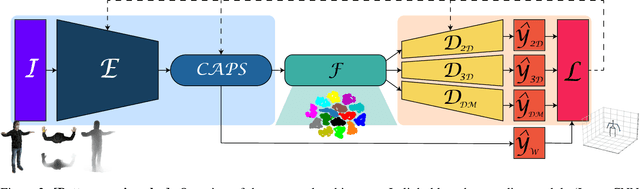
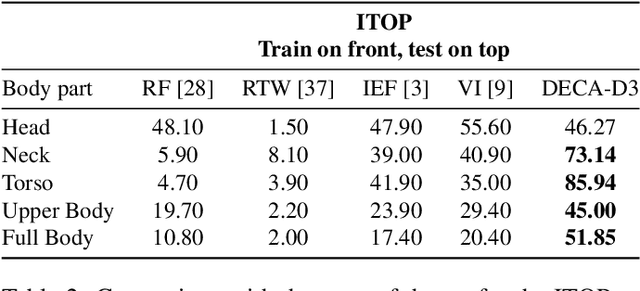
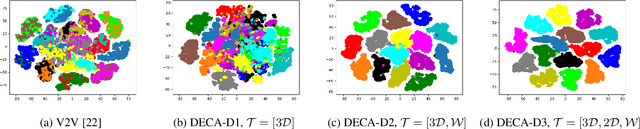
Human Pose Estimation (HPE) aims at retrieving the 3D position of human joints from images or videos. We show that current 3D HPE methods suffer a lack of viewpoint equivariance, namely they tend to fail or perform poorly when dealing with viewpoints unseen at training time. Deep learning methods often rely on either scale-invariant, translation-invariant, or rotation-invariant operations, such as max-pooling. However, the adoption of such procedures does not necessarily improve viewpoint generalization, rather leading to more data-dependent methods. To tackle this issue, we propose a novel capsule autoencoder network with fast Variational Bayes capsule routing, named DECA. By modeling each joint as a capsule entity, combined with the routing algorithm, our approach can preserve the joints' hierarchical and geometrical structure in the feature space, independently from the viewpoint. By achieving viewpoint equivariance, we drastically reduce the network data dependency at training time, resulting in an improved ability to generalize for unseen viewpoints. In the experimental validation, we outperform other methods on depth images from both seen and unseen viewpoints, both top-view, and front-view. In the RGB domain, the same network gives state-of-the-art results on the challenging viewpoint transfer task, also establishing a new framework for top-view HPE. The code can be found at https://github.com/mmlab-cv/DECA.