 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Reduction in Multirelational Networks: A Spreading-Oriented Reduction Benchmark
Jun 10, 2026Real-world networks are inherently incomplete, noisy, and dynamically evolving, making it difficult to capture all actors and their relationships. Their scale often renders direct analysis computationally demanding. While influence maximisation (IM) has been widely studied, the role of graph reduction as a preprocessing step, and its impact on IM accuracy, remains underexplored. In this work, we introduce the Spreading-Oriented Reduction Benchmark (SORB), an open-source, standardised framework for systematically evaluating IM models across diverse task settings. SORB provides an extensible pipeline operating on a representative collection of real-world networks, including single- and multilayer structures, and accounts for graph reduction directly into the evaluation process. This design shifts the focus from analysing IM algorithms in isolation to quantifying how graph reduction alters predictive performance. Using SORB, we study the effects of sparsification and coarsening across multiple IM scenarios. Our results show that the impact of reduction is strongly dependent on both the network type (single-layer vs. multirelational) and the downstream task ($Gain@k$ vs. $\mathrm{AUC}_{\mathrm{cutoff}}$): sparsification preserves seed set quality on single-layer networks, whereas flattened multilayer networks exhibit systematic ranking degradation regardless of reduction strategy. These findings highlight the importance of reduction-aware, multi-task evaluation when studying spreading processes in complex networks.
Towards Graph Foundation Models for Dynamics in Complex Networked Systems: Lessons from Super-Spreader Identification in Multilayer Networks
Jun 06, 2026Network dynamics - including spreading, influence maximisation, and epidemic modelling - remain largely confined to the transductive paradigm, where models are trained on a single network and cannot be reused on unseen graphs without retraining. We argue that inductive cross-network generalisation is a necessary prerequisite for Graph Foundation Models (GFMs) in this domain and propose four design properties towards this goal. As a proof of concept, ts-net (TopSpreadersNetwork), trained solely on synthetic multilayer networks (MLNs), demonstrates zero-shot generalisation to real-world MLNs of varying size and layer count, outperforming classical heuristics and transductive baselines on three of four metrics. Based on ts-net's performance, we further outline five open challenges towards building GFMs for network dynamics: scale, many-layer generalisation, self-supervised pretraining, cross-task transfer, and node-attribute integration.
KG-Guard: Graph-Based Hallucination Detection for Knowledge Base Question Answering
May 29, 2026Large language models (LLMs) are increasingly used for knowledge base question answering (KBQA), where answering requires selecting entities from a question-specific knowledge-graph subgraph. Yet LLMs are known to hallucinate across tasks, and KBQA is no exception: even when we provide a graph as the knowledge source, the model may rely on parametric knowledge instead of graph evidence or perform invalid reasoning over the given relations. Such hallucinated answer nodes can limit the practical deployment of KBQA systems, especially in high-stakes domains such as healthcare. We formulate hallucination detection in KBQA as an answer-node classification problem and propose a lightweight graph-based framework that treats the answering LLM as a black box. \methodname represents each KBQA instance as an augmented graph. It initializes node features with semantic representations of KG entities, marks topic entities and LLM-proposed answer nodes with learned vectors, and connect a virtual question node to the topic entities. A graph encoder then produces verification-oriented node representations, and a small MLP classifies each proposed answer node using its graph representation together with the question embedding. Experiments on WebQSP, ComplexWebQuestions, and PUGG show that our detector achieves the highest F1 on all three benchmarks ($82.0$, $87.4$, and $84.3$), outperforming LLM-as-judge and sampling-based baselines, while having $\sim305\times$ fewer parameters than the reference approaches. Beyond detection, the node-level feedback is actionable: when flagged answers are fed back to the KBQA system for iterative refinement, downstream KBQA F1 improves by $13.0$--$14.5$ points and Exact Match by $16.9$--$17.6$ points.
Identifying Super Spreaders in Multilayer Networks
May 27, 2025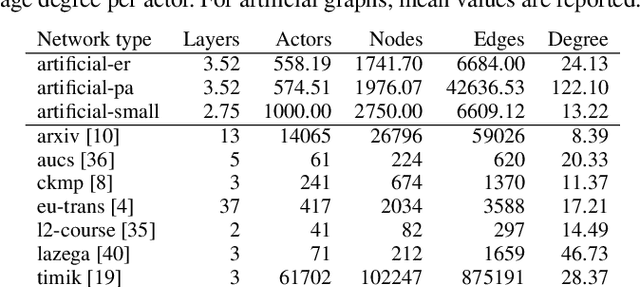
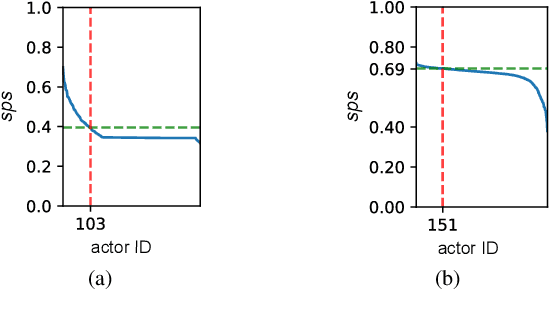

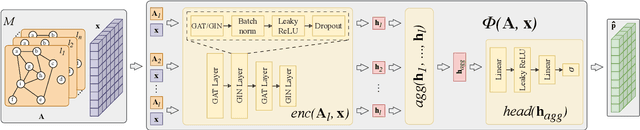
Identifying super-spreaders can be framed as a subtask of the influence maximisation problem. It seeks to pinpoint agents within a network that, if selected as single diffusion seeds, disseminate information most effectively. Multilayer networks, a specific class of heterogeneous graphs, can capture diverse types of interactions (e.g., physical-virtual or professional-social), and thus offer a more accurate representation of complex relational structures. In this work, we introduce a novel approach to identifying super-spreaders in such networks by leveraging graph neural networks. To this end, we construct a dataset by simulating information diffusion across hundreds of networks - to the best of our knowledge, the first of its kind tailored specifically to multilayer networks. We further formulate the task as a variation of the ranking prediction problem based on a four-dimensional vector that quantifies each agent's spreading potential: (i) the number of activations; (ii) the duration of the diffusion process; (iii) the peak number of activations; and (iv) the simulation step at which this peak occurs. Our model, TopSpreadersNetwork, comprises a relationship-agnostic encoder and a custom aggregation layer. This design enables generalisation to previously unseen data and adapts to varying graph sizes. In an extensive evaluation, we compare our model against classic centrality-based heuristics and competitive deep learning methods. The results, obtained across a broad spectrum of real-world and synthetic multilayer networks, demonstrate that TopSpreadersNetwork achieves superior performance in identifying high-impact nodes, while also offering improved interpretability through its structured output.
Empowering Small-Scale Knowledge Graphs: A Strategy of Leveraging General-Purpose Knowledge Graphs for Enriched Embeddings
May 17, 2024



Knowledge-intensive tasks pose a significant challenge for Machine Learning (ML) techniques. Commonly adopted methods, such as Large Language Models (LLMs), often exhibit limitations when applied to such tasks. Nevertheless, there have been notable endeavours to mitigate these challenges, with a significant emphasis on augmenting LLMs through Knowledge Graphs (KGs). While KGs provide many advantages for representing knowledge, their development costs can deter extensive research and applications. Addressing this limitation, we introduce a framework for enriching embeddings of small-scale domain-specific Knowledge Graphs with well-established general-purpose KGs. Adopting our method, a modest domain-specific KG can benefit from a performance boost in downstream tasks when linked to a substantial general-purpose KG. Experimental evaluations demonstrate a notable enhancement, with up to a 44% increase observed in the Hits@10 metric. This relatively unexplored research direction can catalyze more frequent incorporation of KGs in knowledge-intensive tasks, resulting in more robust, reliable ML implementations, which hallucinates less than prevalent LLM solutions. Keywords: knowledge graph, knowledge graph completion, entity alignment, representation learning, machine learning
Representation learning in multiplex graphs: Where and how to fuse information?
Feb 27, 2024

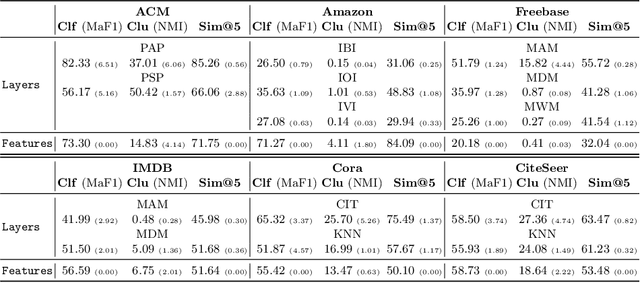

In recent years, unsupervised and self-supervised graph representation learning has gained popularity in the research community. However, most proposed methods are focused on homogeneous networks, whereas real-world graphs often contain multiple node and edge types. Multiplex graphs, a special type of heterogeneous graphs, possess richer information, provide better modeling capabilities and integrate more detailed data from potentially different sources. The diverse edge types in multiplex graphs provide more context and insights into the underlying processes of representation learning. In this paper, we tackle the problem of learning representations for nodes in multiplex networks in an unsupervised or self-supervised manner. To that end, we explore diverse information fusion schemes performed at different levels of the graph processing pipeline. The detailed analysis and experimental evaluation of various scenarios inspired us to propose improvements in how to construct GNN architectures that deal with multiplex graphs.
Unveiling the Potential of Probabilistic Embeddings in Self-Supervised Learning
Oct 27, 2023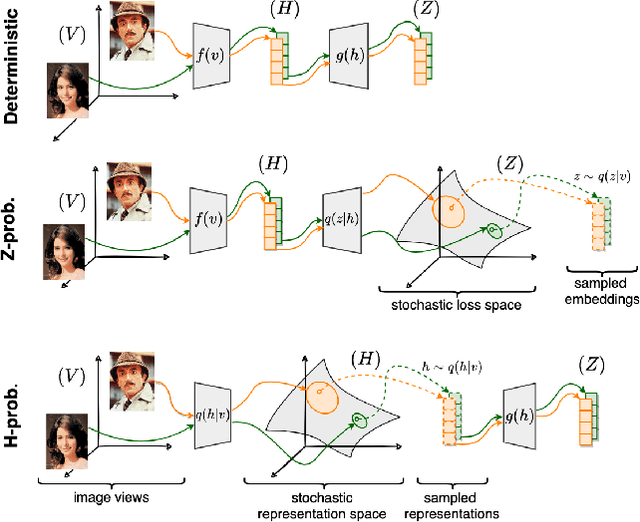
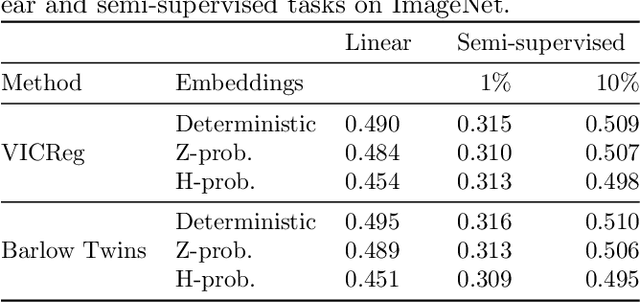
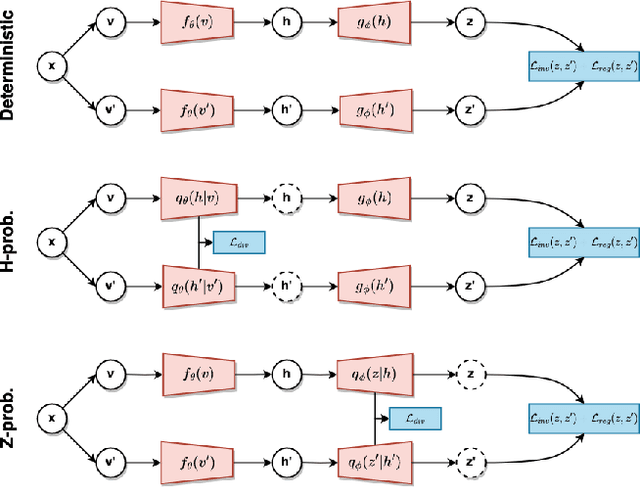
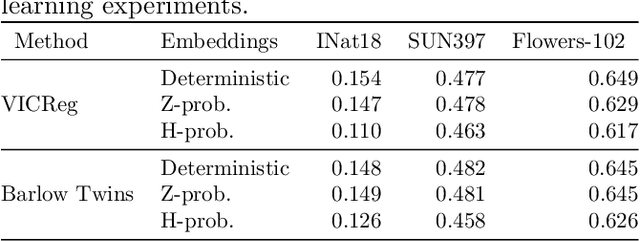
In recent years, self-supervised learning has played a pivotal role in advancing machine learning by allowing models to acquire meaningful representations from unlabeled data. An intriguing research avenue involves developing self-supervised models within an information-theoretic framework, but many studies often deviate from the stochasticity assumptions made when deriving their objectives. To gain deeper insights into this issue, we propose to explicitly model the representation with stochastic embeddings and assess their effects on performance, information compression and potential for out-of-distribution detection. From an information-theoretic perspective, we seek to investigate the impact of probabilistic modeling on the information bottleneck, shedding light on a trade-off between compression and preservation of information in both representation and loss space. Emphasizing the importance of distinguishing between these two spaces, we demonstrate how constraining one can affect the other, potentially leading to performance degradation. Moreover, our findings suggest that introducing an additional bottleneck in the loss space can significantly enhance the ability to detect out-of-distribution examples, only leveraging either representation features or the variance of their underlying distribution.
Graph-level representations using ensemble-based readout functions
Mar 03, 2023


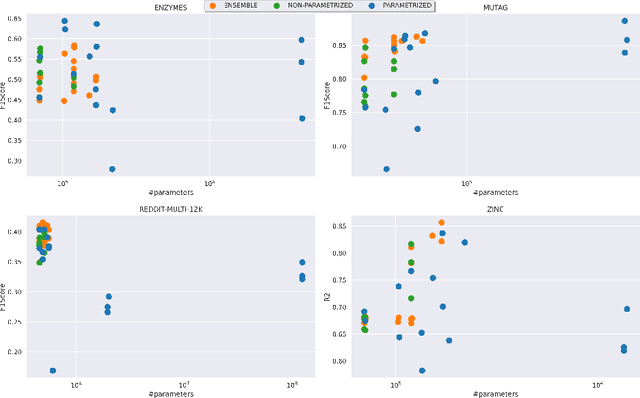
Graph machine learning models have been successfully deployed in a variety of application areas. One of the most prominent types of models - Graph Neural Networks (GNNs) - provides an elegant way of extracting expressive node-level representation vectors, which can be used to solve node-related problems, such as classifying users in a social network. However, many tasks require representations at the level of the whole graph, e.g., molecular applications. In order to convert node-level representations into a graph-level vector, a so-called readout function must be applied. In this work, we study existing readout methods, including simple non-trainable ones, as well as complex, parametrized models. We introduce a concept of ensemble-based readout functions that combine either representations or predictions. Our experiments show that such ensembles allow for better performance than simple single readouts or similar performance as the complex, parametrized ones, but at a fraction of the model complexity.
RAFEN -- Regularized Alignment Framework for Embeddings of Nodes
Mar 03, 2023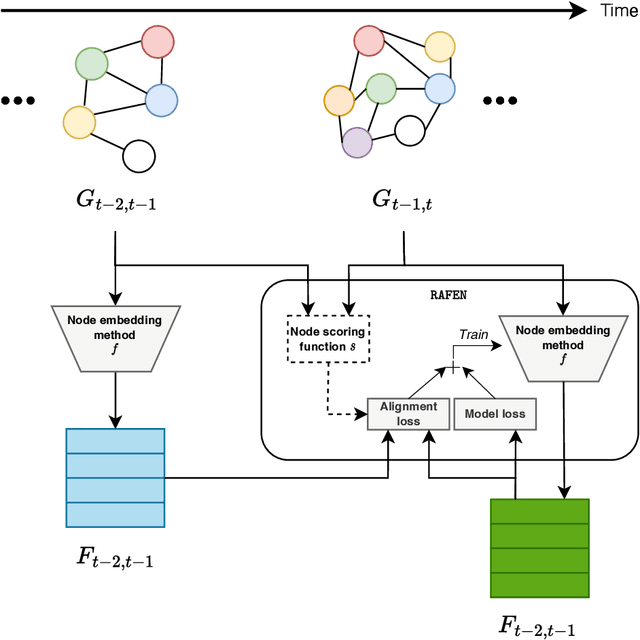
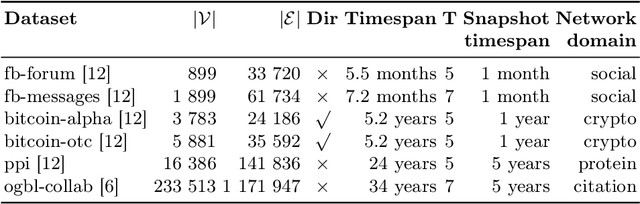
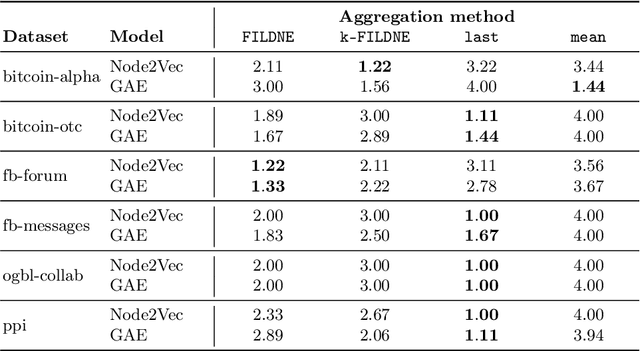
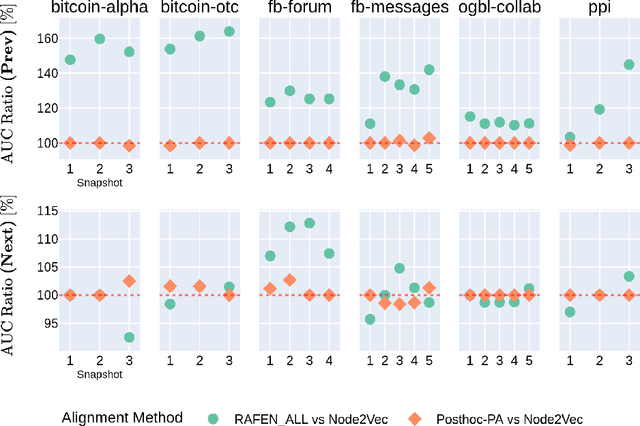
Learning representations of nodes has been a crucial area of the graph machine learning research area. A well-defined node embedding model should reflect both node features and the graph structure in the final embedding. In the case of dynamic graphs, this problem becomes even more complex as both features and structure may change over time. The embeddings of particular nodes should remain comparable during the evolution of the graph, what can be achieved by applying an alignment procedure. This step was often applied in existing works after the node embedding was already computed. In this paper, we introduce a framework -- RAFEN -- that allows to enrich any existing node embedding method using the aforementioned alignment term and learning aligned node embedding during training time. We propose several variants of our framework and demonstrate its performance on six real-world datasets. RAFEN achieves on-par or better performance than existing approaches without requiring additional processing steps.
On Graph Neural Network Ensembles for Large-Scale Molecular Property Prediction
Jun 29, 2021
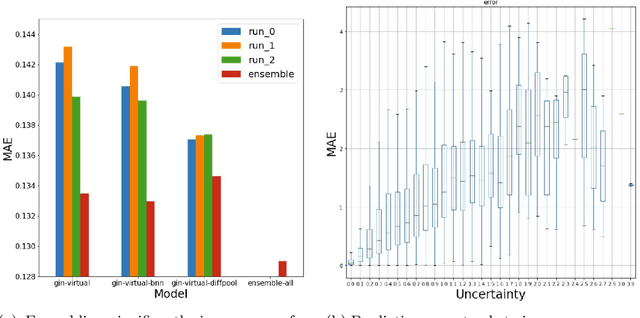
In order to advance large-scale graph machine learning, the Open Graph Benchmark Large Scale Challenge (OGB-LSC) was proposed at the KDD Cup 2021. The PCQM4M-LSC dataset defines a molecular HOMO-LUMO property prediction task on about 3.8M graphs. In this short paper, we show our current work-in-progress solution which builds an ensemble of three graph neural networks models based on GIN, Bayesian Neural Networks and DiffPool. Our approach outperforms the provided baseline by 7.6%. Moreover, using uncertainty in our ensemble's prediction, we can identify molecules whose HOMO-LUMO gaps are harder to predict (with Pearson's correlation of 0.5181). We anticipate that this will facilitate active learning.