 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Sinks as Internal Signals for Hallucination Detection in Large Language Models
Apr 12, 2026Large language models frequently exhibit hallucinations: fluent and confident outputs that are factually incorrect or unsupported by the input context. While recent hallucination detection methods have explored various features derived from attention maps, the underlying mechanisms they exploit remain poorly understood. In this work, we propose SinkProbe, a hallucination detection method grounded in the observation that hallucinations are deeply entangled with attention sinks - tokens that accumulate disproportionate attention mass during generation - indicating a transition from distributed, input-grounded attention to compressed, prior-dominated computation. Importantly, although sink scores are computed solely from attention maps, we find that the classifier preferentially relies on sinks whose associated value vectors have large norms. Moreover, we show that previous methods implicitly depend on attention sinks by establishing their mathematical relationship to sink scores. Our findings yield a novel hallucination detection method grounded in theory that produces state-of-the-art results across popular datasets and LLMs.
FactSelfCheck: Fact-Level Black-Box Hallucination Detection for LLMs
Mar 21, 2025



Large Language Models (LLMs) frequently generate hallucinated content, posing significant challenges for applications where factuality is crucial. While existing hallucination detection methods typically operate at the sentence level or passage level, we propose FactSelfCheck, a novel black-box sampling-based method that enables fine-grained fact-level detection. Our approach represents text as knowledge graphs consisting of facts in the form of triples. Through analyzing factual consistency across multiple LLM responses, we compute fine-grained hallucination scores without requiring external resources or training data. Our evaluation demonstrates that FactSelfCheck performs competitively with leading sampling-based methods while providing more detailed insights. Most notably, our fact-level approach significantly improves hallucination correction, achieving a 35% increase in factual content compared to the baseline, while sentence-level SelfCheckGPT yields only an 8% improvement. The granular nature of our detection enables more precise identification and correction of hallucinated content.
Hallucination Detection in LLMs Using Spectral Features of Attention Maps
Feb 24, 2025


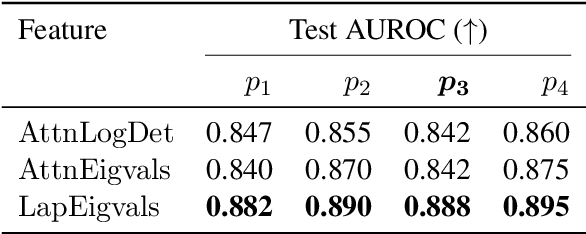
Large Language Models (LLMs) have demonstrated remarkable performance across various tasks but remain prone to hallucinations. Detecting hallucinations is essential for safety-critical applications, and recent methods leverage attention map properties to this end, though their effectiveness remains limited. In this work, we investigate the spectral features of attention maps by interpreting them as adjacency matrices of graph structures. We propose the $\text{LapEigvals}$ method, which utilises the top-$k$ eigenvalues of the Laplacian matrix derived from the attention maps as an input to hallucination detection probes. Empirical evaluations demonstrate that our approach achieves state-of-the-art hallucination detection performance among attention-based methods. Extensive ablation studies further highlight the robustness and generalisation of $\text{LapEigvals}$, paving the way for future advancements in the hallucination detection domain.
Empowering Small-Scale Knowledge Graphs: A Strategy of Leveraging General-Purpose Knowledge Graphs for Enriched Embeddings
May 17, 2024



Knowledge-intensive tasks pose a significant challenge for Machine Learning (ML) techniques. Commonly adopted methods, such as Large Language Models (LLMs), often exhibit limitations when applied to such tasks. Nevertheless, there have been notable endeavours to mitigate these challenges, with a significant emphasis on augmenting LLMs through Knowledge Graphs (KGs). While KGs provide many advantages for representing knowledge, their development costs can deter extensive research and applications. Addressing this limitation, we introduce a framework for enriching embeddings of small-scale domain-specific Knowledge Graphs with well-established general-purpose KGs. Adopting our method, a modest domain-specific KG can benefit from a performance boost in downstream tasks when linked to a substantial general-purpose KG. Experimental evaluations demonstrate a notable enhancement, with up to a 44% increase observed in the Hits@10 metric. This relatively unexplored research direction can catalyze more frequent incorporation of KGs in knowledge-intensive tasks, resulting in more robust, reliable ML implementations, which hallucinates less than prevalent LLM solutions. Keywords: knowledge graph, knowledge graph completion, entity alignment, representation learning, machine learning
Unveiling the Potential of Probabilistic Embeddings in Self-Supervised Learning
Oct 27, 2023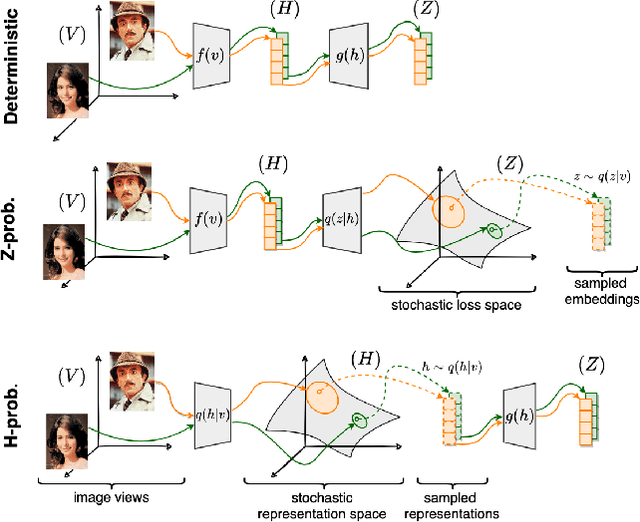
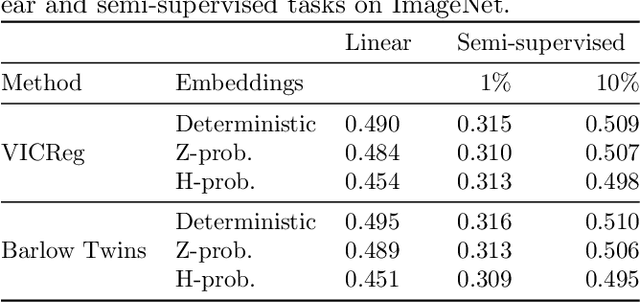
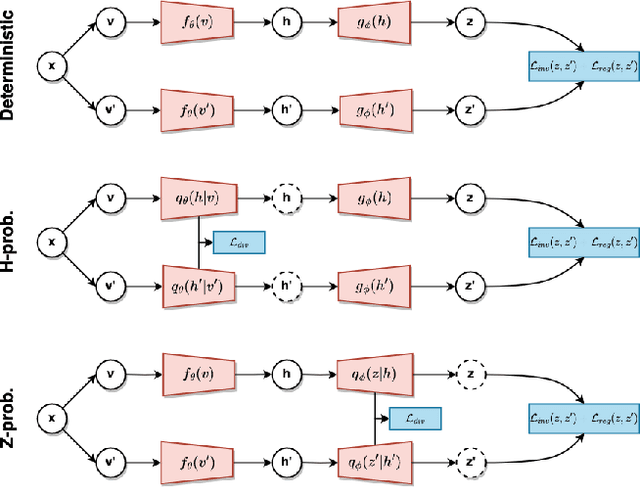
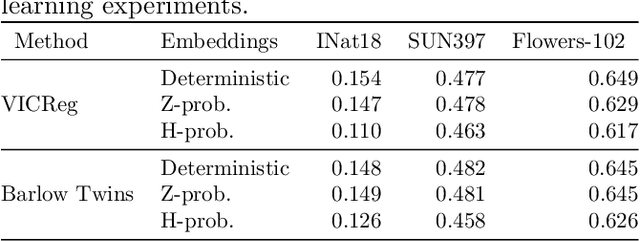
In recent years, self-supervised learning has played a pivotal role in advancing machine learning by allowing models to acquire meaningful representations from unlabeled data. An intriguing research avenue involves developing self-supervised models within an information-theoretic framework, but many studies often deviate from the stochasticity assumptions made when deriving their objectives. To gain deeper insights into this issue, we propose to explicitly model the representation with stochastic embeddings and assess their effects on performance, information compression and potential for out-of-distribution detection. From an information-theoretic perspective, we seek to investigate the impact of probabilistic modeling on the information bottleneck, shedding light on a trade-off between compression and preservation of information in both representation and loss space. Emphasizing the importance of distinguishing between these two spaces, we demonstrate how constraining one can affect the other, potentially leading to performance degradation. Moreover, our findings suggest that introducing an additional bottleneck in the loss space can significantly enhance the ability to detect out-of-distribution examples, only leveraging either representation features or the variance of their underlying distribution.
Graph-level representations using ensemble-based readout functions
Mar 03, 2023


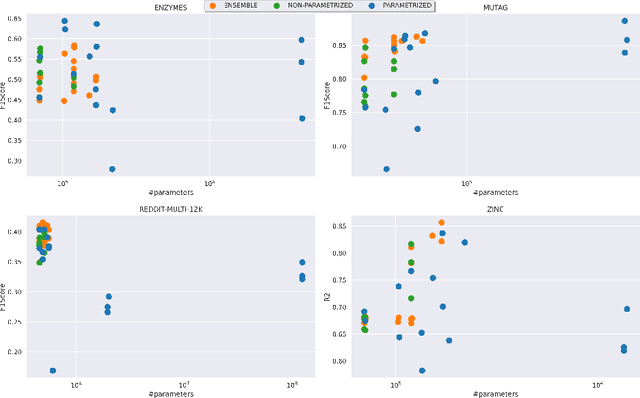
Graph machine learning models have been successfully deployed in a variety of application areas. One of the most prominent types of models - Graph Neural Networks (GNNs) - provides an elegant way of extracting expressive node-level representation vectors, which can be used to solve node-related problems, such as classifying users in a social network. However, many tasks require representations at the level of the whole graph, e.g., molecular applications. In order to convert node-level representations into a graph-level vector, a so-called readout function must be applied. In this work, we study existing readout methods, including simple non-trainable ones, as well as complex, parametrized models. We introduce a concept of ensemble-based readout functions that combine either representations or predictions. Our experiments show that such ensembles allow for better performance than simple single readouts or similar performance as the complex, parametrized ones, but at a fraction of the model complexity.
RAFEN -- Regularized Alignment Framework for Embeddings of Nodes
Mar 03, 2023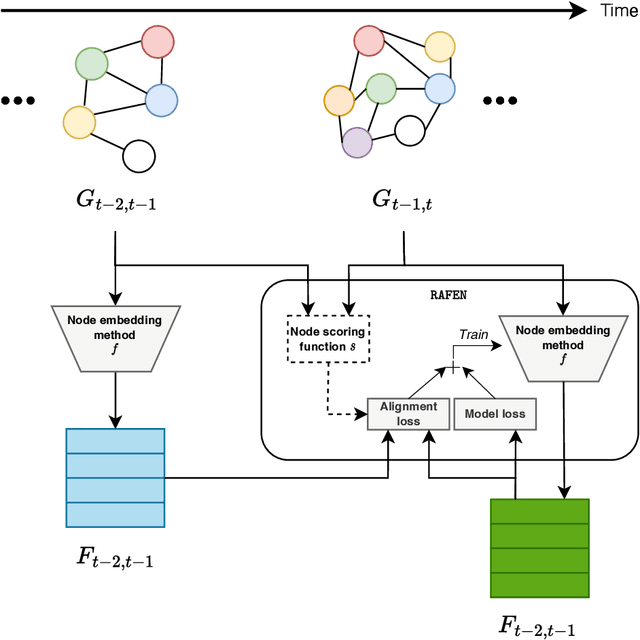
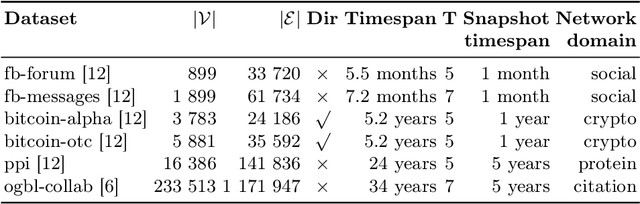
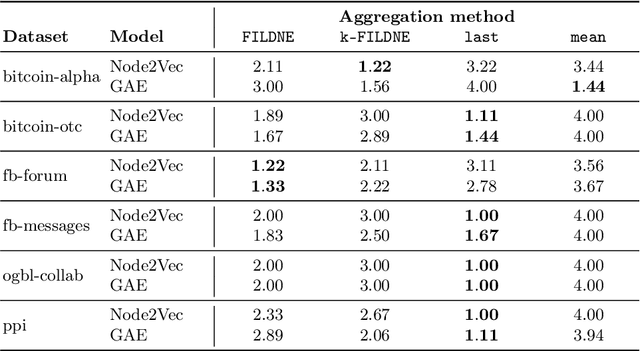
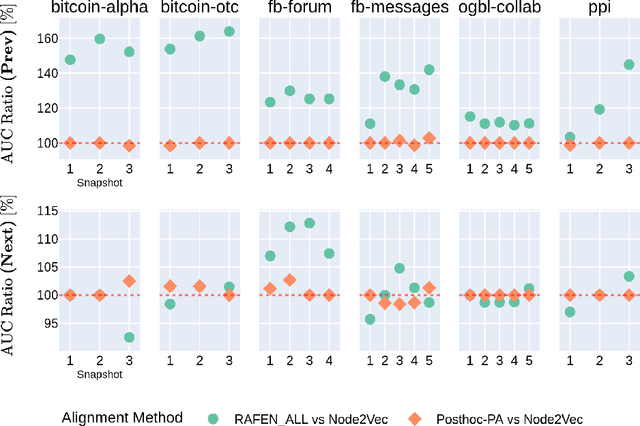
Learning representations of nodes has been a crucial area of the graph machine learning research area. A well-defined node embedding model should reflect both node features and the graph structure in the final embedding. In the case of dynamic graphs, this problem becomes even more complex as both features and structure may change over time. The embeddings of particular nodes should remain comparable during the evolution of the graph, what can be achieved by applying an alignment procedure. This step was often applied in existing works after the node embedding was already computed. In this paper, we introduce a framework -- RAFEN -- that allows to enrich any existing node embedding method using the aforementioned alignment term and learning aligned node embedding during training time. We propose several variants of our framework and demonstrate its performance on six real-world datasets. RAFEN achieves on-par or better performance than existing approaches without requiring additional processing steps.