 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning4Sciences: Bridging Reasoning Language Models to All Scientific Branches
May 31, 2026While Reasoning Language Models (RLMs) are rapidly emerging as powerful tools for scientific research, their impact is primarily concentrated in "hard science" fields. The slow -- or lack of -- adoption of RLMs in other branches of science is causing a widening gap in research productivity. In this survey, we provide the first comprehensive analysis of RLM adoption across 28 scientific disciplines following the classification used by the European Research Council (ERC), spanning the Social Sciences and Humanities, Physical Sciences and Engineering, and Life Sciences. We examine how RLMs are developed, evaluated, and applied across disciplines. Furthermore, we introduce a maturity-oriented assessment framework based on available domain-specific development and evaluation resources, revealing substantial disparities in RLM maturity that become even more pronounced when only publicly available resources are considered. Finally, we highlight current implementation paradigms that are gaining popularity across disciplines, current challenges, and future directions in enabling RLM adoption across science.
KG-Guard: Graph-Based Hallucination Detection for Knowledge Base Question Answering
May 29, 2026Large language models (LLMs) are increasingly used for knowledge base question answering (KBQA), where answering requires selecting entities from a question-specific knowledge-graph subgraph. Yet LLMs are known to hallucinate across tasks, and KBQA is no exception: even when we provide a graph as the knowledge source, the model may rely on parametric knowledge instead of graph evidence or perform invalid reasoning over the given relations. Such hallucinated answer nodes can limit the practical deployment of KBQA systems, especially in high-stakes domains such as healthcare. We formulate hallucination detection in KBQA as an answer-node classification problem and propose a lightweight graph-based framework that treats the answering LLM as a black box. \methodname represents each KBQA instance as an augmented graph. It initializes node features with semantic representations of KG entities, marks topic entities and LLM-proposed answer nodes with learned vectors, and connect a virtual question node to the topic entities. A graph encoder then produces verification-oriented node representations, and a small MLP classifies each proposed answer node using its graph representation together with the question embedding. Experiments on WebQSP, ComplexWebQuestions, and PUGG show that our detector achieves the highest F1 on all three benchmarks ($82.0$, $87.4$, and $84.3$), outperforming LLM-as-judge and sampling-based baselines, while having $\sim305\times$ fewer parameters than the reference approaches. Beyond detection, the node-level feedback is actionable: when flagged answers are fed back to the KBQA system for iterative refinement, downstream KBQA F1 improves by $13.0$--$14.5$ points and Exact Match by $16.9$--$17.6$ points.
Attention Sinks as Internal Signals for Hallucination Detection in Large Language Models
Apr 12, 2026Large language models frequently exhibit hallucinations: fluent and confident outputs that are factually incorrect or unsupported by the input context. While recent hallucination detection methods have explored various features derived from attention maps, the underlying mechanisms they exploit remain poorly understood. In this work, we propose SinkProbe, a hallucination detection method grounded in the observation that hallucinations are deeply entangled with attention sinks - tokens that accumulate disproportionate attention mass during generation - indicating a transition from distributed, input-grounded attention to compressed, prior-dominated computation. Importantly, although sink scores are computed solely from attention maps, we find that the classifier preferentially relies on sinks whose associated value vectors have large norms. Moreover, we show that previous methods implicitly depend on attention sinks by establishing their mathematical relationship to sink scores. Our findings yield a novel hallucination detection method grounded in theory that produces state-of-the-art results across popular datasets and LLMs.
PLLuM: A Family of Polish Large Language Models
Nov 05, 2025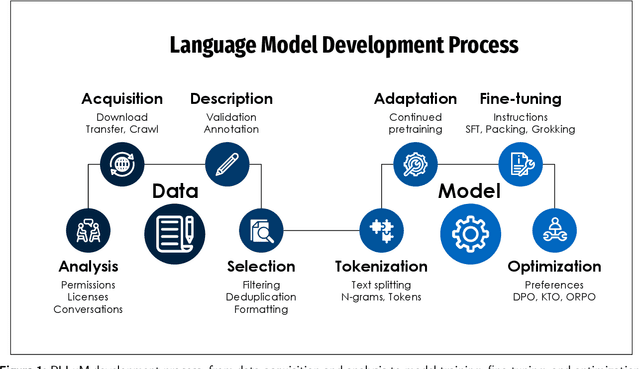
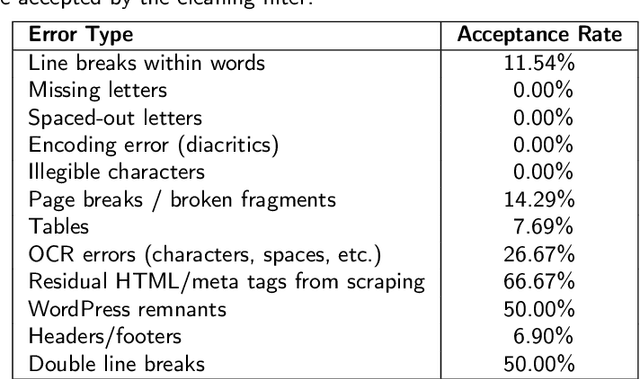
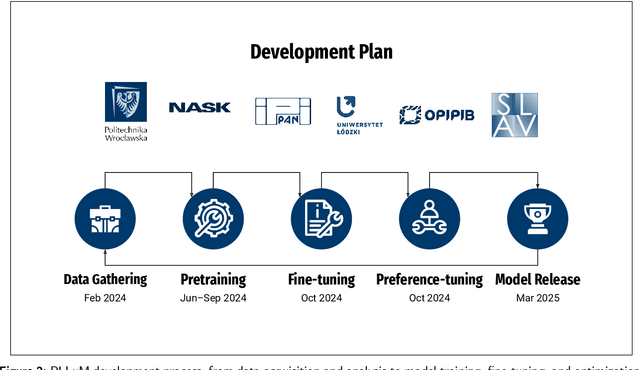

Large Language Models (LLMs) play a central role in modern artificial intelligence, yet their development has been primarily focused on English, resulting in limited support for other languages. We present PLLuM (Polish Large Language Model), the largest open-source family of foundation models tailored specifically for the Polish language. Developed by a consortium of major Polish research institutions, PLLuM addresses the need for high-quality, transparent, and culturally relevant language models beyond the English-centric commercial landscape. We describe the development process, including the construction of a new 140-billion-token Polish text corpus for pre-training, a 77k custom instructions dataset, and a 100k preference optimization dataset. A key component is a Responsible AI framework that incorporates strict data governance and a hybrid module for output correction and safety filtering. We detail the models' architecture, training procedures, and alignment techniques for both base and instruction-tuned variants, and demonstrate their utility in a downstream task within public administration. By releasing these models publicly, PLLuM aims to foster open research and strengthen sovereign AI technologies in Poland.
SMOTExT: SMOTE meets Large Language Models
May 19, 2025

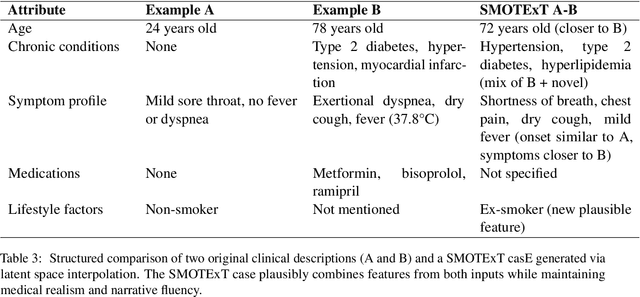
Data scarcity and class imbalance are persistent challenges in training robust NLP models, especially in specialized domains or low-resource settings. We propose a novel technique, SMOTExT, that adapts the idea of Synthetic Minority Over-sampling (SMOTE) to textual data. Our method generates new synthetic examples by interpolating between BERT-based embeddings of two existing examples and then decoding the resulting latent point into text with xRAG architecture. By leveraging xRAG's cross-modal retrieval-generation framework, we can effectively turn interpolated vectors into coherent text. While this is preliminary work supported by qualitative outputs only, the method shows strong potential for knowledge distillation and data augmentation in few-shot settings. Notably, our approach also shows promise for privacy-preserving machine learning: in early experiments, training models solely on generated data achieved comparable performance to models trained on the original dataset. This suggests a viable path toward safe and effective learning under data protection constraints.
FactSelfCheck: Fact-Level Black-Box Hallucination Detection for LLMs
Mar 21, 2025



Large Language Models (LLMs) frequently generate hallucinated content, posing significant challenges for applications where factuality is crucial. While existing hallucination detection methods typically operate at the sentence level or passage level, we propose FactSelfCheck, a novel black-box sampling-based method that enables fine-grained fact-level detection. Our approach represents text as knowledge graphs consisting of facts in the form of triples. Through analyzing factual consistency across multiple LLM responses, we compute fine-grained hallucination scores without requiring external resources or training data. Our evaluation demonstrates that FactSelfCheck performs competitively with leading sampling-based methods while providing more detailed insights. Most notably, our fact-level approach significantly improves hallucination correction, achieving a 35% increase in factual content compared to the baseline, while sentence-level SelfCheckGPT yields only an 8% improvement. The granular nature of our detection enables more precise identification and correction of hallucinated content.
Hallucination Detection in LLMs Using Spectral Features of Attention Maps
Feb 24, 2025


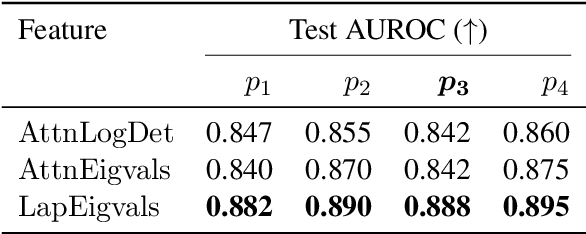
Large Language Models (LLMs) have demonstrated remarkable performance across various tasks but remain prone to hallucinations. Detecting hallucinations is essential for safety-critical applications, and recent methods leverage attention map properties to this end, though their effectiveness remains limited. In this work, we investigate the spectral features of attention maps by interpreting them as adjacency matrices of graph structures. We propose the $\text{LapEigvals}$ method, which utilises the top-$k$ eigenvalues of the Laplacian matrix derived from the attention maps as an input to hallucination detection probes. Empirical evaluations demonstrate that our approach achieves state-of-the-art hallucination detection performance among attention-based methods. Extensive ablation studies further highlight the robustness and generalisation of $\text{LapEigvals}$, paving the way for future advancements in the hallucination detection domain.
Developing PUGG for Polish: A Modern Approach to KBQA, MRC, and IR Dataset Construction
Aug 05, 2024



Advancements in AI and natural language processing have revolutionized machine-human language interactions, with question answering (QA) systems playing a pivotal role. The knowledge base question answering (KBQA) task, utilizing structured knowledge graphs (KG), allows for handling extensive knowledge-intensive questions. However, a significant gap exists in KBQA datasets, especially for low-resource languages. Many existing construction pipelines for these datasets are outdated and inefficient in human labor, and modern assisting tools like Large Language Models (LLM) are not utilized to reduce the workload. To address this, we have designed and implemented a modern, semi-automated approach for creating datasets, encompassing tasks such as KBQA, Machine Reading Comprehension (MRC), and Information Retrieval (IR), tailored explicitly for low-resource environments. We executed this pipeline and introduced the PUGG dataset, the first Polish KBQA dataset, and novel datasets for MRC and IR. Additionally, we provide a comprehensive implementation, insightful findings, detailed statistics, and evaluation of baseline models.
Empowering Small-Scale Knowledge Graphs: A Strategy of Leveraging General-Purpose Knowledge Graphs for Enriched Embeddings
May 17, 2024



Knowledge-intensive tasks pose a significant challenge for Machine Learning (ML) techniques. Commonly adopted methods, such as Large Language Models (LLMs), often exhibit limitations when applied to such tasks. Nevertheless, there have been notable endeavours to mitigate these challenges, with a significant emphasis on augmenting LLMs through Knowledge Graphs (KGs). While KGs provide many advantages for representing knowledge, their development costs can deter extensive research and applications. Addressing this limitation, we introduce a framework for enriching embeddings of small-scale domain-specific Knowledge Graphs with well-established general-purpose KGs. Adopting our method, a modest domain-specific KG can benefit from a performance boost in downstream tasks when linked to a substantial general-purpose KG. Experimental evaluations demonstrate a notable enhancement, with up to a 44% increase observed in the Hits@10 metric. This relatively unexplored research direction can catalyze more frequent incorporation of KGs in knowledge-intensive tasks, resulting in more robust, reliable ML implementations, which hallucinates less than prevalent LLM solutions. Keywords: knowledge graph, knowledge graph completion, entity alignment, representation learning, machine learning
Representation learning in multiplex graphs: Where and how to fuse information?
Feb 27, 2024

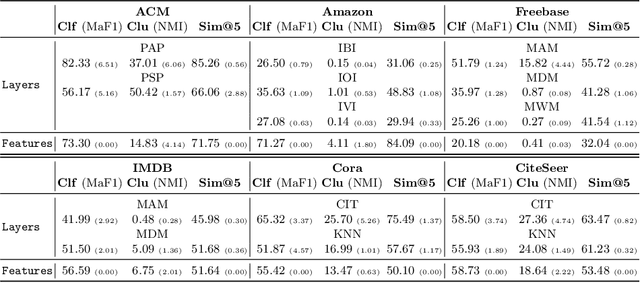

In recent years, unsupervised and self-supervised graph representation learning has gained popularity in the research community. However, most proposed methods are focused on homogeneous networks, whereas real-world graphs often contain multiple node and edge types. Multiplex graphs, a special type of heterogeneous graphs, possess richer information, provide better modeling capabilities and integrate more detailed data from potentially different sources. The diverse edge types in multiplex graphs provide more context and insights into the underlying processes of representation learning. In this paper, we tackle the problem of learning representations for nodes in multiplex networks in an unsupervised or self-supervised manner. To that end, we explore diverse information fusion schemes performed at different levels of the graph processing pipeline. The detailed analysis and experimental evaluation of various scenarios inspired us to propose improvements in how to construct GNN architectures that deal with multiplex graphs.