 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElectoral Agitation Data Set: The Use Case of the Polish Election
Jul 13, 2023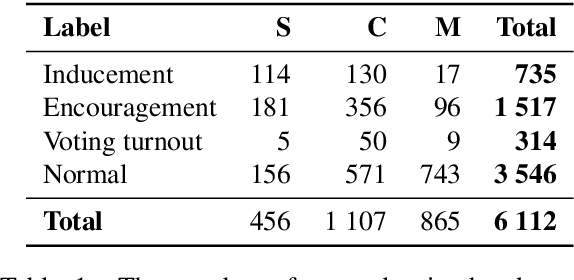
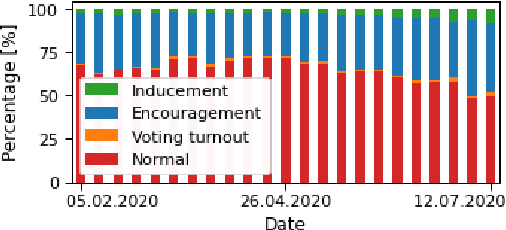
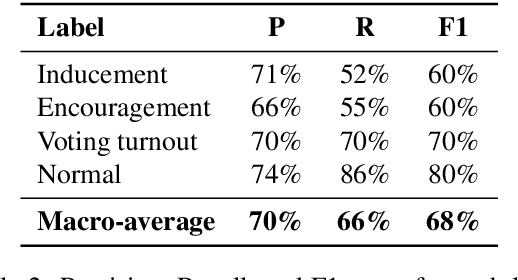
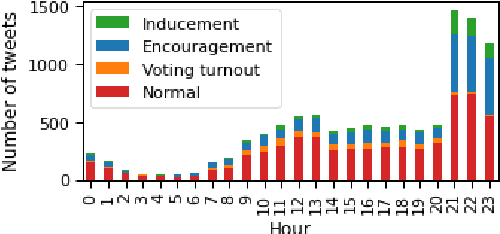
The popularity of social media makes politicians use it for political advertisement. Therefore, social media is full of electoral agitation (electioneering), especially during the election campaigns. The election administration cannot track the spread and quantity of messages that count as agitation under the election code. It addresses a crucial problem, while also uncovering a niche that has not been effectively targeted so far. Hence, we present the first publicly open data set for detecting electoral agitation in the Polish language. It contains 6,112 human-annotated tweets tagged with four legally conditioned categories. We achieved a 0.66 inter-annotator agreement (Cohen's kappa score). An additional annotator resolved the mismatches between the first two improving the consistency and complexity of the annotation process. The newly created data set was used to fine-tune a Polish Language Model called HerBERT (achieving a 68% F1 score). We also present a number of potential use cases for such data sets and models, enriching the paper with an analysis of the Polish 2020 Presidential Election on Twitter.
Massively Multilingual Corpus of Sentiment Datasets and Multi-faceted Sentiment Classification Benchmark
Jun 13, 2023Despite impressive advancements in multilingual corpora collection and model training, developing large-scale deployments of multilingual models still presents a significant challenge. This is particularly true for language tasks that are culture-dependent. One such example is the area of multilingual sentiment analysis, where affective markers can be subtle and deeply ensconced in culture. This work presents the most extensive open massively multilingual corpus of datasets for training sentiment models. The corpus consists of 79 manually selected datasets from over 350 datasets reported in the scientific literature based on strict quality criteria. The corpus covers 27 languages representing 6 language families. Datasets can be queried using several linguistic and functional features. In addition, we present a multi-faceted sentiment classification benchmark summarizing hundreds of experiments conducted on different base models, training objectives, dataset collections, and fine-tuning strategies.
This is the way: designing and compiling LEPISZCZE, a comprehensive NLP benchmark for Polish
Nov 23, 2022The availability of compute and data to train larger and larger language models increases the demand for robust methods of benchmarking the true progress of LM training. Recent years witnessed significant progress in standardized benchmarking for English. Benchmarks such as GLUE, SuperGLUE, or KILT have become de facto standard tools to compare large language models. Following the trend to replicate GLUE for other languages, the KLEJ benchmark has been released for Polish. In this paper, we evaluate the progress in benchmarking for low-resourced languages. We note that only a handful of languages have such comprehensive benchmarks. We also note the gap in the number of tasks being evaluated by benchmarks for resource-rich English/Chinese and the rest of the world. In this paper, we introduce LEPISZCZE (the Polish word for glew, the Middle English predecessor of glue), a new, comprehensive benchmark for Polish NLP with a large variety of tasks and high-quality operationalization of the benchmark. We design LEPISZCZE with flexibility in mind. Including new models, datasets, and tasks is as simple as possible while still offering data versioning and model tracking. In the first run of the benchmark, we test 13 experiments (task and dataset pairs) based on the five most recent LMs for Polish. We use five datasets from the Polish benchmark and add eight novel datasets. As the paper's main contribution, apart from LEPISZCZE, we provide insights and experiences learned while creating the benchmark for Polish as the blueprint to design similar benchmarks for other low-resourced languages.
* 10 pages, 8 pages appendix
Assessment of Massively Multilingual Sentiment Classifiers
Apr 11, 2022
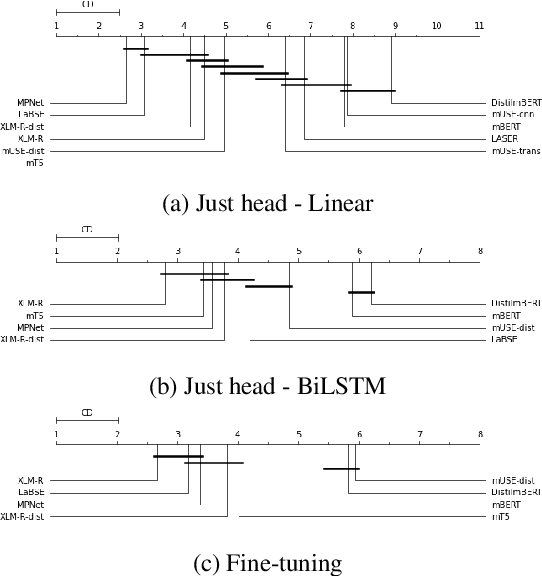
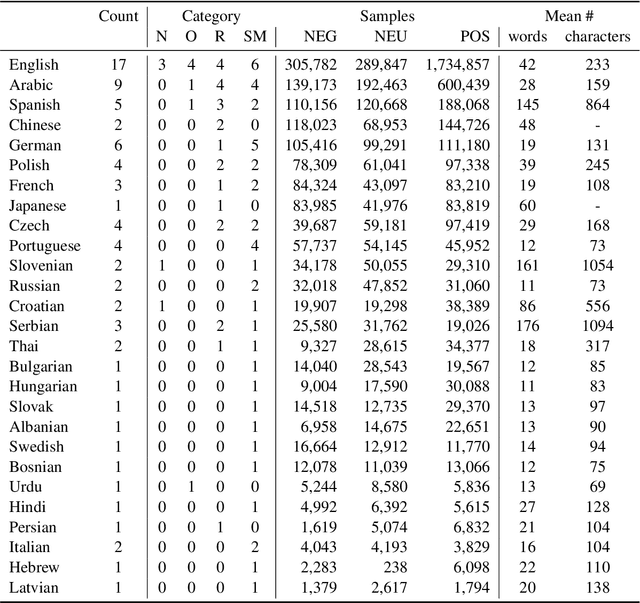
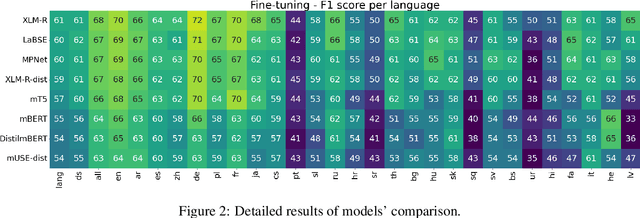
Models are increasing in size and complexity in the hunt for SOTA. But what if those 2\% increase in performance does not make a difference in a production use case? Maybe benefits from a smaller, faster model outweigh those slight performance gains. Also, equally good performance across languages in multilingual tasks is more important than SOTA results on a single one. We present the biggest, unified, multilingual collection of sentiment analysis datasets. We use these to assess 11 models and 80 high-quality sentiment datasets (out of 342 raw datasets collected) in 27 languages and included results on the internally annotated datasets. We deeply evaluate multiple setups, including fine-tuning transformer-based models for measuring performance. We compare results in numerous dimensions addressing the imbalance in both languages coverage and dataset sizes. Finally, we present some best practices for working with such a massive collection of datasets and models from a multilingual perspective.
Political Advertising Dataset: the use case of the Polish 2020 Presidential Elections
Jun 17, 2020
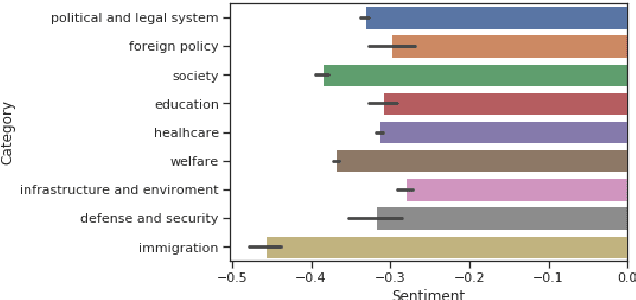
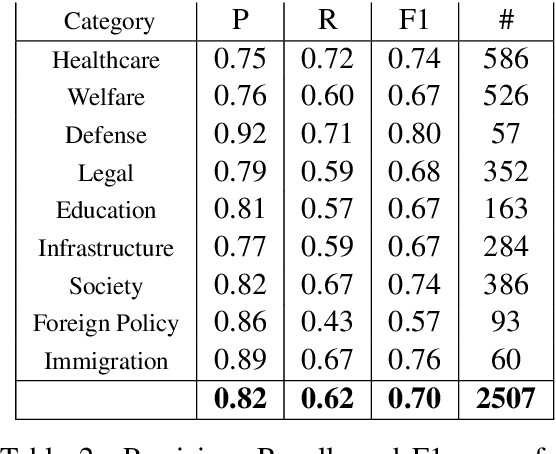
Political campaigns are full of political ads posted by candidates on social media. Political advertisements constitute a basic form of campaigning, subjected to various social requirements. We present the first publicly open dataset for detecting specific text chunks and categories of political advertising in the Polish language. It contains 1,705 human-annotated tweets tagged with nine categories, which constitute campaigning under Polish electoral law. We achieved a 0.65 inter-annotator agreement (Cohen's kappa score). An additional annotator resolved the mismatches between the first two annotators improving the consistency and complexity of the annotation process. We used the newly created dataset to train a well established neural tagger (achieving a 70% percent points F1 score). We also present a possible direction of use cases for such datasets and models with an initial analysis of the Polish 2020 Presidential Elections on Twitter.
Punctuation Prediction in Spontaneous Conversations: Can We Mitigate ASR Errors with Retrofitted Word Embeddings?
Apr 13, 2020
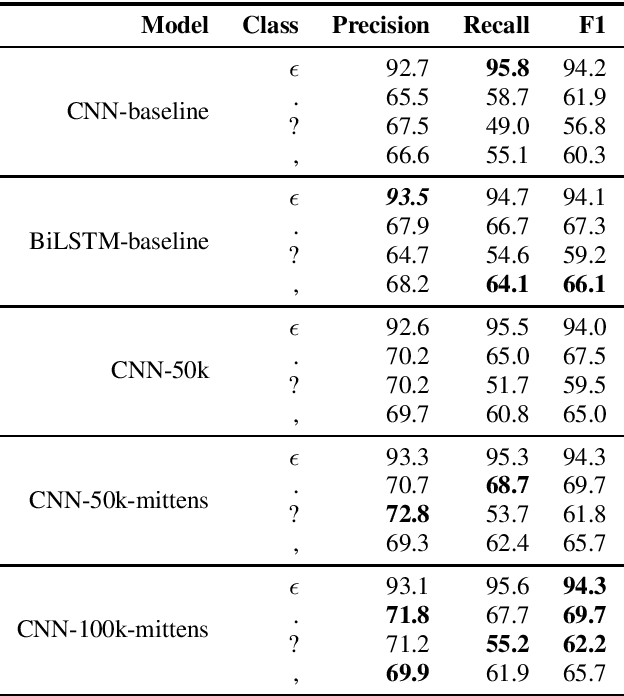
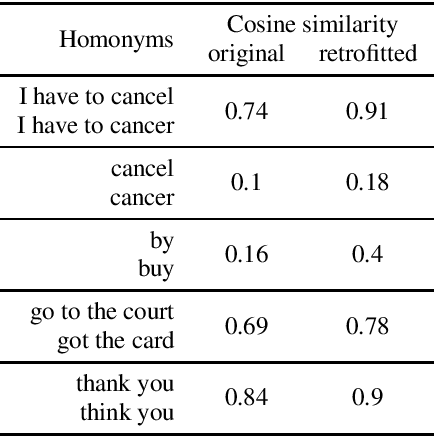

Automatic Speech Recognition (ASR) systems introduce word errors, which often confuse punctuation prediction models, turning punctuation restoration into a challenging task. These errors usually take the form of homonyms. We show how retrofitting of the word embeddings on the domain-specific data can mitigate ASR errors. Our main contribution is a method for better alignment of homonym embeddings and the validation of the presented method on the punctuation prediction task. We record the absolute improvement in punctuation prediction accuracy between 6.2% (for question marks) to 9% (for periods) when compared with the state-of-the-art model.
Comprehensive Analysis of Aspect Term Extraction Methods using Various Text Embeddings
Sep 11, 2019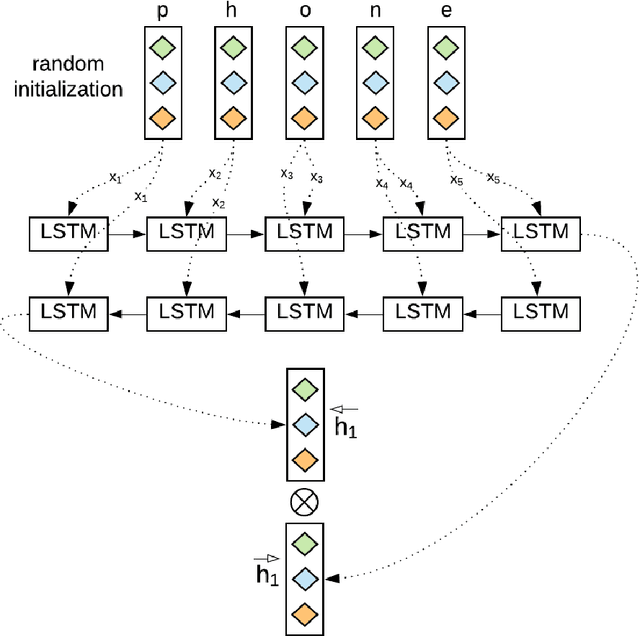
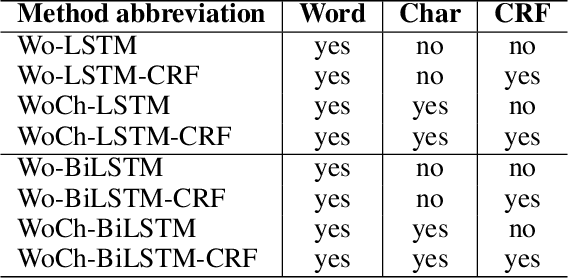
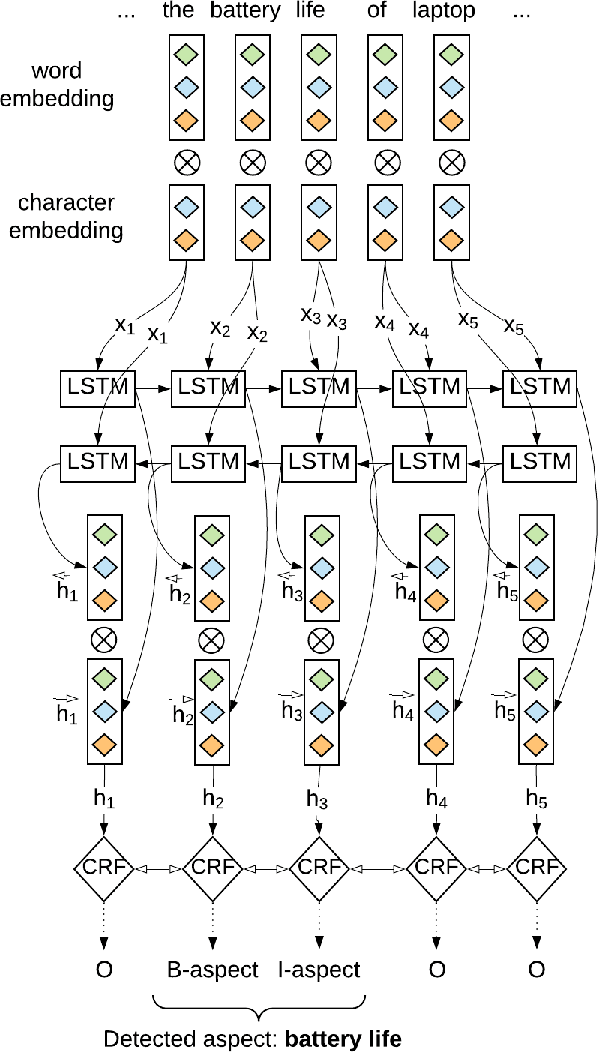
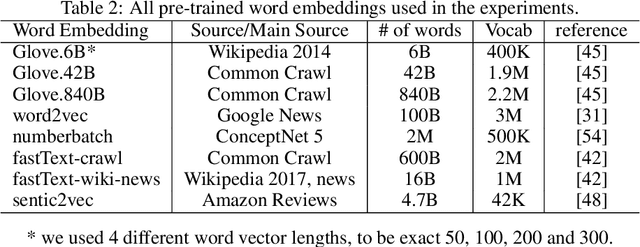
Recently, a variety of model designs and methods have blossomed in the context of the sentiment analysis domain. However, there is still a lack of wide and comprehensive studies of aspect-based sentiment analysis (ABSA). We want to fill this gap and propose a comparison with ablation analysis of aspect term extraction using various text embedding methods. We particularly focused on architectures based on long short-term memory (LSTM) with optional conditional random field (CRF) enhancement using different pre-trained word embeddings. Moreover, we analyzed the influence on the performance of extending the word vectorization step with character embedding. The experimental results on SemEval datasets revealed that not only does bi-directional long short-term memory (BiLSTM) outperform regular LSTM, but also word embedding coverage and its source highly affect aspect detection performance. An additional CRF layer consistently improves the results as well.
Extracting Aspects Hierarchies using Rhetorical Structure Theory
Sep 04, 2019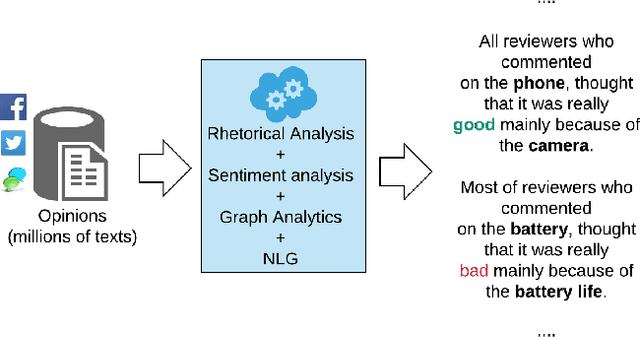

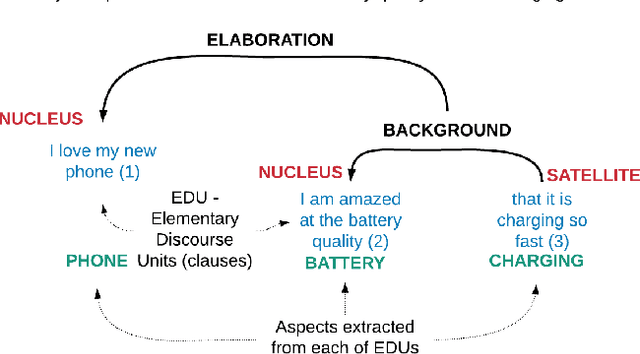
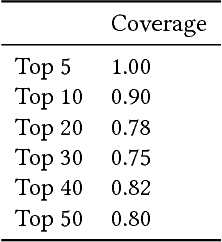
We propose a novel approach to generate aspect hierarchies that proved to be consistently correct compared with human-generated hierarchies. We present an unsupervised technique using Rhetorical Structure Theory and graph analysis. We evaluated our approach based on 100,000 reviews from Amazon and achieved an astonishing 80% coverage compared with human-generated hierarchies coded in ConceptNet. The method could be easily extended with a sentiment analysis model and used to describe sentiment on different levels of aspect granularity. Hence, besides the flat aspect structure, we can differentiate between aspects and describe if the charging aspect is related to battery or price.
* ACAI 2018 MLNLP
Aspect Detection using Word and Char Embeddings with (Bi)LSTM and CRF
Sep 03, 2019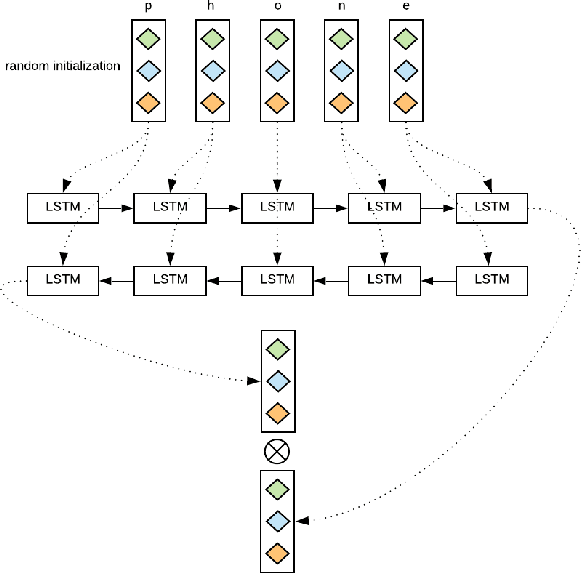
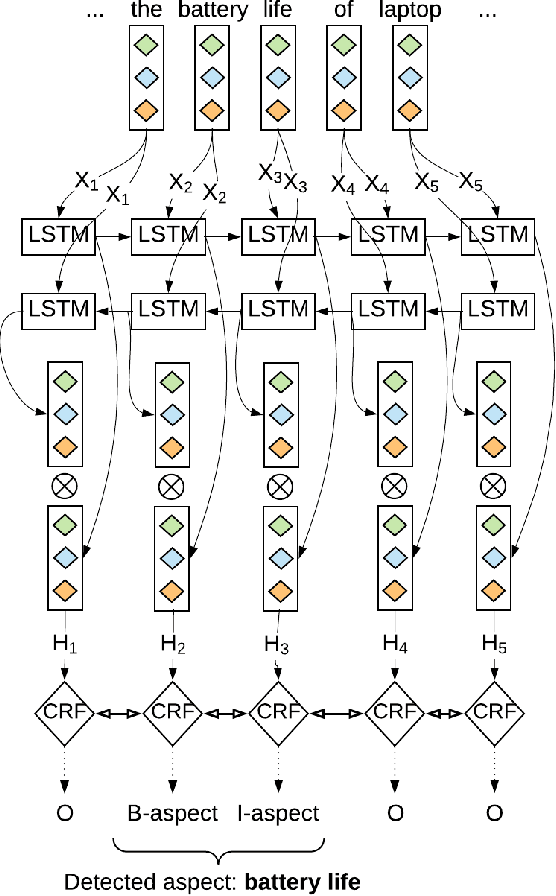
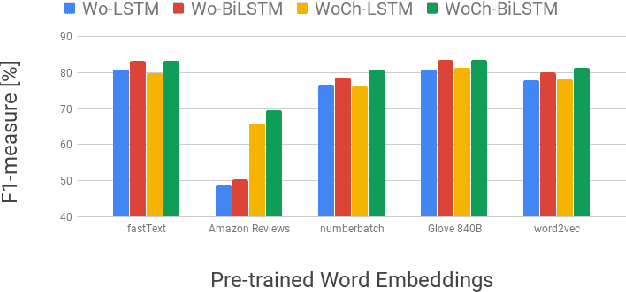
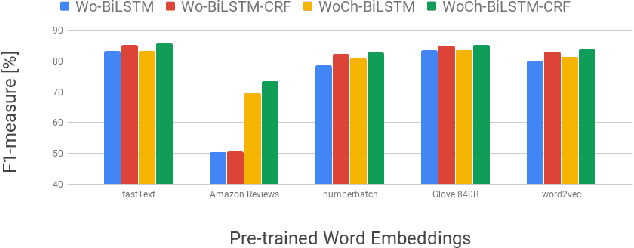
We proposed a~new accurate aspect extraction method that makes use of both word and character-based embeddings. We have conducted experiments of various models of aspect extraction using LSTM and BiLSTM including CRF enhancement on five different pre-trained word embeddings extended with character embeddings. The results revealed that BiLSTM outperforms regular LSTM, but also word embedding coverage in train and test sets profoundly impacted aspect detection performance. Moreover, the additional CRF layer consistently improves the results across different models and text embeddings. Summing up, we obtained state-of-the-art F-score results for SemEval Restaurants (85%) and Laptops (80%).
* IEEE AIKE
Avaya Conversational Intelligence: A Real-Time System for Spoken Language Understanding in Human-Human Call Center Conversations
Sep 02, 2019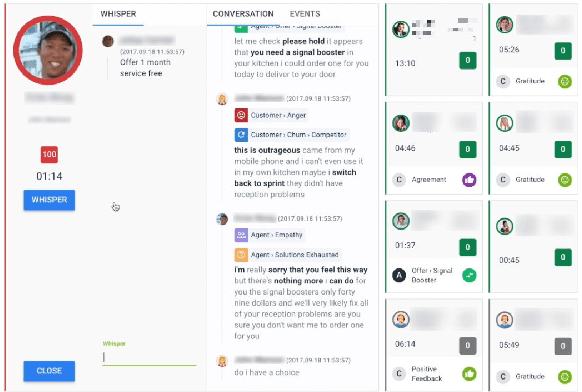

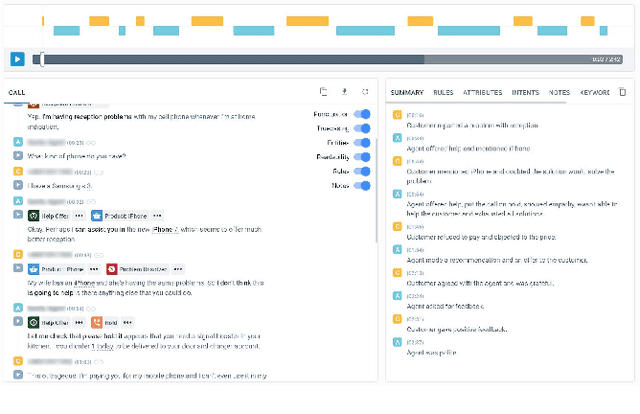
Avaya Conversational Intelligence(ACI) is an end-to-end, cloud-based solution for real-time Spoken Language Understanding for call centers. It combines large vocabulary, real-time speech recognition, transcript refinement, and entity and intent recognition in order to convert live audio into a rich, actionable stream of structured events. These events can be further leveraged with a business rules engine, thus serving as a foundation for real-time supervision and assistance applications. After the ingestion, calls are enriched with unsupervised keyword extraction, abstractive summarization, and business-defined attributes, enabling offline use cases, such as business intelligence, topic mining, full-text search, quality assurance, and agent training. ACI comes with a pretrained, configurable library of hundreds of intents and a robust intent training environment that allows for efficient, cost-effective creation and customization of customer-specific intents.