 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThis is the way: designing and compiling LEPISZCZE, a comprehensive NLP benchmark for Polish
Nov 23, 2022The availability of compute and data to train larger and larger language models increases the demand for robust methods of benchmarking the true progress of LM training. Recent years witnessed significant progress in standardized benchmarking for English. Benchmarks such as GLUE, SuperGLUE, or KILT have become de facto standard tools to compare large language models. Following the trend to replicate GLUE for other languages, the KLEJ benchmark has been released for Polish. In this paper, we evaluate the progress in benchmarking for low-resourced languages. We note that only a handful of languages have such comprehensive benchmarks. We also note the gap in the number of tasks being evaluated by benchmarks for resource-rich English/Chinese and the rest of the world. In this paper, we introduce LEPISZCZE (the Polish word for glew, the Middle English predecessor of glue), a new, comprehensive benchmark for Polish NLP with a large variety of tasks and high-quality operationalization of the benchmark. We design LEPISZCZE with flexibility in mind. Including new models, datasets, and tasks is as simple as possible while still offering data versioning and model tracking. In the first run of the benchmark, we test 13 experiments (task and dataset pairs) based on the five most recent LMs for Polish. We use five datasets from the Polish benchmark and add eight novel datasets. As the paper's main contribution, apart from LEPISZCZE, we provide insights and experiences learned while creating the benchmark for Polish as the blueprint to design similar benchmarks for other low-resourced languages.
* 10 pages, 8 pages appendix
WER we are and WER we think we are
Oct 07, 2020
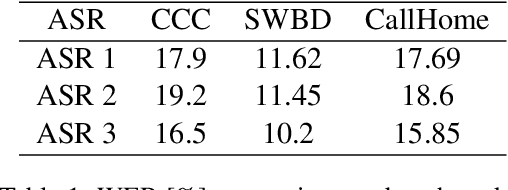
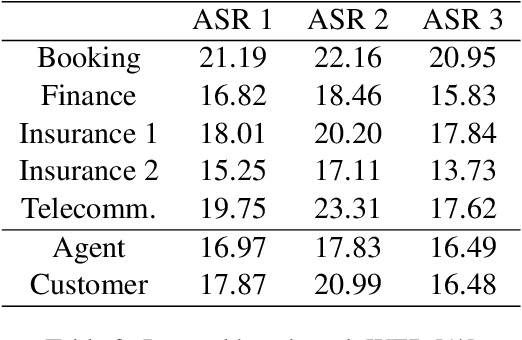
Natural language processing of conversational speech requires the availability of high-quality transcripts. In this paper, we express our skepticism towards the recent reports of very low Word Error Rates (WERs) achieved by modern Automatic Speech Recognition (ASR) systems on benchmark datasets. We outline several problems with popular benchmarks and compare three state-of-the-art commercial ASR systems on an internal dataset of real-life spontaneous human conversations and HUB'05 public benchmark. We show that WERs are significantly higher than the best reported results. We formulate a set of guidelines which may aid in the creation of real-life, multi-domain datasets with high quality annotations for training and testing of robust ASR systems.
Punctuation Prediction in Spontaneous Conversations: Can We Mitigate ASR Errors with Retrofitted Word Embeddings?
Apr 13, 2020
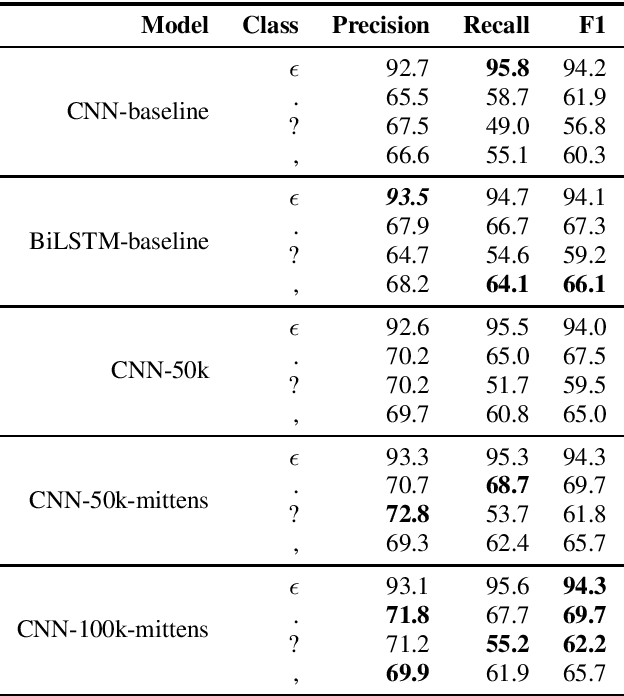
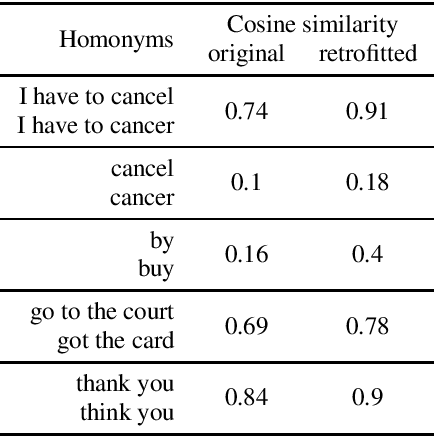

Automatic Speech Recognition (ASR) systems introduce word errors, which often confuse punctuation prediction models, turning punctuation restoration into a challenging task. These errors usually take the form of homonyms. We show how retrofitting of the word embeddings on the domain-specific data can mitigate ASR errors. Our main contribution is a method for better alignment of homonym embeddings and the validation of the presented method on the punctuation prediction task. We record the absolute improvement in punctuation prediction accuracy between 6.2% (for question marks) to 9% (for periods) when compared with the state-of-the-art model.
Avaya Conversational Intelligence: A Real-Time System for Spoken Language Understanding in Human-Human Call Center Conversations
Sep 02, 2019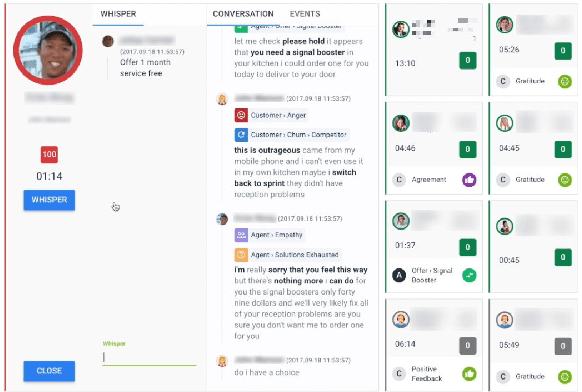

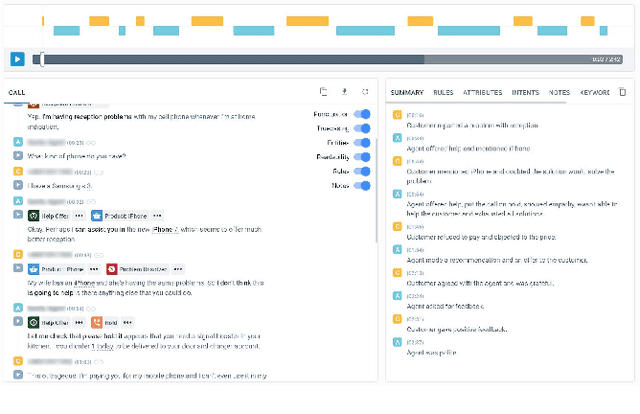
Avaya Conversational Intelligence(ACI) is an end-to-end, cloud-based solution for real-time Spoken Language Understanding for call centers. It combines large vocabulary, real-time speech recognition, transcript refinement, and entity and intent recognition in order to convert live audio into a rich, actionable stream of structured events. These events can be further leveraged with a business rules engine, thus serving as a foundation for real-time supervision and assistance applications. After the ingestion, calls are enriched with unsupervised keyword extraction, abstractive summarization, and business-defined attributes, enabling offline use cases, such as business intelligence, topic mining, full-text search, quality assurance, and agent training. ACI comes with a pretrained, configurable library of hundreds of intents and a robust intent training environment that allows for efficient, cost-effective creation and customization of customer-specific intents.
Towards Better Understanding of Spontaneous Conversations: Overcoming Automatic Speech Recognition Errors With Intent Recognition
Aug 21, 2019

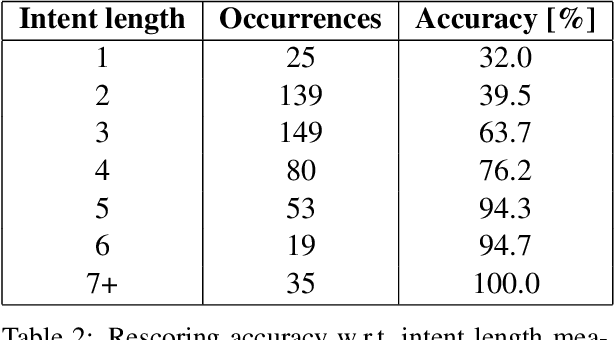

In this paper, we present a method for correcting automatic speech recognition (ASR) errors using a finite state transducer (FST) intent recognition framework. Intent recognition is a powerful technique for dialog flow management in turn-oriented, human-machine dialogs. This technique can also be very useful in the context of human-human dialogs, though it serves a different purpose of key insight extraction from conversations. We argue that currently available intent recognition techniques are not applicable to human-human dialogs due to the complex structure of turn-taking and various disfluencies encountered in spontaneous conversations, exacerbated by speech recognition errors and scarcity of domain-specific labeled data. Without efficient key insight extraction techniques, raw human-human dialog transcripts remain significantly unexploited. Our contribution consists of a novel FST for intent indexing and an algorithm for fuzzy intent search over the lattice - a compact graph encoding of ASR's hypotheses. We also develop a pruning strategy to constrain the fuzziness of the FST index search. Extracted intents represent linguistic domain knowledge and help us improve (rescore) the original transcript. We compare our method with a baseline, which uses only the most likely transcript hypothesis (best path), and find an increase in the total number of recognized intents by 25%.
Punctuation Prediction Model for Conversational Speech
Jul 02, 2018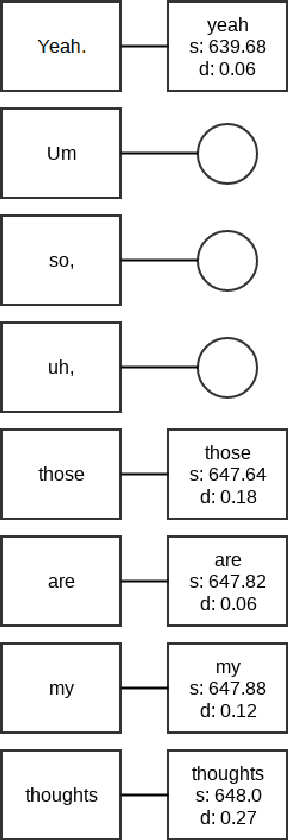
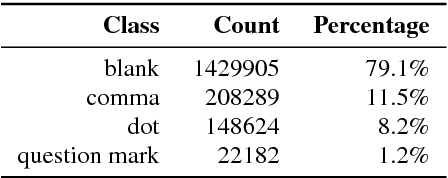
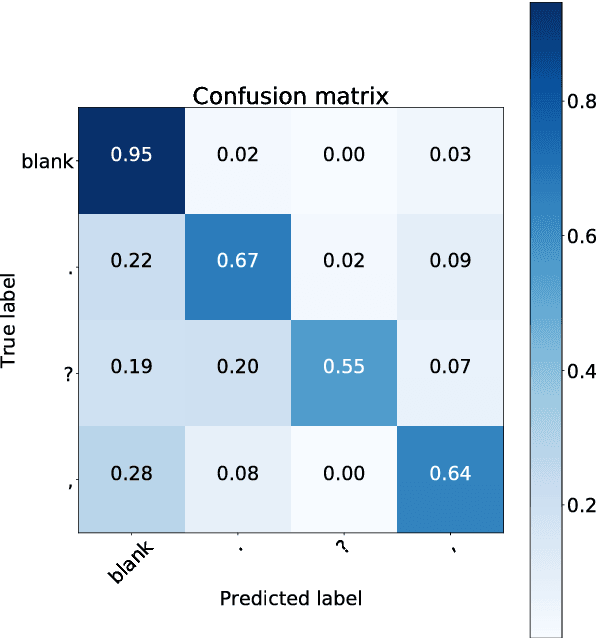

An ASR system usually does not predict any punctuation or capitalization. Lack of punctuation causes problems in result presentation and confuses both the human reader andoff-the-shelf natural language processing algorithms. To overcome these limitations, we train two variants of Deep Neural Network (DNN) sequence labelling models - a Bidirectional Long Short-Term Memory (BLSTM) and a Convolutional Neural Network (CNN), to predict the punctuation. The models are trained on the Fisher corpus which includes punctuation annotation. In our experiments, we combine time-aligned and punctuated Fisher corpus transcripts using a sequence alignment algorithm. The neural networks are trained on Common Web Crawl GloVe embedding of the words in Fisher transcripts aligned with conversation side indicators and word time infomation. The CNNs yield a better precision and BLSTMs tend to have better recall. While BLSTMs make fewer mistakes overall, the punctuation predicted by the CNN is more accurate - especially in the case of question marks. Our results constitute significant evidence that the distribution of words in time, as well as pre-trained embeddings, can be useful in the punctuation prediction task.