 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAFEN -- Regularized Alignment Framework for Embeddings of Nodes
Mar 03, 2023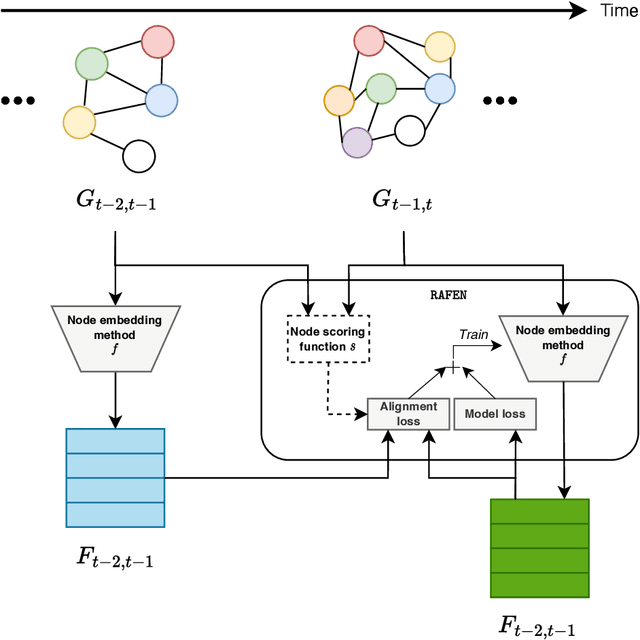
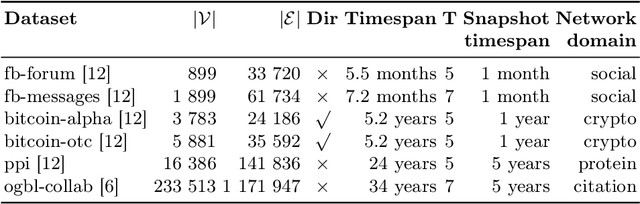
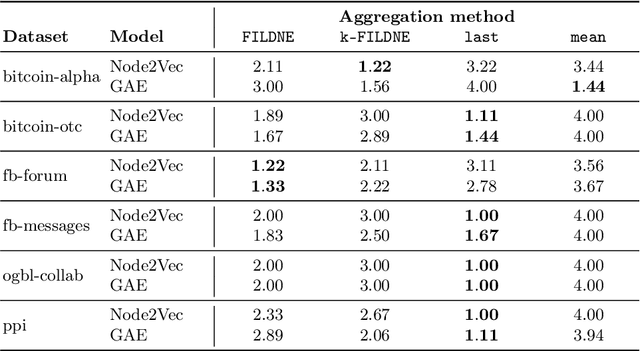
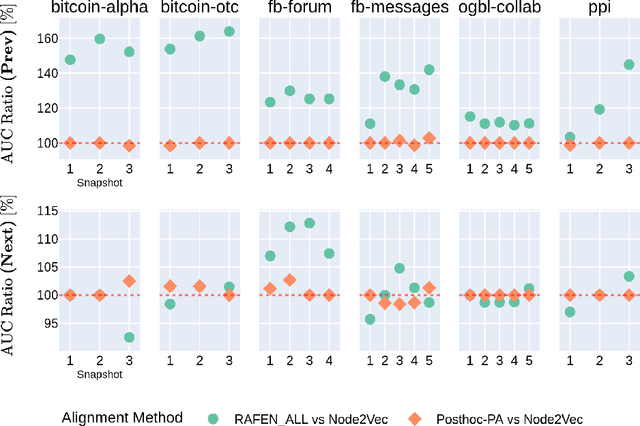
Learning representations of nodes has been a crucial area of the graph machine learning research area. A well-defined node embedding model should reflect both node features and the graph structure in the final embedding. In the case of dynamic graphs, this problem becomes even more complex as both features and structure may change over time. The embeddings of particular nodes should remain comparable during the evolution of the graph, what can be achieved by applying an alignment procedure. This step was often applied in existing works after the node embedding was already computed. In this paper, we introduce a framework -- RAFEN -- that allows to enrich any existing node embedding method using the aforementioned alignment term and learning aligned node embedding during training time. We propose several variants of our framework and demonstrate its performance on six real-world datasets. RAFEN achieves on-par or better performance than existing approaches without requiring additional processing steps.
This is the way: designing and compiling LEPISZCZE, a comprehensive NLP benchmark for Polish
Nov 23, 2022The availability of compute and data to train larger and larger language models increases the demand for robust methods of benchmarking the true progress of LM training. Recent years witnessed significant progress in standardized benchmarking for English. Benchmarks such as GLUE, SuperGLUE, or KILT have become de facto standard tools to compare large language models. Following the trend to replicate GLUE for other languages, the KLEJ benchmark has been released for Polish. In this paper, we evaluate the progress in benchmarking for low-resourced languages. We note that only a handful of languages have such comprehensive benchmarks. We also note the gap in the number of tasks being evaluated by benchmarks for resource-rich English/Chinese and the rest of the world. In this paper, we introduce LEPISZCZE (the Polish word for glew, the Middle English predecessor of glue), a new, comprehensive benchmark for Polish NLP with a large variety of tasks and high-quality operationalization of the benchmark. We design LEPISZCZE with flexibility in mind. Including new models, datasets, and tasks is as simple as possible while still offering data versioning and model tracking. In the first run of the benchmark, we test 13 experiments (task and dataset pairs) based on the five most recent LMs for Polish. We use five datasets from the Polish benchmark and add eight novel datasets. As the paper's main contribution, apart from LEPISZCZE, we provide insights and experiences learned while creating the benchmark for Polish as the blueprint to design similar benchmarks for other low-resourced languages.
* 10 pages, 8 pages appendix
On Graph Neural Network Ensembles for Large-Scale Molecular Property Prediction
Jun 29, 2021
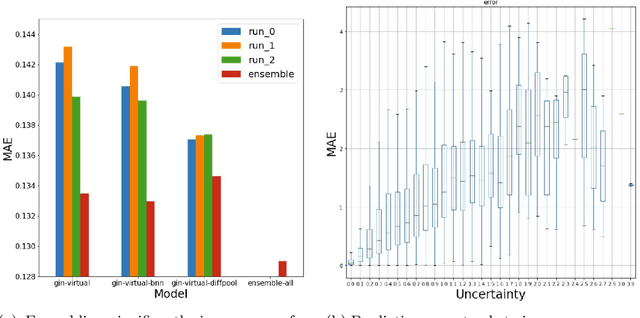
In order to advance large-scale graph machine learning, the Open Graph Benchmark Large Scale Challenge (OGB-LSC) was proposed at the KDD Cup 2021. The PCQM4M-LSC dataset defines a molecular HOMO-LUMO property prediction task on about 3.8M graphs. In this short paper, we show our current work-in-progress solution which builds an ensemble of three graph neural networks models based on GIN, Bayesian Neural Networks and DiffPool. Our approach outperforms the provided baseline by 7.6%. Moreover, using uncertainty in our ensemble's prediction, we can identify molecules whose HOMO-LUMO gaps are harder to predict (with Pearson's correlation of 0.5181). We anticipate that this will facilitate active learning.
Incremental embedding for temporal networks
Apr 06, 2019

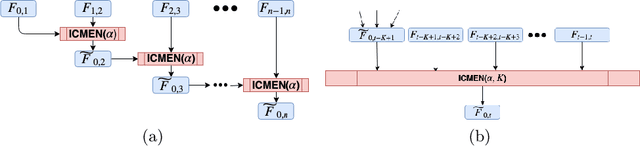

Prediction over edges and nodes in graphs requires appropriate and efficiently achieved data representation. Recent research on representation learning for dynamic networks resulted in a significant progress. However, the more precise and accurate methods, the greater computational and memory complexity. Here, we introduce ICMEN - the first-in-class incremental meta-embedding method that produces vector representations of nodes respecting temporal dependencies in the graph. ICMEN efficiently constructs nodes' embedding from historical representations by linearly convex combinations making the process less memory demanding than state-of-the-art embedding algorithms. The method is capable of constructing representation for inactive and new nodes without a need to re-embed. The results of link prediction on several real-world datasets shown that applying ICMEN incremental meta-method to any base embedding approach, we receive similar results and save memory and computational power. Taken together, our work proposes a new way of efficient online representation learning in dynamic complex networks.