 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Evaluation of Alignment Methods: Insights into Diversity, Generalisation, and Safety
Sep 16, 2025Large language models (LLMs) require careful alignment to balance competing objectives - factuality, safety, conciseness, proactivity, and diversity. Existing studies focus on individual techniques or specific dimensions, lacking a holistic assessment of the inherent trade-offs. We propose a unified evaluation framework that compares LLM alignment methods (PPO, DPO, ORPO, KTO) across these five axes, using both in-distribution and out-of-distribution datasets. Leveraging a specialized LLM-as-Judge prompt, validated through human studies, we reveal that DPO and KTO excel in factual accuracy, PPO and DPO lead in safety, and PPO best balances conciseness with proactivity. Our findings provide insights into trade-offs of common alignment methods, guiding the development of more balanced and reliable LLMs.
FactSelfCheck: Fact-Level Black-Box Hallucination Detection for LLMs
Mar 21, 2025Large Language Models (LLMs) frequently generate hallucinated content, posing significant challenges for applications where factuality is crucial. While existing hallucination detection methods typically operate at the sentence level or passage level, we propose FactSelfCheck, a novel black-box sampling-based method that enables fine-grained fact-level detection. Our approach represents text as knowledge graphs consisting of facts in the form of triples. Through analyzing factual consistency across multiple LLM responses, we compute fine-grained hallucination scores without requiring external resources or training data. Our evaluation demonstrates that FactSelfCheck performs competitively with leading sampling-based methods while providing more detailed insights. Most notably, our fact-level approach significantly improves hallucination correction, achieving a 35% increase in factual content compared to the baseline, while sentence-level SelfCheckGPT yields only an 8% improvement. The granular nature of our detection enables more precise identification and correction of hallucinated content.
Hallucination Detection in LLMs Using Spectral Features of Attention Maps
Feb 24, 2025Large Language Models (LLMs) have demonstrated remarkable performance across various tasks but remain prone to hallucinations. Detecting hallucinations is essential for safety-critical applications, and recent methods leverage attention map properties to this end, though their effectiveness remains limited. In this work, we investigate the spectral features of attention maps by interpreting them as adjacency matrices of graph structures. We propose the $\text{LapEigvals}$ method, which utilises the top-$k$ eigenvalues of the Laplacian matrix derived from the attention maps as an input to hallucination detection probes. Empirical evaluations demonstrate that our approach achieves state-of-the-art hallucination detection performance among attention-based methods. Extensive ablation studies further highlight the robustness and generalisation of $\text{LapEigvals}$, paving the way for future advancements in the hallucination detection domain.
Unveiling the Potential of Probabilistic Embeddings in Self-Supervised Learning
Oct 27, 2023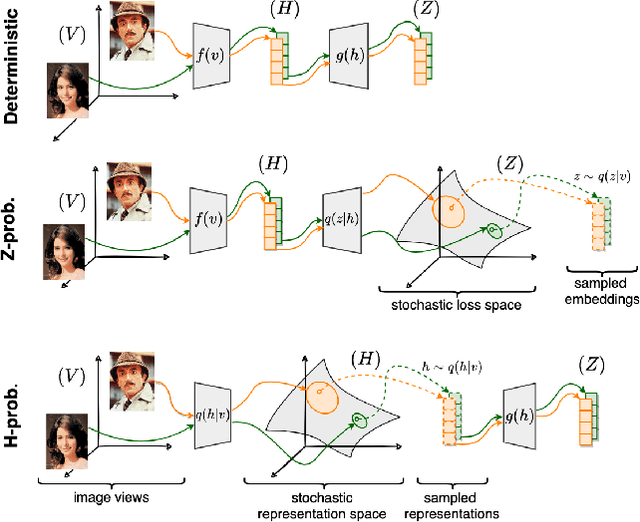
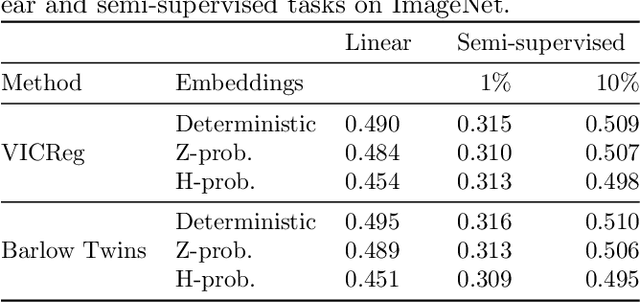
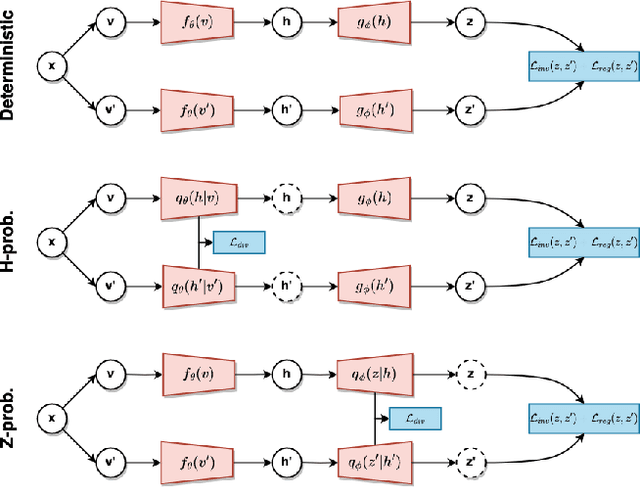
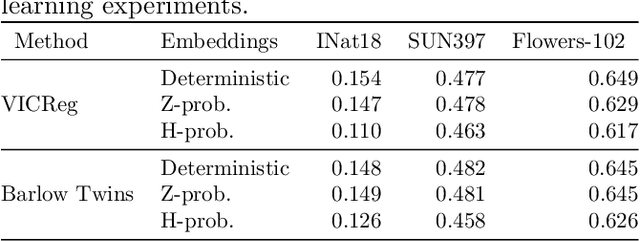
In recent years, self-supervised learning has played a pivotal role in advancing machine learning by allowing models to acquire meaningful representations from unlabeled data. An intriguing research avenue involves developing self-supervised models within an information-theoretic framework, but many studies often deviate from the stochasticity assumptions made when deriving their objectives. To gain deeper insights into this issue, we propose to explicitly model the representation with stochastic embeddings and assess their effects on performance, information compression and potential for out-of-distribution detection. From an information-theoretic perspective, we seek to investigate the impact of probabilistic modeling on the information bottleneck, shedding light on a trade-off between compression and preservation of information in both representation and loss space. Emphasizing the importance of distinguishing between these two spaces, we demonstrate how constraining one can affect the other, potentially leading to performance degradation. Moreover, our findings suggest that introducing an additional bottleneck in the loss space can significantly enhance the ability to detect out-of-distribution examples, only leveraging either representation features or the variance of their underlying distribution.
Graph-level representations using ensemble-based readout functions
Mar 03, 2023Graph machine learning models have been successfully deployed in a variety of application areas. One of the most prominent types of models - Graph Neural Networks (GNNs) - provides an elegant way of extracting expressive node-level representation vectors, which can be used to solve node-related problems, such as classifying users in a social network. However, many tasks require representations at the level of the whole graph, e.g., molecular applications. In order to convert node-level representations into a graph-level vector, a so-called readout function must be applied. In this work, we study existing readout methods, including simple non-trainable ones, as well as complex, parametrized models. We introduce a concept of ensemble-based readout functions that combine either representations or predictions. Our experiments show that such ensembles allow for better performance than simple single readouts or similar performance as the complex, parametrized ones, but at a fraction of the model complexity.
This is the way: designing and compiling LEPISZCZE, a comprehensive NLP benchmark for Polish
Nov 23, 2022The availability of compute and data to train larger and larger language models increases the demand for robust methods of benchmarking the true progress of LM training. Recent years witnessed significant progress in standardized benchmarking for English. Benchmarks such as GLUE, SuperGLUE, or KILT have become de facto standard tools to compare large language models. Following the trend to replicate GLUE for other languages, the KLEJ benchmark has been released for Polish. In this paper, we evaluate the progress in benchmarking for low-resourced languages. We note that only a handful of languages have such comprehensive benchmarks. We also note the gap in the number of tasks being evaluated by benchmarks for resource-rich English/Chinese and the rest of the world. In this paper, we introduce LEPISZCZE (the Polish word for glew, the Middle English predecessor of glue), a new, comprehensive benchmark for Polish NLP with a large variety of tasks and high-quality operationalization of the benchmark. We design LEPISZCZE with flexibility in mind. Including new models, datasets, and tasks is as simple as possible while still offering data versioning and model tracking. In the first run of the benchmark, we test 13 experiments (task and dataset pairs) based on the five most recent LMs for Polish. We use five datasets from the Polish benchmark and add eight novel datasets. As the paper's main contribution, apart from LEPISZCZE, we provide insights and experiences learned while creating the benchmark for Polish as the blueprint to design similar benchmarks for other low-resourced languages.
* 10 pages, 8 pages appendix