 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVARSHAP: Addressing Global Dependency Problems in Explainable AI with Variance-Based Local Feature Attribution
Jun 08, 2025



Existing feature attribution methods like SHAP often suffer from global dependence, failing to capture true local model behavior. This paper introduces VARSHAP, a novel model-agnostic local feature attribution method which uses the reduction of prediction variance as the key importance metric of features. Building upon Shapley value framework, VARSHAP satisfies the key Shapley axioms, but, unlike SHAP, is resilient to global data distribution shifts. Experiments on synthetic and real-world datasets demonstrate that VARSHAP outperforms popular methods such as KernelSHAP or LIME, both quantitatively and qualitatively.
Since Faithfulness Fails: The Performance Limits of Neural Causal Discovery
Feb 22, 2025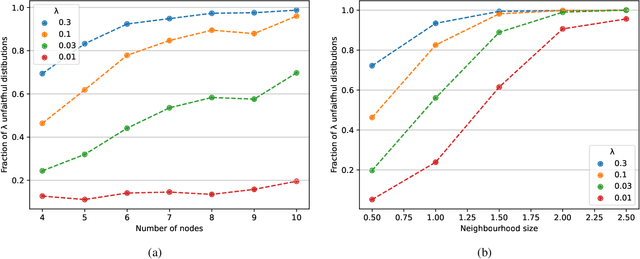



Neural causal discovery methods have recently improved in terms of scalability and computational efficiency. However, our systematic evaluation highlights significant room for improvement in their accuracy when uncovering causal structures. We identify a fundamental limitation: neural networks cannot reliably distinguish between existing and non-existing causal relationships in the finite sample regime. Our experiments reveal that neural networks, as used in contemporary causal discovery approaches, lack the precision needed to recover ground-truth graphs, even for small graphs and relatively large sample sizes. Furthermore, we identify the faithfulness property as a critical bottleneck: (i) it is likely to be violated across any reasonable dataset size range, and (ii) its violation directly undermines the performance of neural discovery methods. These findings lead us to conclude that progress within the current paradigm is fundamentally constrained, necessitating a paradigm shift in this domain.
Massively Multilingual Corpus of Sentiment Datasets and Multi-faceted Sentiment Classification Benchmark
Jun 13, 2023Despite impressive advancements in multilingual corpora collection and model training, developing large-scale deployments of multilingual models still presents a significant challenge. This is particularly true for language tasks that are culture-dependent. One such example is the area of multilingual sentiment analysis, where affective markers can be subtle and deeply ensconced in culture. This work presents the most extensive open massively multilingual corpus of datasets for training sentiment models. The corpus consists of 79 manually selected datasets from over 350 datasets reported in the scientific literature based on strict quality criteria. The corpus covers 27 languages representing 6 language families. Datasets can be queried using several linguistic and functional features. In addition, we present a multi-faceted sentiment classification benchmark summarizing hundreds of experiments conducted on different base models, training objectives, dataset collections, and fine-tuning strategies.
This is the way: designing and compiling LEPISZCZE, a comprehensive NLP benchmark for Polish
Nov 23, 2022The availability of compute and data to train larger and larger language models increases the demand for robust methods of benchmarking the true progress of LM training. Recent years witnessed significant progress in standardized benchmarking for English. Benchmarks such as GLUE, SuperGLUE, or KILT have become de facto standard tools to compare large language models. Following the trend to replicate GLUE for other languages, the KLEJ benchmark has been released for Polish. In this paper, we evaluate the progress in benchmarking for low-resourced languages. We note that only a handful of languages have such comprehensive benchmarks. We also note the gap in the number of tasks being evaluated by benchmarks for resource-rich English/Chinese and the rest of the world. In this paper, we introduce LEPISZCZE (the Polish word for glew, the Middle English predecessor of glue), a new, comprehensive benchmark for Polish NLP with a large variety of tasks and high-quality operationalization of the benchmark. We design LEPISZCZE with flexibility in mind. Including new models, datasets, and tasks is as simple as possible while still offering data versioning and model tracking. In the first run of the benchmark, we test 13 experiments (task and dataset pairs) based on the five most recent LMs for Polish. We use five datasets from the Polish benchmark and add eight novel datasets. As the paper's main contribution, apart from LEPISZCZE, we provide insights and experiences learned while creating the benchmark for Polish as the blueprint to design similar benchmarks for other low-resourced languages.
* 10 pages, 8 pages appendix
Punctuation Prediction in Spontaneous Conversations: Can We Mitigate ASR Errors with Retrofitted Word Embeddings?
Apr 13, 2020
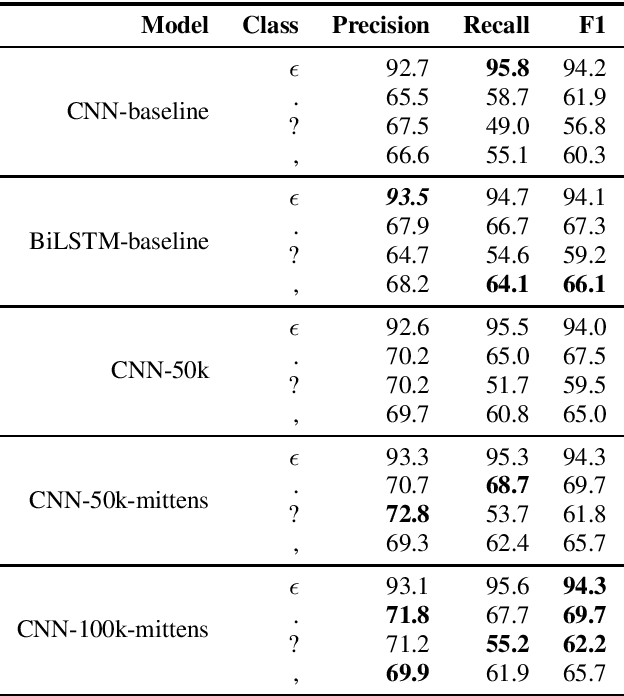
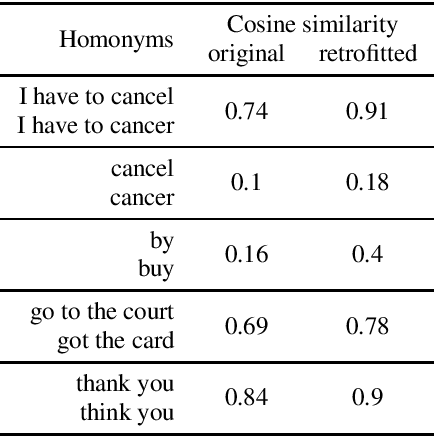

Automatic Speech Recognition (ASR) systems introduce word errors, which often confuse punctuation prediction models, turning punctuation restoration into a challenging task. These errors usually take the form of homonyms. We show how retrofitting of the word embeddings on the domain-specific data can mitigate ASR errors. Our main contribution is a method for better alignment of homonym embeddings and the validation of the presented method on the punctuation prediction task. We record the absolute improvement in punctuation prediction accuracy between 6.2% (for question marks) to 9% (for periods) when compared with the state-of-the-art model.
Avaya Conversational Intelligence: A Real-Time System for Spoken Language Understanding in Human-Human Call Center Conversations
Sep 02, 2019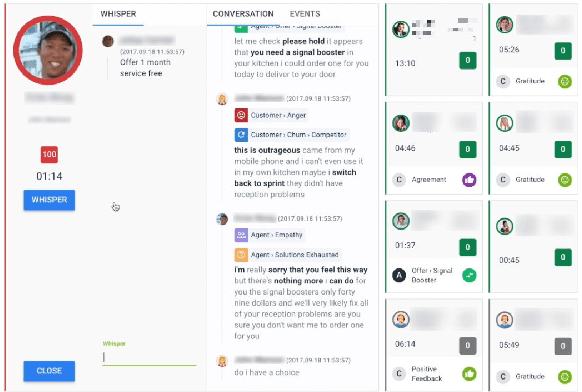

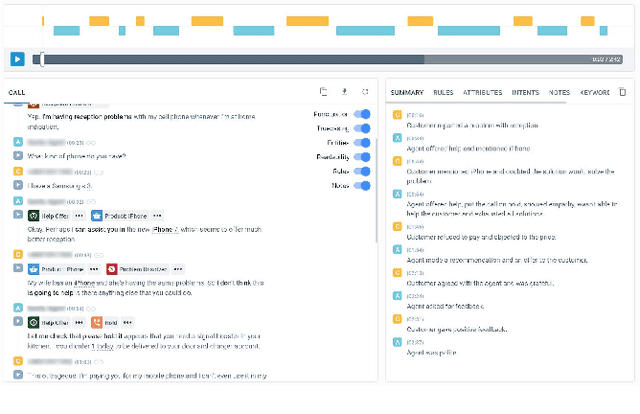
Avaya Conversational Intelligence(ACI) is an end-to-end, cloud-based solution for real-time Spoken Language Understanding for call centers. It combines large vocabulary, real-time speech recognition, transcript refinement, and entity and intent recognition in order to convert live audio into a rich, actionable stream of structured events. These events can be further leveraged with a business rules engine, thus serving as a foundation for real-time supervision and assistance applications. After the ingestion, calls are enriched with unsupervised keyword extraction, abstractive summarization, and business-defined attributes, enabling offline use cases, such as business intelligence, topic mining, full-text search, quality assurance, and agent training. ACI comes with a pretrained, configurable library of hundreds of intents and a robust intent training environment that allows for efficient, cost-effective creation and customization of customer-specific intents.
Towards Better Understanding of Spontaneous Conversations: Overcoming Automatic Speech Recognition Errors With Intent Recognition
Aug 21, 2019

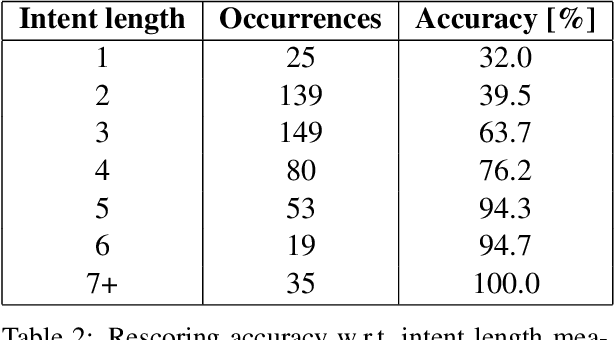

In this paper, we present a method for correcting automatic speech recognition (ASR) errors using a finite state transducer (FST) intent recognition framework. Intent recognition is a powerful technique for dialog flow management in turn-oriented, human-machine dialogs. This technique can also be very useful in the context of human-human dialogs, though it serves a different purpose of key insight extraction from conversations. We argue that currently available intent recognition techniques are not applicable to human-human dialogs due to the complex structure of turn-taking and various disfluencies encountered in spontaneous conversations, exacerbated by speech recognition errors and scarcity of domain-specific labeled data. Without efficient key insight extraction techniques, raw human-human dialog transcripts remain significantly unexploited. Our contribution consists of a novel FST for intent indexing and an algorithm for fuzzy intent search over the lattice - a compact graph encoding of ASR's hypotheses. We also develop a pruning strategy to constrain the fuzziness of the FST index search. Extracted intents represent linguistic domain knowledge and help us improve (rescore) the original transcript. We compare our method with a baseline, which uses only the most likely transcript hypothesis (best path), and find an increase in the total number of recognized intents by 25%.