 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRAI: Towards Standardization of Geospatial AI
Oct 23, 2023Spatial Representations for Artificial Intelligence (srai) is a Python library for working with geospatial data. The library can download geospatial data, split a given area into micro-regions using multiple algorithms and train an embedding model using various architectures. It includes baseline models as well as more complex methods from published works. Those capabilities make it possible to use srai in a complete pipeline for geospatial task solving. The proposed library is the first step to standardize the geospatial AI domain toolset. It is fully open-source and published under Apache 2.0 licence.
Massively Multilingual Corpus of Sentiment Datasets and Multi-faceted Sentiment Classification Benchmark
Jun 13, 2023Despite impressive advancements in multilingual corpora collection and model training, developing large-scale deployments of multilingual models still presents a significant challenge. This is particularly true for language tasks that are culture-dependent. One such example is the area of multilingual sentiment analysis, where affective markers can be subtle and deeply ensconced in culture. This work presents the most extensive open massively multilingual corpus of datasets for training sentiment models. The corpus consists of 79 manually selected datasets from over 350 datasets reported in the scientific literature based on strict quality criteria. The corpus covers 27 languages representing 6 language families. Datasets can be queried using several linguistic and functional features. In addition, we present a multi-faceted sentiment classification benchmark summarizing hundreds of experiments conducted on different base models, training objectives, dataset collections, and fine-tuning strategies.
Assessment of Massively Multilingual Sentiment Classifiers
Apr 11, 2022
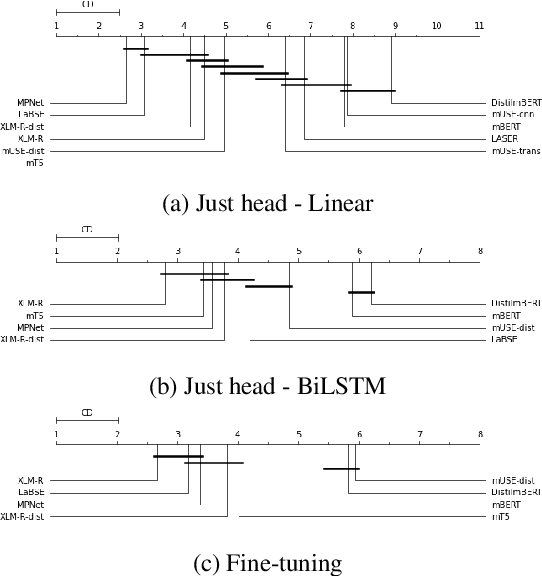
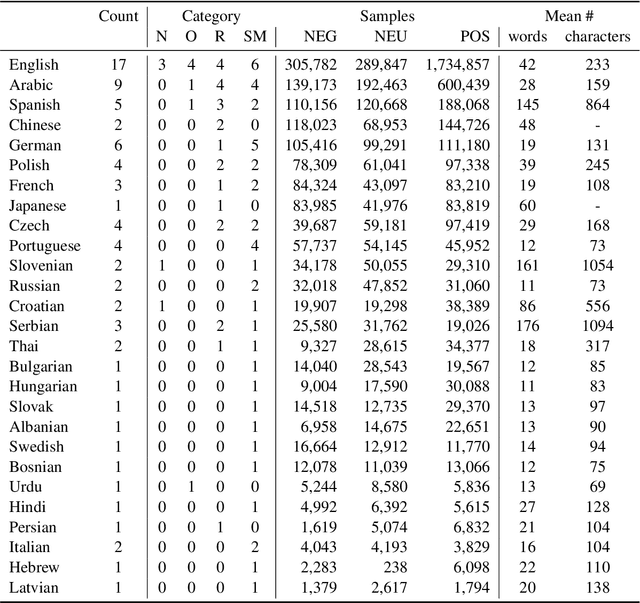
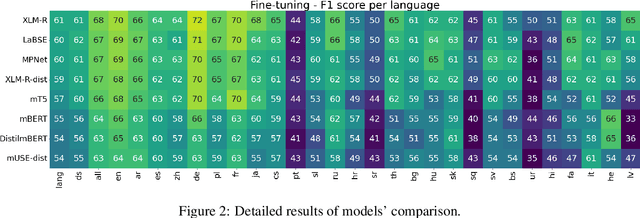
Models are increasing in size and complexity in the hunt for SOTA. But what if those 2\% increase in performance does not make a difference in a production use case? Maybe benefits from a smaller, faster model outweigh those slight performance gains. Also, equally good performance across languages in multilingual tasks is more important than SOTA results on a single one. We present the biggest, unified, multilingual collection of sentiment analysis datasets. We use these to assess 11 models and 80 high-quality sentiment datasets (out of 342 raw datasets collected) in 27 languages and included results on the internally annotated datasets. We deeply evaluate multiple setups, including fine-tuning transformer-based models for measuring performance. We compare results in numerous dimensions addressing the imbalance in both languages coverage and dataset sizes. Finally, we present some best practices for working with such a massive collection of datasets and models from a multilingual perspective.
gtfs2vec -- Learning GTFS Embeddings for comparing Public Transport Offer in Microregions
Nov 02, 2021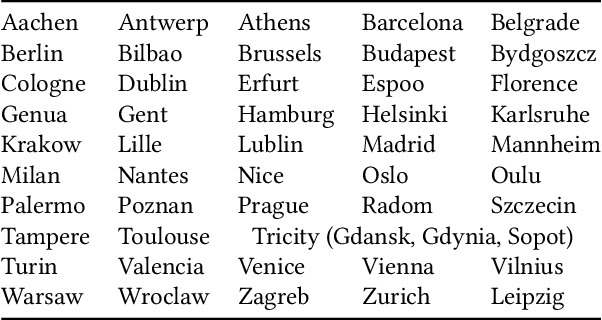

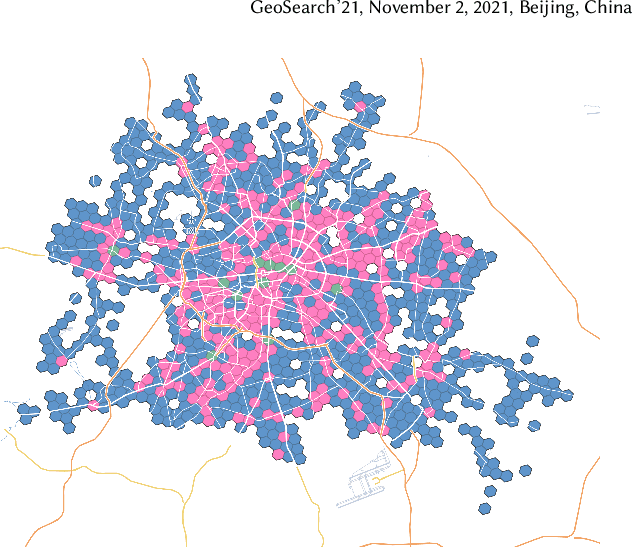
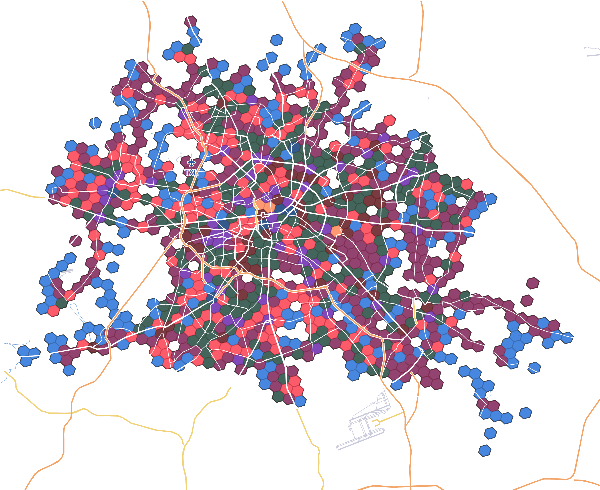
We selected 48 European cities and gathered their public transport timetables in the GTFS format. We utilized Uber's H3 spatial index to divide each city into hexagonal micro-regions. Based on the timetables data we created certain features describing the quantity and variety of public transport availability in each region. Next, we trained an auto-associative deep neural network to embed each of the regions. Having such prepared representations, we then used a hierarchical clustering approach to identify similar regions. To do so, we utilized an agglomerative clustering algorithm with a euclidean distance between regions and Ward's method to minimize in-cluster variance. Finally, we analyzed the obtained clusters at different levels to identify some number of clusters that qualitatively describe public transport availability. We showed that our typology matches the characteristics of analyzed cities and allows succesful searching for areas with similar public transport schedule characteristics.
Hex2vec -- Context-Aware Embedding H3 Hexagons with OpenStreetMap Tags
Nov 01, 2021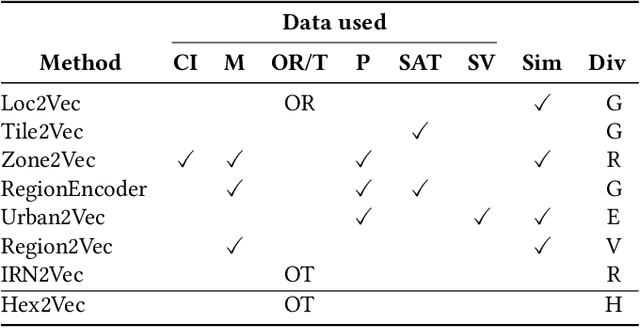
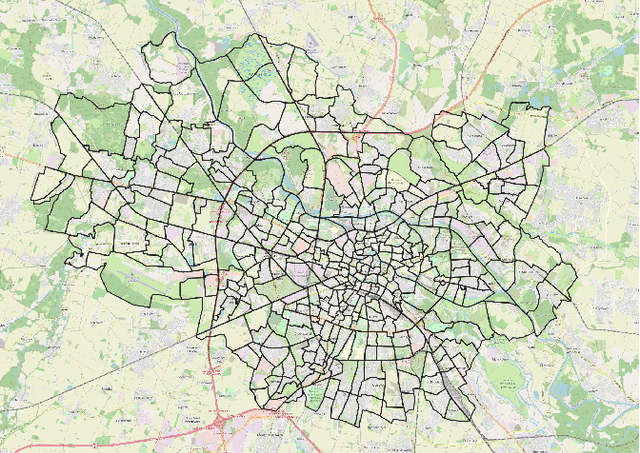
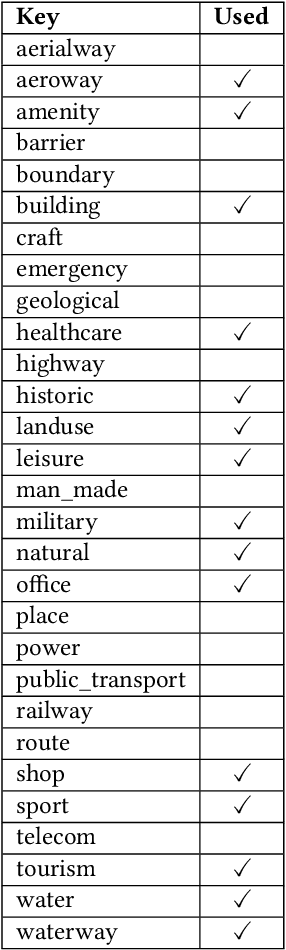
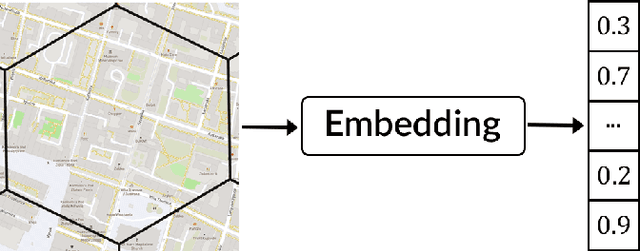
Representation learning of spatial and geographic data is a rapidly developing field which allows for similarity detection between areas and high-quality inference using deep neural networks. Past approaches however concentrated on embedding raster imagery (maps, street or satellite photos), mobility data or road networks. In this paper we propose the first approach to learning vector representations of OpenStreetMap regions with respect to urban functions and land-use in a micro-region grid. We identify a subset of OSM tags related to major characteristics of land-use, building and urban region functions, types of water, green or other natural areas. Through manual verification of tagging quality, we selected 36 cities were for training region representations. Uber's H3 index was used to divide the cities into hexagons, and OSM tags were aggregated for each hexagon. We propose the hex2vec method based on the Skip-gram model with negative sampling. The resulting vector representations showcase semantic structures of the map characteristics, similar to ones found in vector-based language models. We also present insights from region similarity detection in six Polish cities and propose a region typology obtained through agglomerative clustering.