 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping the Technological Future: A Topic, Sentiment, and Emotion Analysis in Social Media Discourse
Jul 20, 2024People worldwide are currently confronted with a number of technological challenges, which act as a potent source of uncertainty. The uncertainty arising from the volatility and unpredictability of technology (such as AI) and its potential consequences is widely discussed on social media. This study uses BERTopic modelling along with sentiment and emotion analysis on 1.5 million tweets from 2021 to 2023 to identify anticipated tech-driven futures and capture the emotions communicated by 400 key opinion leaders (KOLs). Findings indicate positive sentiment significantly outweighs negative, with a prevailing dominance of positive anticipatory emotions. Specifically, the 'Hope' score is approximately 10.33\% higher than the median 'Anxiety' score. KOLs emphasize 'Optimism' and benefits over 'Pessimism' and challenges. The study emphasizes the important role KOLs play in shaping future visions through anticipatory discourse and emotional tone during times of technological uncertainty.
Electoral Agitation Data Set: The Use Case of the Polish Election
Jul 13, 2023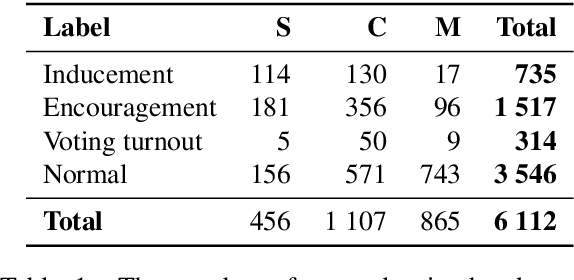
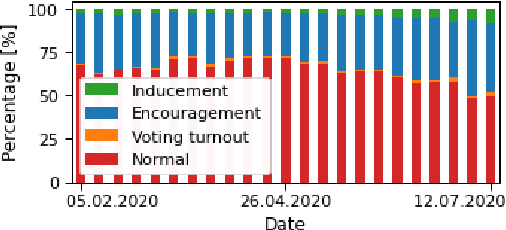
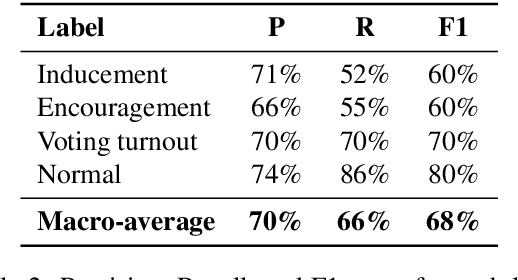
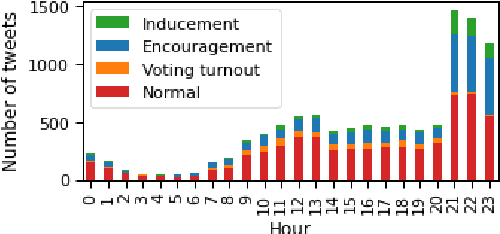
The popularity of social media makes politicians use it for political advertisement. Therefore, social media is full of electoral agitation (electioneering), especially during the election campaigns. The election administration cannot track the spread and quantity of messages that count as agitation under the election code. It addresses a crucial problem, while also uncovering a niche that has not been effectively targeted so far. Hence, we present the first publicly open data set for detecting electoral agitation in the Polish language. It contains 6,112 human-annotated tweets tagged with four legally conditioned categories. We achieved a 0.66 inter-annotator agreement (Cohen's kappa score). An additional annotator resolved the mismatches between the first two improving the consistency and complexity of the annotation process. The newly created data set was used to fine-tune a Polish Language Model called HerBERT (achieving a 68% F1 score). We also present a number of potential use cases for such data sets and models, enriching the paper with an analysis of the Polish 2020 Presidential Election on Twitter.
Massively Multilingual Corpus of Sentiment Datasets and Multi-faceted Sentiment Classification Benchmark
Jun 13, 2023Despite impressive advancements in multilingual corpora collection and model training, developing large-scale deployments of multilingual models still presents a significant challenge. This is particularly true for language tasks that are culture-dependent. One such example is the area of multilingual sentiment analysis, where affective markers can be subtle and deeply ensconced in culture. This work presents the most extensive open massively multilingual corpus of datasets for training sentiment models. The corpus consists of 79 manually selected datasets from over 350 datasets reported in the scientific literature based on strict quality criteria. The corpus covers 27 languages representing 6 language families. Datasets can be queried using several linguistic and functional features. In addition, we present a multi-faceted sentiment classification benchmark summarizing hundreds of experiments conducted on different base models, training objectives, dataset collections, and fine-tuning strategies.
Assessment of Massively Multilingual Sentiment Classifiers
Apr 11, 2022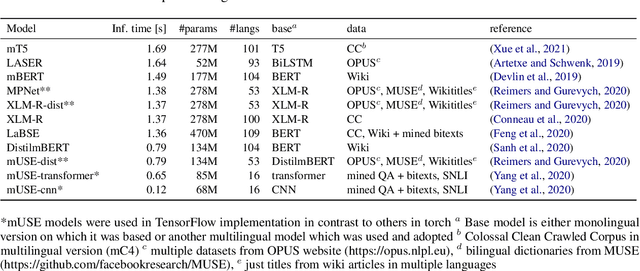
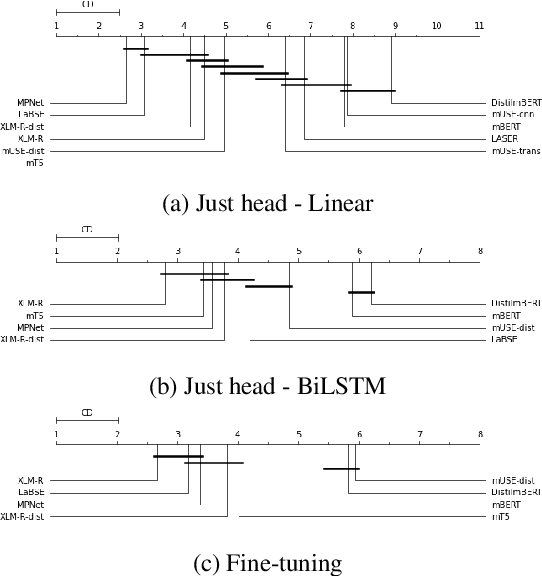
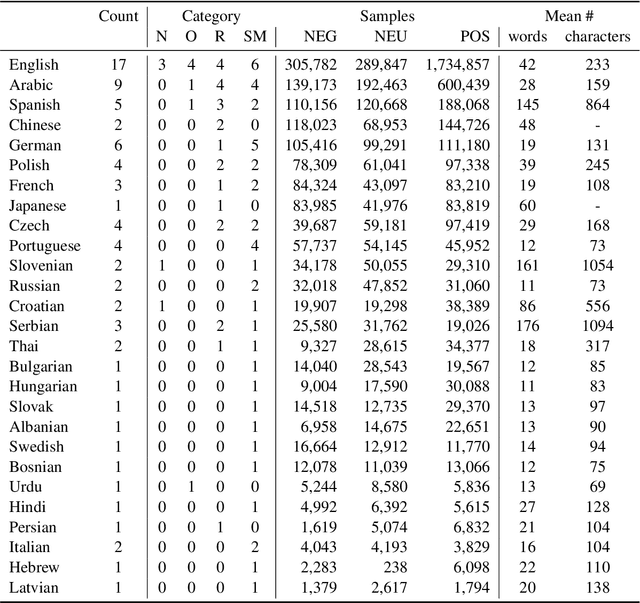
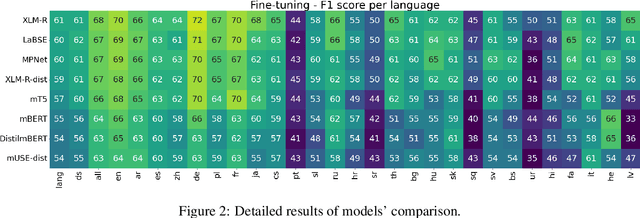
Models are increasing in size and complexity in the hunt for SOTA. But what if those 2\% increase in performance does not make a difference in a production use case? Maybe benefits from a smaller, faster model outweigh those slight performance gains. Also, equally good performance across languages in multilingual tasks is more important than SOTA results on a single one. We present the biggest, unified, multilingual collection of sentiment analysis datasets. We use these to assess 11 models and 80 high-quality sentiment datasets (out of 342 raw datasets collected) in 27 languages and included results on the internally annotated datasets. We deeply evaluate multiple setups, including fine-tuning transformer-based models for measuring performance. We compare results in numerous dimensions addressing the imbalance in both languages coverage and dataset sizes. Finally, we present some best practices for working with such a massive collection of datasets and models from a multilingual perspective.
Political Advertising Dataset: the use case of the Polish 2020 Presidential Elections
Jun 17, 2020
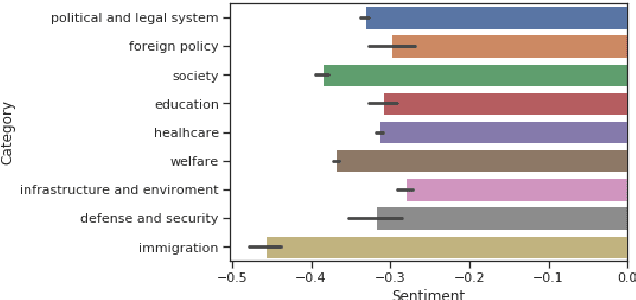
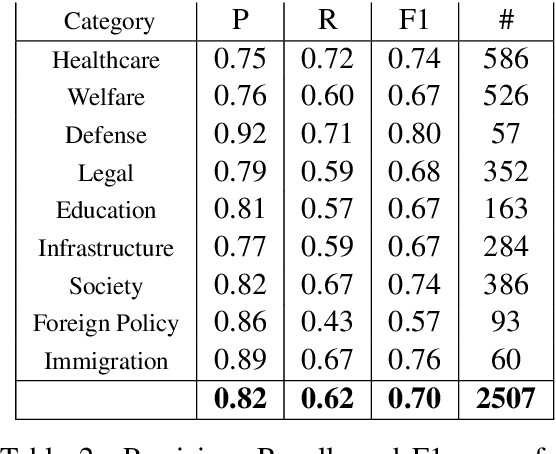
Political campaigns are full of political ads posted by candidates on social media. Political advertisements constitute a basic form of campaigning, subjected to various social requirements. We present the first publicly open dataset for detecting specific text chunks and categories of political advertising in the Polish language. It contains 1,705 human-annotated tweets tagged with nine categories, which constitute campaigning under Polish electoral law. We achieved a 0.65 inter-annotator agreement (Cohen's kappa score). An additional annotator resolved the mismatches between the first two annotators improving the consistency and complexity of the annotation process. We used the newly created dataset to train a well established neural tagger (achieving a 70% percent points F1 score). We also present a possible direction of use cases for such datasets and models with an initial analysis of the Polish 2020 Presidential Elections on Twitter.
Method for Aspect-Based Sentiment Annotation Using Rhetorical Analysis
Sep 13, 2017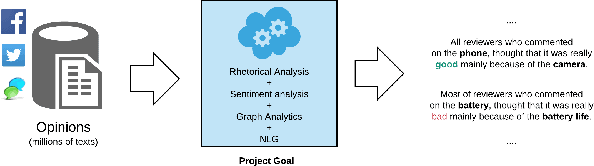
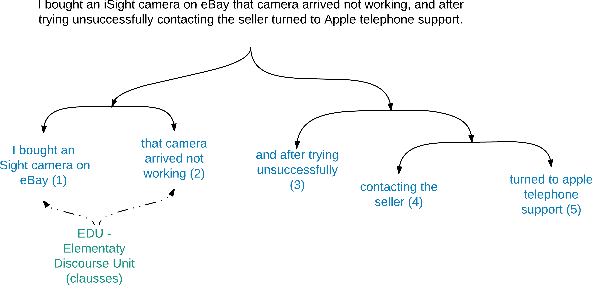
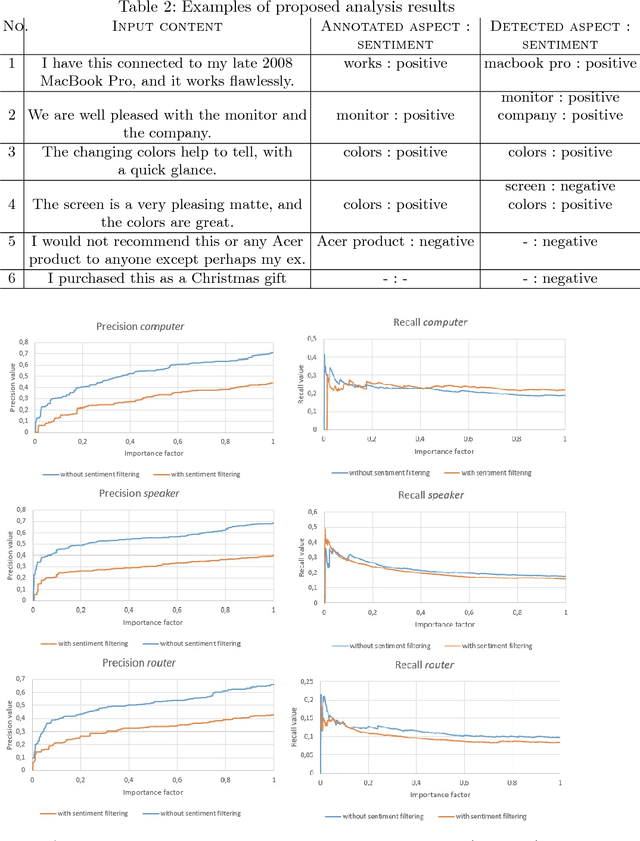

This paper fills a gap in aspect-based sentiment analysis and aims to present a new method for preparing and analysing texts concerning opinion and generating user-friendly descriptive reports in natural language. We present a comprehensive set of techniques derived from Rhetorical Structure Theory and sentiment analysis to extract aspects from textual opinions and then build an abstractive summary of a set of opinions. Moreover, we propose aspect-aspect graphs to evaluate the importance of aspects and to filter out unimportant ones from the summary. Additionally, the paper presents a prototype solution of data flow with interesting and valuable results. The proposed method's results proved the high accuracy of aspect detection when applied to the gold standard dataset.